先日、Amazon Elasticsearch Service で、Elasticsearch 5.1 がサポートされました。
[youtube https://www.youtube.com/watch?v=QBwmVGlMOZU&w=560&h=315]
Elasticsearch 5 now available on Amazon Elasticsearch Service
[slideshare id=HJRjQ0uGUaQJQI&w=595&h=485&fb=0&mw=0&mh=0&style=border:1px solid #CCC; border-width:1px; margin-bottom:5px; max-width: 100%;&sc=no]
Elasticsearch 5で追加された目玉機能の一つとして、Ingest Nodeが挙げられると思います。
今までインデクシングする前段で構造化するための変換処理的なところをLogStashで行うケースが多かったものが、Elasticsearchの中で出来るようになった、と。
以前 それなりの時系列ログデータが欲しい時 | shinodogg.com というエントリにも書いた、NASA-HTTPのデータを使ったKibanaのデモというかハンズオン資料があるのですが、そのELKスタックも今回のリリースで少し古い感じになってきたので、アップデートを兼ねてIngest Nodeを使ってみることにしました。
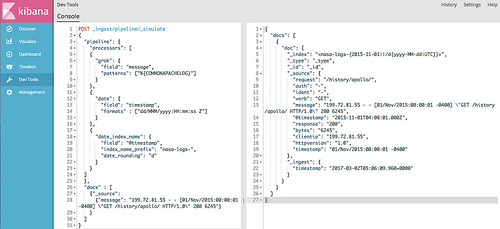
_ingest APIを使ったシミュレーション
コレ系の操作はKibanaのDev Toolsから。
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
_ingest APIにはシミュレートする機能があり、今回はNASA-HTTPで使われているApacheのログ形式に合わせて、messageというフィールドに %{COMMONAPACHELOG} 形式のデータが入ってきたら〜という形にします。
COMMONAPACHELOGに関しては↓のGrok Patternsにある、
https://github.com/elastic/elasticsearch/blob/master/modules/ingest-common/src/main/resources/patterns/grok-patterns
↓のような定義になっています。(こういうのをイチイチ自分でやるのメンドイので嬉しいですね)
%{IPORHOST:clientip} %{HTTPDUSER:ident} %{USER:auth} [%{HTTPDATE:timestamp}] "(?:%{WORD:verb} %{NOTSPACE:request}(?: HTTP/%{NUMBER:httpversion})?|%{DATA:rawrequest})" %{NUMBER:response} (?:%{NUMBER:bytes}|-)
COMBINEDAPACHELOG %{COMMONAPACHELOG} %{QS:referrer} %{QS:agent}
HTTPD20_ERRORLOG [%{HTTPDERROR_DATE:timestamp}] [%{LOGLEVEL:loglevel}] (?:[client %{IPORHOST:clientip}] ){0,1}%{GREEDYDATA:errormsg}
更に、dateプロセッサーで、現在日付ではなく、ログの中にある日付を @timestamp にするようにして、
"date": {
"field": "timestamp",
"formats" : ["dd/MMM/yyyy:HH:mm:ss Z"]
}
date_index_name プロセッサーで、日付毎に nasa-logs-YYYY-MM-DD という形式でインデックスが作れるようにします。
"date_index_name": {
"field": "@timestamp",
"index_name_prefix": "nasa-logs-",
"date_rounding": "d"
}
以下のようなデータを食わせて、結果を見てみると、
"docs" : [
{"_source":
{"message": "199.72.81.55 - - [01/Nov/2015:00:00:01 -0400] "GET /history/apollo/ HTTP/1.0" 200 6245"}
}
]
↓のようにイイ感じになりました 🙂
{
"docs": [
{
"doc": {
"_index": "",
"_type": "_type",
"_id": "_id",
"_source": {
"request": "/history/apollo/",
"auth": "-",
"ident": "-",
"verb": "GET",
"message": "199.72.81.55 - - [01/Nov/2015:00:00:01 -0400] "GET /history/apollo/ HTTP/1.0" 200 6245",
"@timestamp": "2015-11-01T04:00:01.000Z",
"response": "200",
"bytes": "6245",
"clientip": "199.72.81.55",
"httpversion": "1.0",
"timestamp": "01/Nov/2015:00:00:01 -0400"
},
"_ingest": {
"timestamp": "2017-03-02T05:06:09.960+0000"
}
}
}
]
}
_ingest APIを使ったパイプラインの設定
シミュレーションした内容をそのまま設定してやる感じ。
これもKibana上で↓のように。_ingest/pipeline/パイプライン名
PUT _ingest/pipeline/nasa-http
{
"description": "nasa-http",
"processors": [
{
"grok": {
"field": "message",
"patterns": ["%{COMMONAPACHELOG}"]
}
},
{
"date": {
"field": "timestamp",
"formats" : ["dd/MMM/yyyy:HH:mm:ss Z"]
}
},
{
"date_index_name": {
"field": "@timestamp",
"index_name_prefix": "nasa-logs-",
"date_rounding": "d"
}
}
]
}
GET _ingest/pipeline/nasa-http してやると、登録されたパイプラインの情報が確認できます
{
"nasa-http": {
"description": "nasa-http",
"processors": [
{
"grok": {
"field": "message",
"patterns": [
"%{COMMONAPACHELOG}"
]
}
},
{
"date": {
"field": "timestamp",
"formats": [
"dd/MMM/yyyy:HH:mm:ss Z"
]
}
},
{
"date_index_name": {
"field": "@timestamp",
"index_name_prefix": "nasa-logs-",
"date_rounding": "d"
}
}
]
}
}
Pythonのスクリプトを使って _bulk APIでデータを登録
やることは以下。
# 本当はAWS Lambdaで/tmp使ってやろうと思ったけど、時間かかって5分で収まらなかったのでEC2で…
# StepFunctions使ってホゲホゲとかやっても良いかなぁ〜
gzをダウンロードして、
ftp = FTP()
ftp.connect(host='ita.ee.lbl.gov')
ftp.login(user='anonymous', passwd="")
ftp.set_pasv(True)
ftp.retrbinary("RETR /traces/NASA_access_log_Jul95.gz", open('【ダウンロード先】/NASA_access_log_Jul95.gz', 'wb').write)
ftp.retrbinary("RETR /traces/NASA_access_log_Aug95.gz", open('【ダウンロード先】/NASA_access_log_Aug95.gz', 'wb').write)
gzを開いて行ごとに読み込んで
for file in glob.glob('【ダウンロード先】/*'):
f = gzip.open(file)
session = requests.Session()
line = f.readline()
メタデータとコンテンツのJSONを作ってPOSTで送信。
# 1万件で1回送信なのでrequests.Sessionがどれだけ効くのかはアレですが、、、
meta = "{"index": {"_index":"nasa-logs-", "_type":"nasa-http"}} n"
jsonstring = ""
while line:
i += 1
line = f.readline()
dict = {"message": line}
try:
jsonstring = jsonstring + meta + json.dumps(dict) + "n"
if i % 10000 == 1:
r = session.post("https://AmazonESのエンドポイント/_bulk?pipeline=nasa-http", data=jsonstring)
print r.status_code
jsonstring = ""
except UnicodeDecodeError:
print line
当初は_bulkを使わずに1件1件↓のようにインデクシングしてたのですが、なかなか終わらず、、、
requests.post("https://AmazonESのエンドポイント/nasa-logs-/nasa-http/?pipeline=nasa-http", data=jsonstring)
マニュアル(https://www.elastic.co/guide/en/elasticsearch/reference/5.1/docs-bulk.html)みたら直感的にメタデータ+実データの組み合わせを作って突っ込むだけだったので(とは言え、改行コード入れてなくて”no requests added”ってエラーが出てStackOverFlowみたりしたけど…)、サクっと出来ました。
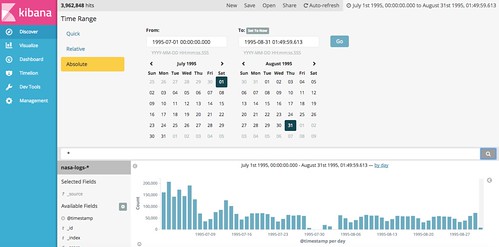
Kibanaで可視化
Kibanaからデータが見れるようになったので、
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
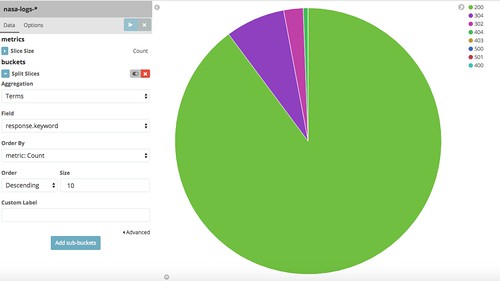
例えば、HTTPのレスポンスコードでパイチャート作ったりできたりします 🙂
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js

コメント