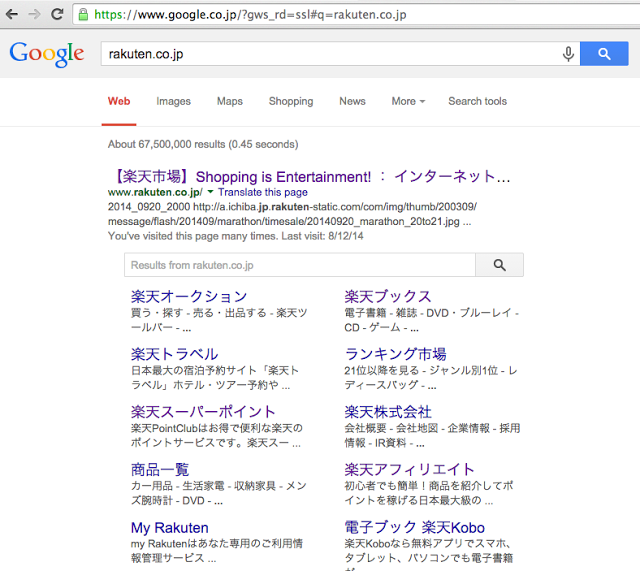
現場でよくグループ検索がーとかって話になったりするのですが、Apache Solr入門 を読んでたら
“グルーピング検索”っていうのね、と。
Solr WikiのFieldCollapsingを読むと↓のように書いてあって、
・Field Collapsing
Field Collapsing collapses a group of results with the same field value down to a single (or fixed number) of entries. For example, most search engines such as Google collapse on site so only one or two entries are shown, along with a link to click to see more results from that site
(篠原訳)
Field Collapsingは同じフィールドバリューを持つものを1つ(もしくは固定数)にまとめるもの。
Google検索みたいに1個か2個のエントリだけ表示してもっと結果を見たければリンクを押すヤツ。
#Googleみたいに〜って書いてあるけど、最近Googleの検索って+ボタン出てこなくて
#更に検索窓付いたりしてるーとかって思ったりもします。。

・Result Grouping
Result Grouping groups documents with a common field value into groups, returning the top documents per group, and the top groups based on what documents are in the groups. One example is a search at Best Buy for a common term such as DVD, that shows the top 3 results for each category (“TVs & Video”,”Movies”,”Computers”, etc)
(篠原訳)
Result Groupingは共通するフィールドバリューをドキュメントをグループにまとめて、グループのTOPドキュメントを返す。で、TOPグループはグループ内のドキュメントをベースにする、と。
例えば、”DVD”に関するBest Buyといった場合に、それぞれのカテゴリーごとに3つずつ表示する的な。(カテゴリーは”TVs & Video”,”Movies”,”Computers”とか)
#んー、、、英語難しす…汗
と、まぁ上記のようなことが実現出来るのね、と。
グルーピング検索するにはクエリパラメータでgroup=trueにしてあげて、
フィールドの指定、グループ化するためのクエリ文字列(範囲とか)、何件表示するかとかそういうの。
んま、文字でツラツラ書いても仕方ないので、Apache Solr入門に沿ってやってみます。
自分がニュースまとめサイトみたいのを作るとしたらーって感じで、
以下のようなスキーマを考えてみます。idは特にアレで、ジャンルと、どのメディアと、それがどれだけFBでLikeされてるか的な、で最後にURL。
id,genre,media,like,url 001,sports,yahoo,10,http://headlines.yahoo.co.jp/hl?a=20140921-00000521-sanspo-socc 002,music,ameba,21,http://amebreak.ameba.jp/news/2014/09/005158.html 003,sports,nikkansports,33,http://www.nikkansports.com/soccer/japan/asiangames/2014/news/f-sc-tp0-20140921-1370597.html 004,music,yahoo,9,http://headlines.yahoo.co.jp/hl?a=20140921-00053963-lisn-musi 005,technology,huffingtonpost,87,http://www.huffingtonpost.jp/techcrunch-japan/iphone6_b_5855744.html 006,fashion,fashion-press,43,http://www.fashion-press.net/news/12132 007,business,yahoo,32,http://news.yahoo.co.jp/pickup/6132018 008,technology,huffingtonpost,29,http://www.huffingtonpost.jp/2014/09/21/iphone-small-hand-case_n_5856400.html
schema.xml的にはデフォルトのアレからソレっぽいところを消して↓に入れ替える感じ。
<field name="id" type="string" indexed="true" stored="true" required="true" multiValued="false" /> <field name="genre" type="text_general" indexed="true" stored="true" required="true" multiValued="false" /> <field name="media" type="text_general" indexed="true" stored="true" required="true" multiValued="false" /> <field name="like" type="long" indexed="true" stored="true" required="true" multiValued="false" /> <field name="url" type="text_general" indexed="true" stored="true" required="true" multiValued="false" />
で、ローカルに入れたSolrに食わせてみます。

グループ化した検索をしてみます。
ジャンルがtechnologyかsportsでメディアでグループ化します。
#なんか、もうちょい、ちゃんと考えたデータ作るべきでしたね。。w

んま↓こんな感じでちゃんとグループ化されてますよ、と。
デフォルトの表示件数は1なのでハフィントン・ポストの記事は2つあっても、1つしか表示されません的な。
ソートはLikeの数なので多い方だけが出ておりやす。
{
"responseHeader": {
"status": 0,
"QTime": 4,
"params": {
"q": "genre:(sports or technology)",
"indent": "true",
"fl": "id,like,url",
"sort": "like desc",
"wt": "json",
"group.field": "media",
"group": "true",
"_": "1411290295136"
}
},
"grouped": {
"media": {
"matches": 4,
"groups": [
{
"groupValue": "huffingtonpost",
"doclist": {
"numFound": 2,
"start": 0,
"docs": [
{
"id": "005",
"like": 87,
"url": "http://www.huffingtonpost.jp/techcrunch-japan/iphone6_b_5855744.html"
}
]
}
},
{
"groupValue": "nikkansports",
"doclist": {
"numFound": 1,
"start": 0,
"docs": [
{
"id": "003",
"like": 33,
"url": "http://www.nikkansports.com/soccer/japan/asiangames/2014/news/f-sc-tp0-20140921-1370597.html"
}
]
}
},
{
"groupValue": "yahoo",
"doclist": {
"numFound": 1,
"start": 0,
"docs": [
{
"id": "001",
"like": 10,
"url": "http://headlines.yahoo.co.jp/hl?a=20140921-00000521-sanspo-socc"
}
]
}
}
]
}
}
}
上記の説明がイマイチで良くわからないという方がいらっしゃいましたら、
↓の購入をオススメします。笑
![[改訂新版] Apache Solr入門 ~オープンソース全文検索エンジン (Software Design plus)](http://ecx.images-amazon.com/images/I/514TjyZH6DL._SL160_.jpg)
技術評論社
売り上げランキング: 179,862

コメント