
こちらはAlgoliaのCrawlerチームのソフトウェアエンジニアのSamuel Bodinが書いた 30 days to improve our Crawler performance by 50% の翻訳記事です。
2020年の夏、私たちはNetlifyと連絡を取っていました。私たちはより近い関係性を築いて協力し合いたいと考えていて、Netlifyは私たちに、Netlify上で稼働するウェブサイトに検索機能を追加するオフィシャルなインテグレーションを構築することを提案しました。
言うのは簡単ではありますが、この時、私たちはAlgolia Crawlerがこれに対するパーフェクトなソリューションであるということに直ぐに気が付きました。私たちのカスタムクローラーは2年以上前にサービスをはじめてから大きな成長を遂げてきました。ローカルホストで稼働させたMVP(Minimum Viable Product)からHeroku、そしてGKEへのチャレンジングなマイグレーションへとクローラーは大きな変貌を遂げ、私たちのエンタープライズ顧客の着実な成長を目の当たりにしてきました。
技術的にはこの2年間に渡って磨きをかけてきたので、心配はしていませんでしたが、パフォーマンスに関してはいくつか不安な点がありました: 元々、私たちによって管理されているお客様の数から、ユーザー数が青天井であるセルフサービスに移行するということは全くことなるボールゲームと言えると思います。つまり、”これだけの人が登録するのでシステム負荷がこの程度になる”と予測するのが難しい、ということです – 私たちはおおよそこれくらい、、といった推定のレンジを持ってはいましたが、それだけでした。そのため、ローンチをする日(2020年10月のJamstack Conf)に向けて備えるためには、その当時の処理の負荷に対して少なくとも2倍の量をこなせるようにする必要があると考えました。つまり、1ヶ月で約1億ページのクロールができなければならないということです。
一晩で2倍に成長させるというのは容易なことではありません: 高度に並列化されたコードとインフラを活用して克服すべき膨大な課題がありますが、最適化をしていく方法もまた沢山あります。
この記事では、とてもシンプルな改修を行ったことで得られた全体の50%におよぶパフォーマンス向上について、どのようなものであったのかをご紹介していきます。
技術的な全体構成
詳細に入っていく前に、まずは私たちのテクニカルなスタックをざっくりご紹介します。
バックエンドは全てNodeJSとTypeScriptで書かれており、GKE(Google Kubernetes Engine)とCloud SQLでホストされています。ストレージにはMemorystore、キューの管理にはRabbitMQを使っています。
このプロジェクトを始める前は、1 VCPUと4GBのメモリを搭載した小さなN1マシンを使っており、主なコンピューティング処理はとても軽量で水平方向にスケールするワーカーによって行われていました。
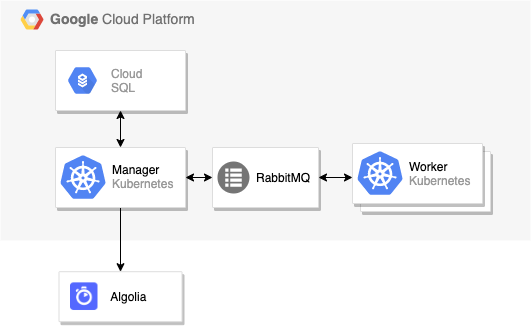
ご覧のように、Managerがジョブをオーケストレーションする形で、負荷に応じてワーカーの数が増えていくというスタンダードなアーキテクチャになっています。
インフラストラクチャの下回りは全てGoogleが管理しているので、私たちの問題のほとんどはSPOF(Single Point of Failure)であるManagerに現れると考えました。
負荷テストで潜在的なボトルネックのあぶり出し
クローラーの管理はシンプルなタスクではありません。このプロセスはキュー、データベースストレージ、ネットワーク、水平方向のスケーリング、Web標準といった、活発に開発が行われていて、且つ、壊れやすいコンポーネント群に依存しています。これらの継続的なタスクのために、DatadogとGKEを活用してシステムの全てのパーツを細かくモニタリングしています。全てのプログラムはディフェンシブな実装となっており、いつでも何かが失敗する可能性があるという思想のもとで構築されています。これは、ネットワークが信頼できなくなった時や、バックエンドでユーザー定義JavaScriptコードを実行する時に非常に有用です。
私たちのシステムは全般的に強固に管理されていますが、特にどの程度までスケールさせることができるのかを見積もる段階においてはそれは簡単なことではありません。ということで、私たちはこの機会を通じてend-to-endなベンチマークを実施することにしました。これによって私たちは潜在的なボトルネックを明らかにし、新たな原因を発見し、今後の改善に関する計画を立てました。
そのために、私たちはステージング環境を使って、非常に短い期間に数千のクローラーを作ってトリガーさせるスクリプトを書きました。数千という数字は多くないようにみえるかもしれませんが、これによって、それぞれのクローラーは実際に数百万のURLを見つけ、データをフェッチし、抽出したデータをインデックスするという処理を同時にこなすことが可能になったわけです。
あっさり失敗した
私たちは、新しいケーパビリティを極めて楽観視していたので、初期段階から失敗することは想定外でした。これは勿論、全てが非常に早い段階で失敗したことを意味します。
初期段階で非常に良い学びを得ることができました。それは、コーナーをカットすること(手を抜くこと)は数年後にあなたに噛み付くということです: 私たちのKubernetesクラスタは手動で作成されており、(コスト削減の為に?)意図的であるのか、それともミスを犯したのか分かりませんが、ステージングと本番環境はかなり乖離していました。
最初のテストの失敗は、クラスタがスケールすることができず、その時に本番環境で発生していた負荷をさばくことができなかったことに起因します。そのため、最初のバッチ処理はほぼ役に立ちませんでした。しかし、このことはTerraformを活用して設定を同期するというタスクをロードマップに戻す良い機会となりました。Terraformは複雑なインフラのオーケストレーションやレプリケーションを、特にKubernetesと共に活用する際に効力を発揮し、私たち(そしてサービスのフリートをやりくりする全ての人)にとってのリアルなゲームチェンジャーとなりました。
さらに失敗する
スタートで失敗したにも関わらず、私たちはそれでも尚、インフラ全体の安定性には自信を持ち続けていました。しかし、道半ばで更に多くの失敗点があることが次々と明るみに出てきました。これは開発者の気持ちを傷付けるものとなってしまったかもしれませんが、その当時はそれが最善だったのです。ここでは私たちがどのように失敗し、そして何を学び、私たちのスタックのどの部分を改善したのかについてご紹介します。
RabbitMQにおけるキューのフットプリントの削減
私たちはRabbitMQをインテンシブに活用し、マルチゾーンのクラスタにジョブを転送するようにしています。ワーカーはジョブの負荷分散を行うためのシングルなファンアウトキューをサブスクライブしており、GKEはそのメトリクスを使い負荷に応じてクラスタを自動的にスケールさせます。特にファンシーなものではありませんが、素晴らしい機能であり、このとてもロバストなソフトウェアに完全な信頼を寄せていました。
ワーカーでページがフェッチされデータが抽出される間に、ジョブは別のインデクシングサービスに送り返され、そのジョブはモニタリングのスタックにプッシュされ、最終的にはAlgoliaに送られます。このインデクシングのステップはクローラー毎に分割されているため、Nカスタマーに対してN個のキューが存在することになります。
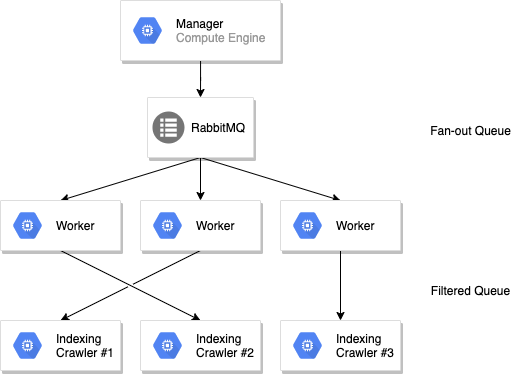
このセットアップで私たちは負荷に応じてワーカーをスケールさせることができます — ほとんどのCPU インテンシブなタスクにおいては –。しかし、共有されたメモリを必要とせずにグローバルスコープな計算(例: インデクシングのグローバルなレートリミット、最大URL、ペイロードのバリデーション等)を行えるように各ステップの後においても、各クローラーは独立して稼働し続けます。
そうこうしている間、私たちは空のキューが沢山存在し、それがRabbitMQに大きな影響を与えていることに気が付いていませんでした。つまり、全てのキューは–アイドル状態にあったとしても–多くのメモリやCPUを消費していたのです。ベンチマークを取得している間、私たちは程なく、以前は到達不能だと考えていた今まで見たこともないような高い上限値に達している状況に遭遇することになりました。
幸いなことに、私たちはソリューションを思いつきました: built-inなTTL機能を使ってshort-livedなキューを使うというものです。しかしこれには2つ目の問題点がありました: キューの設定は、キューが作成された後は変更できないため、開発段階においては常にキューをスクラッチで作り直せるものの、プロダクションにおいては大変なことになってしまいます。古いキューの削除には時間がかかりますし、私たち開発者は常にスマートな方法を見つけてパーフェクトなソリューションを探し出すことで怠けることを目指しているので(訳注: プログラマの3大美徳としてLazinessが挙げられる)、解決策として、キューの名前にクローラーのバージョンを入れることにしました。
これによってデプロイのたびに、あたかも”新しい環境”を立ち上げるような形となり、RabbitMQは(訳注: TTLによって)自動的に古いキューを数分後に破棄すれば良いことになります。
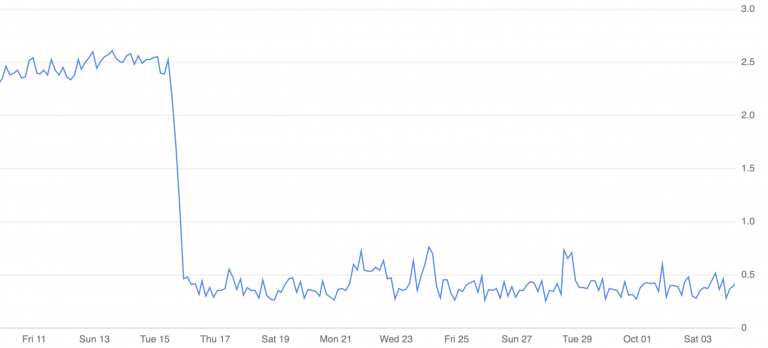
ソリューション:
- 毎日処理することになるとしても短いライブキュー(15分)を使う
- バージョンキュー名にすることでいつでも全てを廃棄してゼロから作り直すことが可能に
Kubernetesのコストとリソースユーセージの改善
Kubernetesはマスターするのには非常に複雑なシステムであるものの、私たちクローラーチームの人間はインフラの専門家ではありません。より良い自動スケーリングを可能にするためにおよそ2年前に移行を行った際は、私たちはコストを許容範囲に抑えつつ、やりたいことがシンプルに動作することにフォーカスしていました。このようなベンチマークを行っているうちに、スモールなマシンではあらゆることに非効率であることに気が付きました。
コストはリニアに増えるわけではなく、大きなマシンの方がコストは抑えられます。Kubernetesは常に少量のCPUとメモリを使用するので、マシンが大きければ大きいほどフットプリントは小さくなります。また、1つのVCPUにPodをフィットさせるよりも、特に成長へのマージンを持っておきたいと考えた場合に、1つの大きなマシンに多くのPodを詰め込む方が扱いが簡単です。
ということで、移行後に、いくつかの要件を変更しただけで、ベースとなるコストを削減し、CPUの無駄を省き、パフォーマンスを向上させることができました。
ソリューション:
- E2 High-CPUのコストを最適化したマシンに移行(ハードドライブ無し)
- Kubernetesがより良いテトリスゲームをプレイできるように全てのリソースの要件を変更(※ デフォルトのKubernetesのスケジューラーはそのままではノードを100%満たすようには動作しません)
Serverless とスケーラビリティ
同じ設定を適用した後に、2回目のベンチマークにおいてもスケールについて考え抜くことができていなかったため、直ぐに失敗してしまいました。Kubernetesでは、例え”serverless”であったとしても、水平方向のスケーリング戦略、ディスクスケーリング戦略、CPUスケーリング戦略…といったものに緊密に結びつきます。全てが魔法のようにスケールするわけではなく、コストは通常のスケールと同様で — そして、まだ膨大な負荷用に設定を施されていないPostgresやRedisのようなマネージドサービスに依存しているかもしれません。
これが意味することは、より良い最小値、より寛容な最大値、負荷に応じた自動スケーリング、そしてあらゆる場所での高可用性(ゾーンもしくはリージョン)を実現するために、全てを設定しなければならないということです。
私たちのセットアップ:
- Datadogのメトリクスでワーカーをスケールさせる(RabbitMQのメトリクスが使われる)
- HPA(Horizontal Pod Autoscaler)で数十ではなく数百のワーカーを許可する(Maxの設定があることによりコストコントロールが可能になる)
- 自動スケーリングとGCPにおけるPostgreSQLの高可用性を有効にする
- Memorystoreにおける高可用性を有効にする
そして、もし99%の負荷が”通常”であったとしても、高可用性、リージョンをまたぐレプリケーション、ベンチマークなどで、より大きなスパイクに対応できるか確認する必要があるため、初期費用はかさむ傾向にあります。
GCPにおいては、あちこちのチェックボックスをオンにするだけで月に数百ドルがかかりますし、もし1:1なステージング環境を構築する場合はその倍の費用がかかることになるわけです。このようにして、全てを十分にテストをして設定を施すことにかなりのコストがかかるわけですが、これはお客様に満足していただくために支払わなければならい隠れたコストなのです。
DNSのレイテンシ削減およびエラーの削減と94%のperfの向上
問題が発生するに至るまで見落とされがちなのがDNSスタックではないでしょうか。通常ではレイヤが低いもののため、詳細な最適化は必要ありません。しかし、一度ネットワークやスケール状態でのハイパフォーマンスを気にかけるようになると、大きな問題に出くわすことがあります。
インフラが修正され、ベンチマークが実行されるようになってから、Datadogのダッシュボードで全てを監視しはじめました。そこで私たちはDNSの問題に気が付きました。GCPにおいては強力なセットアップを行っていたこともあり、シンプルなウェブサイトのコールに失敗していたことに驚きました。そして更に悪いことに私たちAlgoliaのコールもまた失敗していたのです。
エラーそのものはcryptic(屁理屈)で全く参考になりませんでした。それは“connect EADDRNOTAVAIL 95.211.230.144:443” “getaddrinfo ENOTFOUND 8j0ky6j9fn-1.algolianet.com” や “Connection timeout” のようなものです。
明らかにAlgoliaのウェブサイトは稼働していたため、私たちはこの問題をローカルで再現させようとしましたが、個人マシンの制限によって、再現はほぼ不可能でした。これらのエラーは負荷が高い時のみに発生し、通常の使用においては再現させることができなかったのです。
前述のように、こちらは一般的には見過ごされがちなトピックであり、私たちはあまり注意を払っておりませんでした。しかし、私たちのHTTPスタックが正しい状態に最適化されていないということは明らかでした。
十分な時間をかけて調査を行った結果、最終的にいくつか異なる問題点を見出しました:
- NodeJSにおけるDNSの名前解決が正しく動作していない(github.com/nodejs)
- NodeJSにおけるDNSの名前解決がデフォルトではシェアされない(nodejs.org)
- AlpineのイメージにおけるDNSの名前解決が正しく動作していない(cloudbees.com)
最初のFIXは、私たちの全てのHTTPコールを{ family: 4 }とすることでIPv4に固定するというものです。このシンプルな解決策は劇的に名前解決およびサクセスレートの向上に繋がりました。
http.get({ family: 4, ... }, cb);次の大きな修正点は、システム全体でHTTPエージェントを共有して利用することで、1つのTCP poolのみをオープンするように、というものです。これは単純なフェッチだけでなく、algoliasearchクライアントにもこのエージェントを渡すことを意味します。
// agent.ts
export const httpsAgent = new https.Agent({
keepAlive: true,
timeout: 60000,
maxFreeSockets: 2000,
scheduling: 'fifo',
});
// algolia.ts
import algoliasearch from 'algoliasearch';
import { httpsAgent } from '../http/agent';
export const requester = createNodeHttpRequester({
httpsAgent,
});
const client = algoliasearch(appId, apiKey, {
requester,
});そして、最後のFIXはKubernetesで稼働するAlpineのイメージをDeployment/StatefulSetで、dnsConfigのオプションをシンプルに以下のように設定し直しました。
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: crawler
spec:
replicas: 1
template:
dnsConfig:
options:
- name: ndots
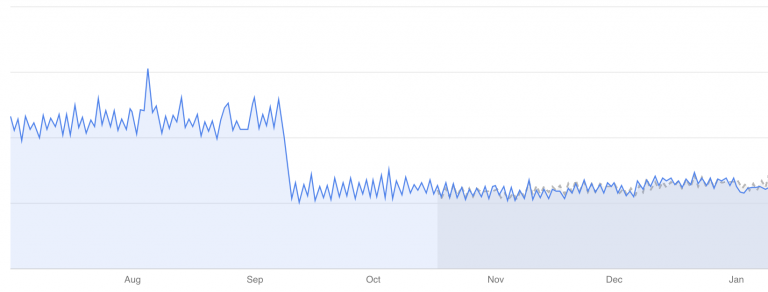
value: '1'これらの修正が全て反映された後、1日90万件のTCP接続があったものが、わずか1万2000件に削減され、99%のCPUの無駄、時間の無駄、そしてお金の無駄が解消されました。
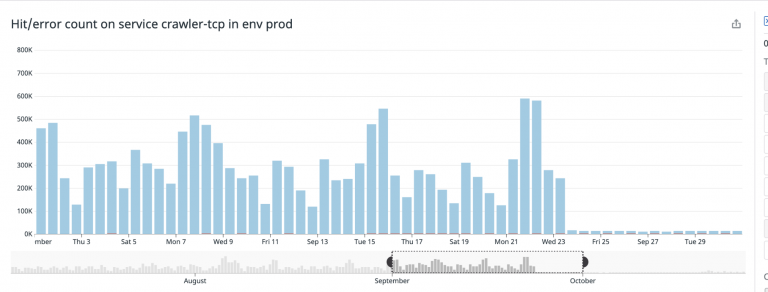
さらに驚くべきことに、Algoliaにインデクシングを行う際のAlgoliaへの到達にかかる時間が大幅に短縮され、1コールあたり平均1.5秒もかかっていたものが安定して0.1秒になりました – 驚異的な94%のperfの向上となっております。私たちが考えていた以上に高速に動作しているということで、これは素晴らしいことです。
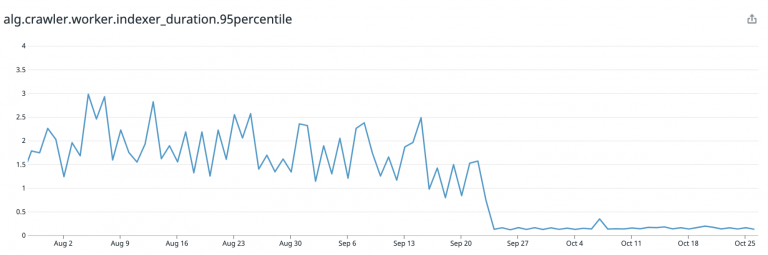
ソリューション:
- HTTPエージェントの共有
- 名前解決をIPv4に固定
その他の改善
Dockerイメージのサイズとビルド時間の向上
私たちがDockerイメージをビルドする際は、特にビルド時間が長い時などは、過度な最適化をプッシュさせないようなDockerfileのやりくりにかなり苦労をします。しかし、特にレイヤー、ベースイメージ、ファイルシステムのスナップショット…といったところには多くの問題が存在します。
レビューの際に2つのことに気が付きました:
- 私たちのイメージは大きすぎる
- 私たちのイメージはキャッシュを適切に使えていない
なぜおそすぎるイメージや大きすぎるイメージを気にする必要があるのでしょうか?イメージサイズの増加はKubernetesの起動時間を長引かせますが、最適化されたイメージのロードはスムーズで素早くブートします。また、それによってビルドが早くなり、つまりホットフィックスが素早くできるようになるということを意味します。つまりWin-Winですね。
ということで、この改善のために行ったこととしては、WORKDIR全体をコピーするのではなく、最初にpackage.jsだけコピーをして、depsをインストールし終わってから残りをコピーするというシンプルなトリックを用いることにしました。これによって何も変更がなければDockerはnode_modulesフォルダーをキャッシュすることができます。私たちのフローでは、週に1回は依存関係のアップグレードを行うというもので、それの意味するところは、それ以外の日はキャッシュが利用できる、ということです。
FROM node:14.15.1-alpine AS base
ENV NODE_ENV production
# Install dependencies
# python make and g++ are needed for native deps
RUN apk add --no-cache bash python make g++
# Setup the app WORKDIR
WORKDIR /app/crawler
# Copy and install dependencies separately from the app's code
# To leverage Docker's cache when no dependency has change
COPY package.json yarn.lock ./
COPY pkg/crawler-manager/package.json pkg/crawler-manager/package.json
[...]
# Install dev dependencies
RUN yarn install --production=false --frozen-lockfile --ignore-optional
# This the rest of the code, no cache at this point
COPY . /app/crawlerそれでもなお、Typescript, webpack, babel…といった必要なnode_modulesが全て含まれているため、イメージのサイズは非常に大きく、約600MB程度になります。Kubernetesで稼働する各ワーカーはこの大きなイメージを取得する必要があるため、起動時間が大幅に増加してしまっていました。
これをmulti-stagesビルドによって、サイズを1/5に減らすことができました。このシンプルな変更を最後に加えたことによってイメージのサイズは100MB程度になりました(まだサイズは大きいですが、遥かに良くなりました)。
FROM node:14.15.1-alpine AS base
ENV NODE_ENV production
# Install dependencies
# python make and g++ are needed for native deps
RUN apk add --no-cache bash python make g++
# Setup the app WORKDIR
WORKDIR /app/crawler
# Copy and install dependencies separately from the app's code
# To leverage Docker's cache when no dependency has change
COPY package.json yarn.lock ./
# Install dev dependencies
RUN yarn install --production=false --frozen-lockfile --ignore-optional
# This the rest of the code, no cache at this point
COPY . /app/crawler
# Build and keep only prod dependencies
RUN true \
&& yarn build \
&& yarn install --production=true --frozen-lockfile --ignore-optional
# Final Image
FROM node:14.15.1-alpine as web
USER node
WORKDIR /app/crawler
COPY --from=base --chown=node:node /app/crawler /app/crawler
EXPOSE 8000フロントエンドバンドルのサイズ
スケールした状態でのパフォーマンスの向上に関しては、バックエンドのコードの改善だけが必要なわけではありません。UIが遅いということは、ユーザーが遅いと感じてしまうことを意味します。私たちにとっては、多くの方にスタティックなファイルをサーブするわけで、大きなバンドルは大きなロード時間を発生させ、それはよろしくないユーザー体験と帯域のコストがかかることに繋がります。
そういった背景もあり、バックエンドのパフォーマンスにフォーカスしていた一方で、フロントエンドのバンドルに関しても取り組みをはじめました。Tree Shakingを有効にしてwebpackバンドルを最適化する方法に関しては、様々な参考資料がありますので、ここでは私たちが行ったことの短いサマリだけご紹介させていただきます。
webpack-bundle-analyzerによって、JavaScriptコードのマップをクイックに作成し、何が必要で何が不要かを見出すことができます。私たちのコードはバンドルサイズの10%未満で、数十のページと数百のコンポーネントが大半を占めていることが分かりました。そんな中、私たちが依存しているのは: React.js, Monaco Editor(これはVSCode Editor), React Feather, Prettier(Monacoと共に利用)等のペイロードが主なパートを占めており、全てがツリーシェイクされ、正しく最適化されている状態ではありませんでした。
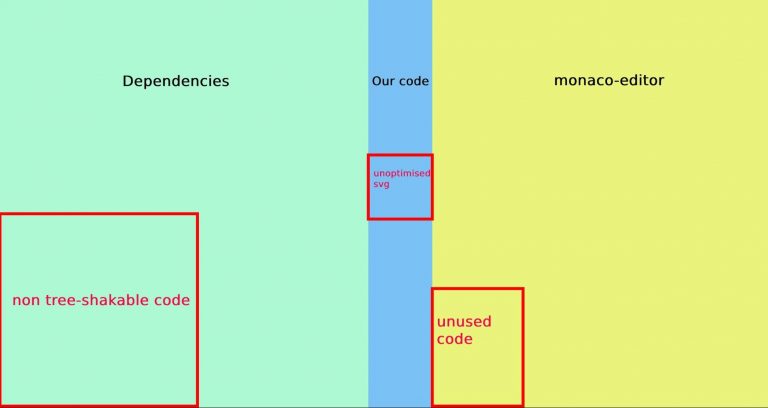
以下がまとめです
- SVGはかなりの容量を必要としますが、正しく圧縮するだけで500KB近くの削減が可能
- Tree Shakingを可能にするには”module”: “esnext” をtsconfig.jsonに定義しなければならない
- いくつかのパッケージはtree-shakableではないものの、
NormalModuleReplacementPluginもしくはnull-loaderを使うことで簡単に部分的な切り捨てを行うことができる - Webpackのチャンクはバンドルのサイズを小さくできない場合にとても役に立つ
- Nginxを使っている場合はgzip圧縮を有効にするのに
gzip:onだけでは不十分でgzip_typesも指定する必要がある
これらのTweakを施しただけで7.6MB(1.8MB gzipped)から5.9MB(1.2MB gzipped)になり33%サイズを減らすことができました。
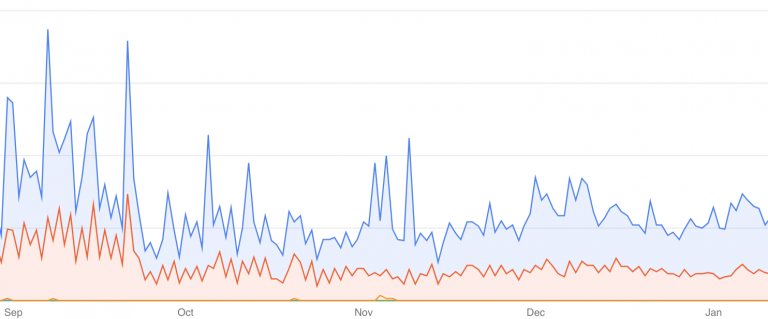
最後に
私たちのクローラーは安定性を第一に据えながら、性能は二の次として考えていました。それは、直ぐにエラーになってしまうようなツールよりも信頼性の高いツールこそ重要であるとしていたからです。しかし、私たちは機能として正常に動作していたがために、最優先のプライオリティとならなかった数多くの簡単なパフォーマンス・チューニングの機会を逃してしまっていました。
新しいプロジェクトおよび新しいディレクションが、それらのトピックをロードマップに復活させ、私たちプロダクトの未来への発展を築いてくれました。
このことによって私たちは単に自信を得ただけでなく、9月の改修により2倍の負荷に耐えられるようになっており、1年後に10倍になっても大丈夫であると考えています。つまり、より多くのお客様に是非ご活用いただきたいということです。また、私たちの既存のクローラーのお客様のパフォーマンスを50%近くも改善できたというのはとても大きな収穫になりました。
ご質問やコメント等ございましたら、Twitterの @algolia もしくは support@algolia.com までお寄せくださいませ。


コメント