
こちらはAlgolia Blogの Removing outliers for A/B search tests の翻訳です。
新しい機能が上手くいっているのかどのように測定するか?どのようにそのインパクトをテストするのか?これには、Feature flagを含む様々な方法があると思います。Optimizelyやその他のサードパーティシステムのようなA/Bテストソリューションも、多くの人がその機能のインパクトをテストするために使用していると言えるでしょう。
Algoliaをご利用いただくにおいて、お客様は新しく出した機能がコンバージョン率やクリック率にどのようなインパクトを与えるのか、もしくは、収益をどのように向上させるかを理解したいと考えています。AlgoliaのダッシュボードにはA/Bテストの機能があり、お客様はこの機能を使ってテストを行うことができます。お客様は、Dynamic Re-RankingやAI検索などの導入によって、クリック率やコンバージョン率がより向上するかもしれないという仮説を立てて、A/Bテストを実施します。
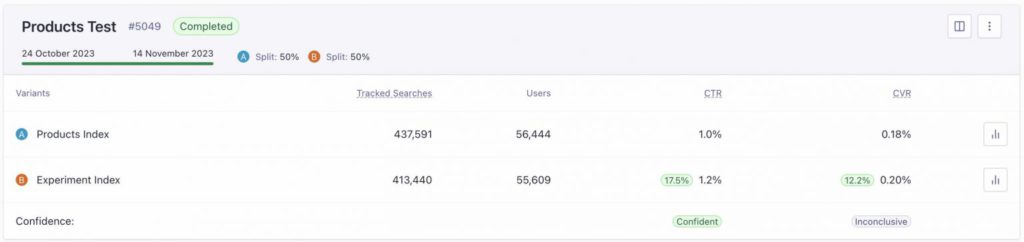
ダッシュボードには、クリック率(CTR)とコンバージョン率(CVR)が表示されます。テストが進んでいくにつれて、アップリフトやインパクトも測定されます。この例では、2つの異なる設定のパーソナライゼーションに関するテストの結果を測定しています。これらのテストはサイト上で実施されるため、クリック数やコンバージョン数が不正確なデータで汚染されてしまう場合があります。
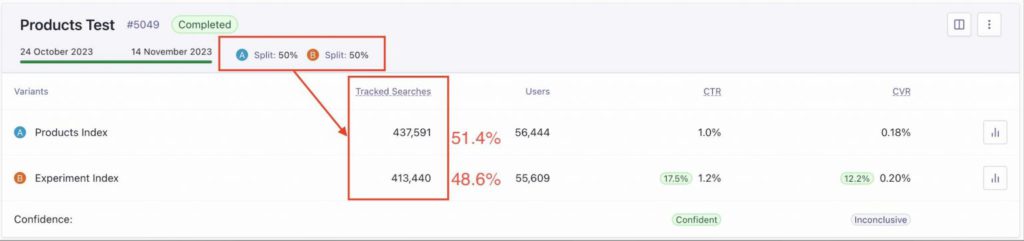
上の画像でお気付きの点があるとすれば、”Tracked Searches”の数に違いがあることかと思います。思いの外大きい数字なのではないでしょうか。50/50のトラフィック分割は、お客様が設定したものですが、約3%も差分があり、AとBで2万件もtracked Searchesの数が違っています。理想的には、50/50の割合にもう少し近づけるべきであると思います。
それでは、なぜこのように数字が異なっているのでしょうか?基本的には bot がその答えです。お客様が明示的にクリック解析を無効にしていない限り、botが何千何万という検索を行う可能性があります。それはクリック率とコンバージョンの統計を狂わせてしまい、ひいてはテストの結果に影響してしまうかもしれません。もちろん、これは単なる迷惑行為というわけではなく、ビジネスを最適化しようとしている私たちのお客様にとって必要なものの場合もあるでしょう。しかし、このようなbotのトラフィックは、クリーンな結果を得ることを妨げてしまいます。
私たちは、このような外れ値を自動的に取り除いて、お客様により正確な結果を提供する方法を見つけたいと考えました。このブログでは、私たちがどのようにこの問題に取り組んだかを説明していきます。
By the numbers (数字によって判断する)
簡単な例を挙げると、あるA/Bテストにおいて片方が10,000回検索され、1500回のコンバージョンがあったとします。単純に割り算するとコンバージョン率は15%です。もう片方は10,900回の検索で1600回のコンバージョン、ということでコンバージョン率は14.6%です。

もし2つ目の方にbotによるトラフィックがあったとすると、それは良いものとは言えません。コンバージョンが15%から14.6%になったということを悪い傾向と捉えるかもしれませんが、問題を修正すれば、1000件の検索が偽陽性であることが判明するかもしれません。ここで、そのbotによるトラフィックを取り除くと、本来の結果が得られるようになります。

こちらのA/Bテストではbotによるトラフィックを取り除くことでコンバージョン率16%という良い結果をもたらしました。これは極端な例かもしれませんがポイントを示していると思います。当然botトラフィックを取り除くと、良くない結果になる場合もありますが、それは正しいものであると言えます。
外れ値とは何か?
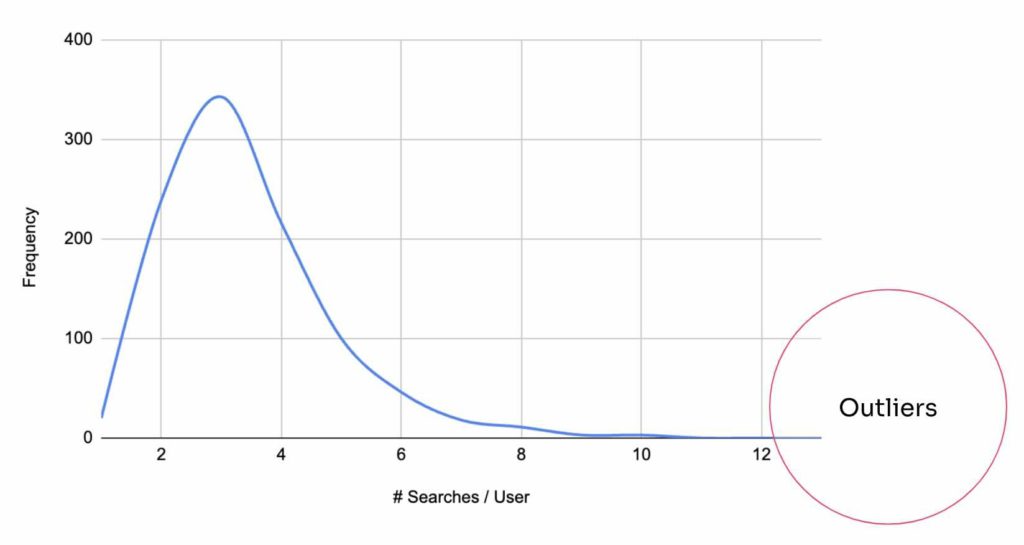
新しい設定によって、より迅速かつ正確にデータを外れ値としてラベル付けすることができるようになりましたが、では外れ値とは何なのでしょうか?正規対数分布を見ると、上のグラフのようになります。このグラフは仮定のもので、ほとんどのサイトでは、データの分布はかなり異なっていて、もっと深いロングテールを含んでいるものになるかと思いますが、こちらの例では、ほとんどの人がウェブサイトで2回から5回の検索をしていることがわかります。何千回も検索することはまずありません。何千ものセッションで検索回数をカウントすると、右端の方に外れ値が見つかります。そこで問題になるのは、それをどのように定量化するかということです。通常の検索とフェイクなデータと思われるものの間のしきい値をどこに設定すべきでしょうか?
Algoliaでは、少なくとも100回の検索数をしきい値として設定していて、且つ、ユーザー1人あたりの検索数の平均値から7標準偏差以上離れているというようにしています。言い換えれば、このフェイクデータの判定には、アプリケーションの平均値からかなり離れた回数の検索が必要ということになります。
フラットに100回の検索数としているのは、検索の99%を占めるてしまうような非常にユニークなデータセットを除外するためです。99.99999回以上の検索をする人は外れ値というラベル付けをされる可能性があります。
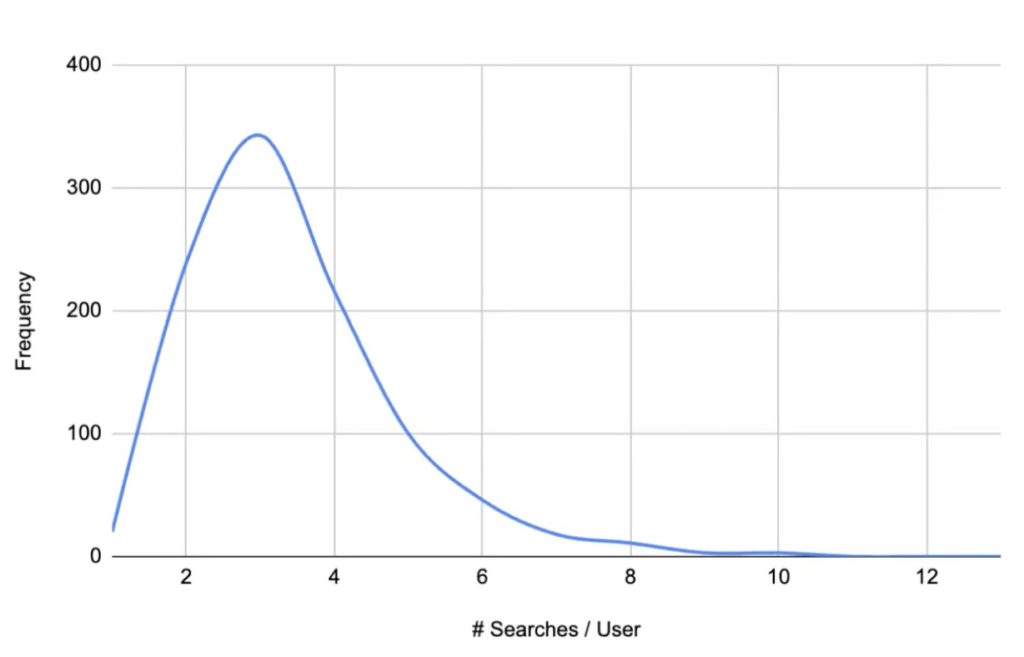
上のグラフは対数正規分布と呼ばれるものです。平均と標準偏差を求めるには、このデータセットのそれぞれの自然対数を取れば、正規分布のベルカーブに似たものが得られます。この時点で、正規分布の平均と標準偏差を求めることができます。
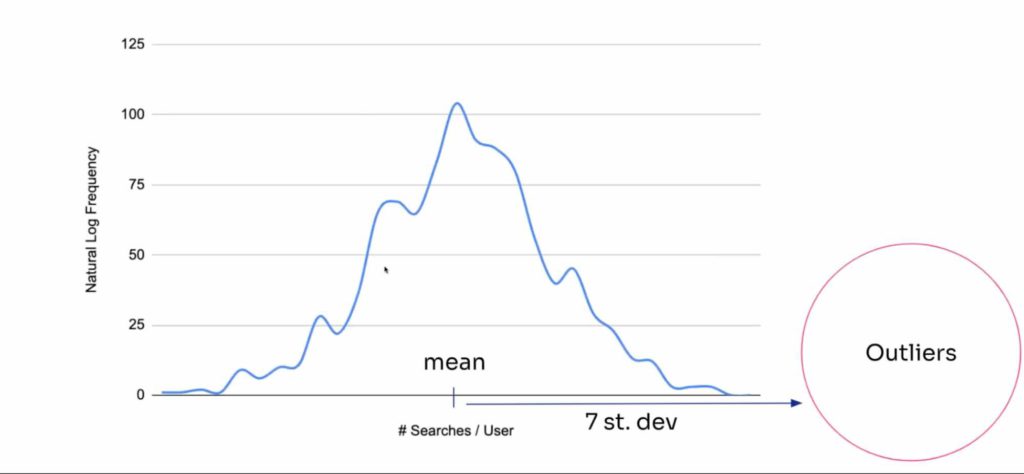
そして、ユーザーをしきい値で分類して、外れ値としてラベル付けします。この方法を開発するために、私たちのエンジニアの一人であるHugo Rybinskiは、外れ値を検出するためのさまざまなアルゴリズムを調査しました。彼は、Isolation forestとデータ生成のようなものを検討しましたが、単純に検索回数が多すぎる人を外れ値としてラベル付けする方がはるかに簡単で速いと判断しました。もう一人のチームメイト、Raymond Rutjesもこの解決策にたどり着くために多くの下準備をしてくれました。彼ら二人に大きな拍手を送りたいと思います!
A/Bテストのセットアップ
外れ値を取り除くために、作成される各テストにグローバル設定を追加して、デフォルトで外れ値を削除するようにしました。すべてのデータを集計して計算によって外れ値を除外します。
結果としては、以下のようになります:
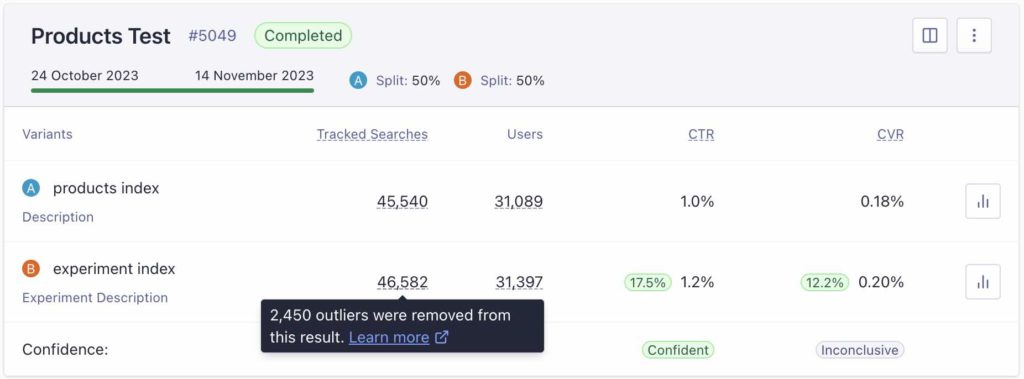
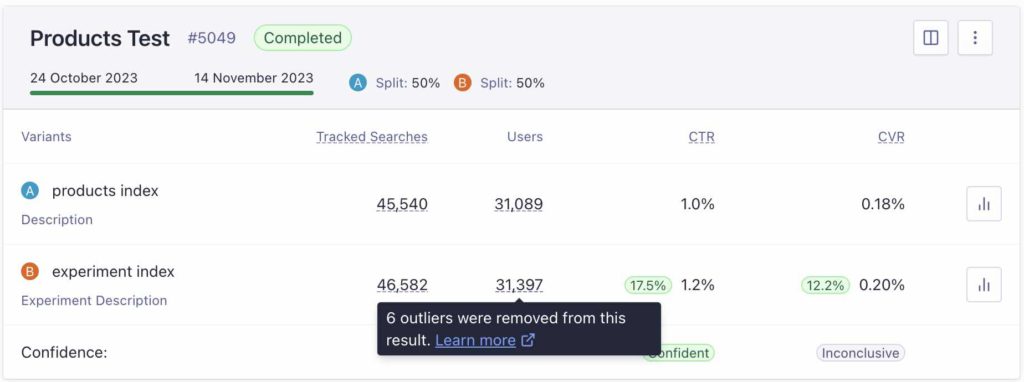
外れ値が除外された状態でお客様は結果を見ることができます。上のA/Bテストの例では、それぞれで除外されたTracked SearchesおよびUsersの数がご覧いただけるようになっています。こうすることで、データがより正確になり、お客様がA/Bテストを解釈して、結果に基づいた意思決定を行うのに役立ち、データへの信頼を高めることが期待されます。
What’s next for A/Bテスト
Algoliaのエンジニアリングの内部で、私たちがどのように問題に取り組んできたかを楽しんでいただけたなら幸いです。A/Bテストは、お客様が検索アルゴリズムを改善し、様々な機能を活用することを可能にするプロダクトとしてのコア機能の一つです。実際に、次のようなものが間もなくリリースされる予定です。
- feature-specific(機能に特化した)A/Bテストのサポート
- フィルターのシンタックスツリー表現 – 特定のタイプの検索を操作するための動的なクエリの構造化
- サンプルサイズの見積もりによって、お客様がテストをどのくらいの期間実施すればよいかを分かるようにする
… などなど!A/Bテストの実行については、是非ドキュメントをご覧ください。

コメント