先日、個人的にAmazon Elasticsearch Service で _ingest と _bulk API を使ってインデクシングして Kibana で可視化する | shinodogg.comというブログを書きましたが、色々シリアルだし、せっかくだったらサーバーレスにしたいな、ということで、これまた個人的にやってみました。
なんというか、こういう風に使ってみると、昔Javaでマルチスレッドなバッチを書いて、レビューで”ココってスレッドセーフじゃないですよねー?”とかって突っ込まれるような危ない橋を渡るより(テストで気づきにくい)、Lambdaファンクション複数立ち上げちゃった方が楽チンでイイわぁ〜と改めて実感したりするものです。
大まかなアーキテクチャ
使うログデータ
NASA-HTTPのWebサイトで公開されている、1995年の7月のデータ(Jul 01 to Jul 31, ASCII format, 20.7 MB gzip compressed)と8月のデータ(Aug 04 to Aug 31, ASCII format, 21.8 MB gzip compressed)を使います。
Apacheのログになりますが、データの詳細は、それなりの時系列ログデータが欲しい時 | shinodogg.comを参照ください。
Lambdaファンクション
Lambdaファンクションは最長で5分という制約があるため、並列化と時間短縮を図るため以下のような流れにします。
1. NASA-HTTPのWebサイトからFTPでgzファイルをダウンロードして、
2MBずつに分割してS3に配置するLambdaファンクション。
7月分と8月分それぞれにLambdaファンクションを起動して並列に処理を行う。
(3MBだと5分を超えてしまいそうなものもあったので念の為2MBにしました)
2. 1つのLambdaファンクションから、上記1.で分割配置されたファイルの数だけ、
Lambdaファンクションを起動してAmazon ESにデータを送信する
今回は気分的にPythonでコードを書くことにしました。いっぱい日本語のコメント付けてるので、それぞれ最初に『# coding:utf-8』を付けてあげます。
Step Functionsで処理を実行
上記のLambdaファンクションをStep Functionsから以下のように起動します。
7月分と8月分のログをそれぞれパラレルでダウンロードして分割します。分割したファイルの並列実行はStep Functionsではなく、Lambdaファンクションの処理ループの中で、それぞれのLambdaファンクションを非同期で呼び出すことにしました(つまり、ワークフローは全体の処理終了と一致するわけではないです)。
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
NASA-HTTPからダウンロード⇒ファイル分割⇒S3に配置するLambdaファンクション
変数諸々。
# S3に配置する際のバケット名とダウンロードしてくるファイル名 # および後続処理で使うAmazonESのエンドポイントを # Step FunctionsのInputPathを使って、eventから取得 bucket_name = event['bucket_name'] file_name = event['file_name'] amazon_es_endpoint = event['amazon_es_endpoint'] print bucket_name print file_name print amazon_es_endpoint # ファイルの一時置き場として/tmpを使う # gzを展開する時の名前は".gz"を取り除く gzip_file_path = '/tmp/' + file_name file_path = gzip_file_path[:-3] print gzip_file_path print file_path
NASA-HTTPのファイルをFTPでダウンロード。Lambdaファンクションのインスタンスは再利用されることがあるので(https://aws.amazon.com/jp/lambda/faqs/ の Q: AWS Lambda は関数インスタンスを再利用しますか?)、お掃除してから配置します。
# 同じコンテナが使い回されることもあるのでお掃除
commands.getoutput("rm -rf /tmp/*")
# NASA-HTTPのファイルを/tmpにFTPで配置
ftp = FTP()
ftp.connect(host='ita.ee.lbl.gov')
ftp.login(user='anonymous', passwd="")
ftp.set_pasv(True)
ftp.retrbinary("RETR /traces/" + file_name, open(gzip_file_path, 'wb').write)
OSコマンドでダウンロードしたファイルを2MBずつに分割。Pythonで高速なファイル分割のコードが書けないか、数時間Stack Overflowを検索してコピペしながら試してみたのですが、splitコマンドの方が全然早かった…(;・∀・)
# gzipファイルを解凍解凍して2MBごとに分割
commands.getoutput("gzip -d " + gzip_file_path)
commands.getoutput("split -b 2m " + file_path + " " + file_path + "-")
print commands.getoutput("ls -la /tmp")
分割したファイルをそれぞれS3にアップロード。/tmpにゴミがあるかもしれないので、lsでそれっぽいファイル名のものだけを対象に。
# 分割したファイルをS3バケットにアップロード
file_list = commands.getoutput("ls " + file_path + "-*").split("n")
s3 = boto3.resource('s3')
bucket = s3.Bucket(bucket_name)
for split_file in file_list:
bucket.upload_file(split_file, os.path.basename(split_file))
Step Functionsで次の処理にデータを渡す用途でreturnはS3のバケット名を返す。今回は同じLambdaファンクションが並列に2回呼ばれるので、[JSON文字列,JSON文字列]みたいな配列が渡されてしまい、ちょっと不格好ですが…
# Step Functionsの後続処理のInputPath用にS3バケット名とAmazonESのエンドポイント
return "{"bucket_name":"" + bucket_name + "", "amazon_es_endpoint":"" + amazon_es_endpoint + ""}"
S3に分割配置されたファイルを元にAmazon ESに送信するLambdaファンクションを起動
S3のバケット名をStep FunctionsのInputPathで渡された名前。前述のようにパラレル実行すると配列で(ry
# 前処理から引き継いだ値。パラレル実行の場合 # [JSON文字列,JSON文字列]のような配列になるため1つ目の要素だけ利用 input_path = event[0] input_json = json.loads(input_path) bucket_name = input_json['bucket_name'] amazon_es_endpoint = input_json['amazon_es_endpoint'] print bucket_name print amazon_es_endpoint
S3バケットからファイルのリストを取得
# S3から対象ファイル対象ファイルのリストを取得
s3 = boto3.resource('s3')
bucket = s3.Bucket(bucket_name)
objects = bucket.objects.all()
prefix = "NASA_access_log_"
対象ファイル分ループを回してLambdaファンクションを起動
lambdaClient = boto3.client('lambda')
for object in objects:
file = object.key
# 想定ファイルだけ処理処理対象
if file.startswith(prefix):
print file
# 処理対象ファイルとS3のバケット名とAmazonESのエンドポイントをLambdaファンクションに渡す
payload = "{"file_name": "" + file + "", "bucket_name": "" + bucket_name + "", "amazon_es_endpoint": "" + amazon_es_endpoint + ""}"
print payload
lambdaClient.invoke(
FunctionName="nasa-http_send",
# Eventにすることで非同期実行
InvocationType="Event",
Payload=payload
)
# Lambdaの同時起動制限にひっかからないように…
time.sleep(0.5)
S3バケットにあるファイルをAmazon ESに送信するLambdaファンクション
変数諸々。前処理のPayloadで指定された値の受取りとゴミ掃除
# 前処理のPayloadに指定されたS3バケット名と処理対象ファイル名とAmazonESのエンドポイント
bucket_name = event['bucket_name']
file_name = event['file_name']
amazon_es_endpoint = event['amazon_es_endpoint']
print bucket_name
print file_name
print amazon_es_endpoint
# /tmpにダウンロードして処理を行う。念の為ゴミ掃除も
file_path = "/tmp/" + file_name
commands.getoutput("rm -rf /tmp/*")
S3からファイルを/tmpにダウンロードして開く
# S3からファイルをファイルをダウンロードして開く
s3 = boto3.resource('s3')
s3.Bucket(bucket_name).download_file(file_name, file_path)
file = open(file_path, 'rb')
ファイルを読み込んでAmazonES連携用JSONを作る。(bulkでAmazon ESに送信する詳細に関しては Amazon Elasticsearch Service で _ingest と _bulk API を使ってインデクシングして Kibana で可視化する | shinodogg.com を参照ください)
# ループカウンタとAmazonESに連携するJSON文字列用の変数
i = 0
jsonstring = ""
# 1行ずつ読んでAmazonES連携用のデータを作成
line = file.readline()
while line:
meta = "{"index": {"_index":"nasa-logs-", "_type":"nasa-http"}} n"
dict = {"message": line}
try:
jsonstring = jsonstring + meta + json.dumps(dict) + "n"
except UnicodeDecodeError:
print line
line = file.readline()
i += 1
# 何件処理したか出力して開いたファイルを閉じる
print i
file.close()
Signature Version 4でAmazon ESにデータを送る。(Amazon ES側でLambdaファンクションに設定されたIAM Roleの権限を許可する)
# バージョン 4 署名リクエスト credentials = Credentials(os.environ["AWS_ACCESS_KEY_ID"], os.environ["AWS_SECRET_ACCESS_KEY"], os.environ["AWS_SESSION_TOKEN"]) request = AWSRequest(method="POST", url=amazon_es_endpoint + "/_bulk?pipeline=nasa-http", data=jsonstring) SigV4Auth(credentials, "es", os.environ["AWS_REGION"]).add_auth(request) BotocoreHTTPSession().send(request.prepare())
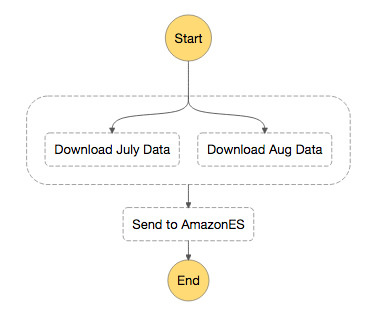
Step Functionの定義と実行時のインプット
上記の図のようにParallelで並列実行後にAmazon ESにデータを送るLambdaファンクションを呼び出す。
{
"Comment": "download Apache log files from nasa-http, and send to AmazonES",
"StartAt": "Parallel",
"States": {
"Parallel": {
"Type": "Parallel",
"Next": "Send to AmazonES",
"Branches": [
{
"StartAt": "Download July Data",
"States": {
"Download July Data": {
"Type": "Task",
"InputPath": "$.july",
"Resource": "arn:aws:lambda:ap-northeast-1:xxx:function:nasa-http_download",
"End": true
}
}
},
{
"StartAt": "Download Aug Data",
"States": {
"Download Aug Data": {
"Type": "Task",
"InputPath": "$.aug",
"Resource": "arn:aws:lambda:ap-northeast-1:xxx:function:nasa-http_download",
"End": true
}
}
}
]
},
"Send to AmazonES": {
"Type": "Task",
"InputPath": "$",
"Resource": "arn:aws:lambda:ap-northeast-1:xxx:function:nasa-http_invoke",
"End": true
}
}
}
Parallel 部分の InputPath の $.july とか $.aug に関しては、Step Functions を実行する際に以下のようなJSONを渡す形。今思えば、S3バケット名とAmazon ESのエンドポイントは共通なのだから別定義にして、InputPathは $ でズゴっと渡してLambdaファンクションの中でホゲホゲすればよかったのかな…。
{
"july" : {
"bucket_name": "S3バケット名",
"file_name": "NASA_access_log_Jul95.gz",
"amazon_es_endpoint": "https://search-demo-xxx.ap-northeast-1.es.amazonaws.com"
},
"aug" : {
"bucket_name": "S3バケット名",
"file_name": "NASA_access_log_Aug95.gz",
"amazon_es_endpoint": "https://search-demo-xxx.ap-northeast-1.es.amazonaws.com"
}
}
Amazon ESのingestパイプラインとテンプレートのmapping
ingestパイプラインの詳細にについては Amazon Elasticsearch Service で _ingest と _bulk API を使ってインデクシングして Kibana で可視化する | shinodogg.com に記載しましたが、今回も前回と同様に。
PUT _ingest/pipeline/nasa-http
{
"description": "nasa-http",
"processors": [
{
"grok": {
"field": "message",
"patterns": ["%{COMMONAPACHELOG}"]
}
},
{
"date": {
"field": "timestamp",
"formats" : ["dd/MMM/yyyy:HH:mm:ss Z"]
}
},
{
"date_index_name": {
"field": "@timestamp",
"index_name_prefix": "nasa-logs-",
"date_rounding": "d"
}
}
]
}
また、今回はデータ量も少ないし、Kibanaで可視化するだけなので、各フィールドのAnalyzeは必要ない、ということで、nasa-logs〜っていうインデックスに関しては以下のような感じで。
・シャード数は1つだけ(Amazon ESでのシャード見積もりに関しては Amazon Elasticsearch Service をはじめよう: シャード数の算出方法 を参照)
・基本的にkeyword(Elasticsearchバージョン5になってからstringは、textとkeywordに分かれました。textはAnalyzeするやつで、keywordはそうじゃないヤツ、といった扱い。ES5.2からはkeywordにnormalizerの定義が出来るようになったりしています)
PUT _template/nasa-http
{
"template": "nasa-logs*",
"settings": {
"number_of_shards": 1
},
"mappings": {
"type1": {
"_source": {
"enabled": false
},
"properties": {
"@timestamp": {
"type": "date"
},
"auth": {
"type": "keyword"
},
"bytes": {
"type": "keyword"
},
"clientip": {
"type": "keyword"
},
"httpversion": {
"type": "keyword"
},
"ident": {
"type": "keyword"
},
"message": {
"type": "keyword"
},
"rawrequest": {
"type": "keyword"
},
"request": {
"type": "keyword"
},
"response": {
"type": "keyword"
},
"timestamp": {
"type": "keyword"
},
"verb": {
"type": "keyword"
}
}
}
}
}
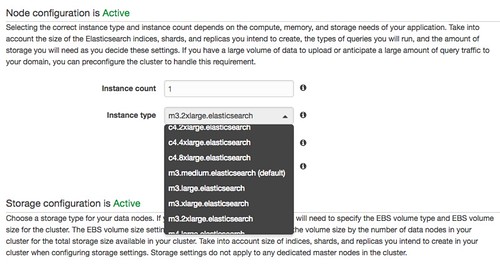
Amazon Elasticsearch Serviceのインスタンス
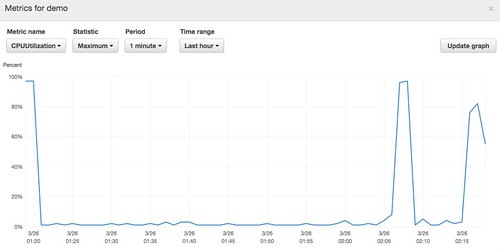
何回か処理を流してみたところ、そこそこCPU使ってるのでm3.2xlargeを1インスタンスにしました。
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
c4でも良かったのですが、その場合はEBSの設定が必要になります。初期投入だけはCPU使うけどそれ以降はそうでもない、、とか、やっていく中でワークロードは変わってくると思うので、その辺を柔軟にチャチャッと構成変更できるという点でAmazonESは楽チンですね。(構成変更や権限変更にかかる時間の短縮化は今後に期待です。というか、IAMとか今回の権限周りはまた別途…)
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
今回の処理結果
ということで、Step Functionsで処理が完了して、
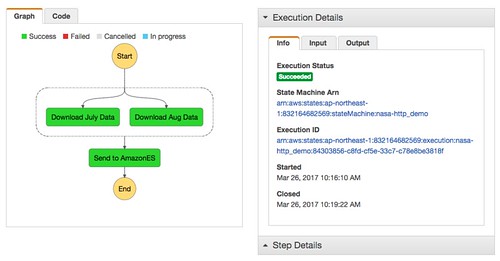 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
投入したデータをKibanaから見れるようになりました。
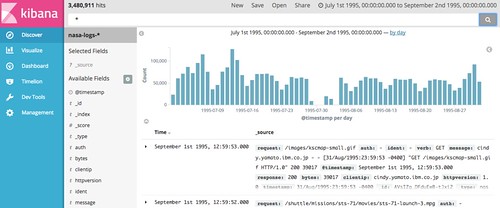 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js

マイナビ出版 (2016-06-10)
売り上げランキング: 20,685


コメント