
AlgoliaのSr. Software EngineerのJerome Schneider(@jeromeschneider)のコーディングに関するブログを翻訳しました。
コードを書くことは難しいが、質の高いコードを書くのは尚の事、難しい。
ソフトウェア開発企業においては、チームワークに依存し、もしくは、何人にも渡るコードを書いていくプロジェクトを推進しています。そんな中で、コードの品質の指標の一つとして挙げられるのは、いかにmaintainable(fixable, modifiable)であるか、そしてextendable(re-usable, composable)であるか、ということかと思います。言い換えれば、開発者の視点でそのコードが使えるものであるかどうかといったところでしょうか。
それではどのようにusableなコードをデザインしていくかみていきましょう。testabilityとloose couplingなテクニックについてコードをよりmaintainableにしていくものとして紹介していきます。また、併せてコードをcomposableそして(re-)usableにする方法もご紹介します。
Testability
Testing codeはinputに対して想定しているoutputそして期待した挙動をするかどうかを確認するためのものです。test codeには様々なやり方がありますが、今回はintegration testingとunit testiingに焦点を当てていきます。
integration testingとunit testingといったテストがレギュラーとエッヂの両方のケースにおいてコードの振る舞いを検証する上で、それぞれがどのように補完的な関係であるかをみていきましょう。
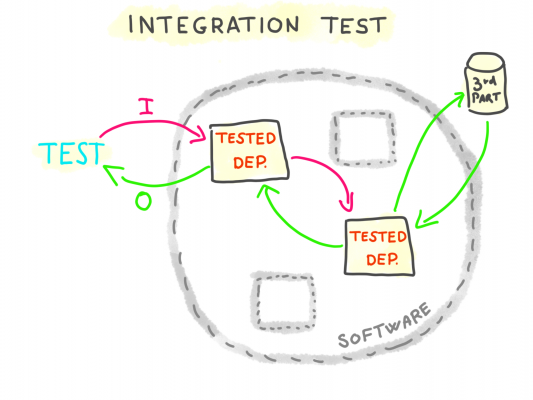
Integration testing
Integration testingは、分離されているソフトウェアのパーツを、実際の入力およびI/Oシステムを使って検証するものです。
実際のI/Oシステムを通して、ソフトウエアの振る舞いが期待しているものであるかを検証することになるので、Integration testingはレギュラーなケース(“happy path”と呼ばれる)に使われるものと言えるでしょう。なぜなら、実際のI/Oシステムを使ってエッヂケースな挙動を行うのは難しいからです。例えばDBコネクションエラー、データの不整合、ファイルシステムのエラー、ネットワークタイムアウト等が挙げられます。
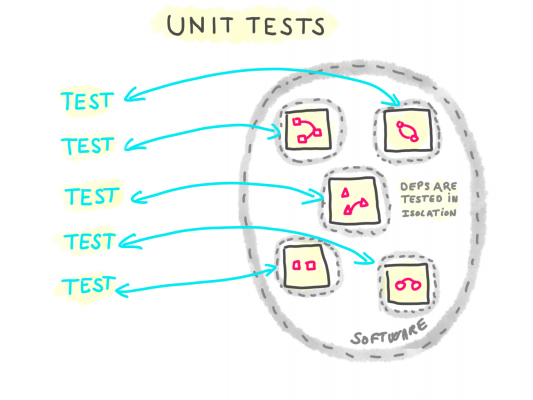
Unit testing
Unit testingではダミーのI/Oシステムと依存するモジュール等を使って与えられたインプットに対してソフトウェアのテストをしていきます。ここではレギュラーなケースに加えてエッヂなケースも扱います。例えばslow dependency, corrupted dependency, erroring dependency, invalid input等が挙げられます。
“dependency”とは、自分自身で開発していないけれども使っているコードのことで、serviceやmoduleと呼ばれるようなものです。
Unit testingはdependenciesを細かくコントロールしながらレギュラーなケースだけでなくエッヂなケースも扱います。APIクライアント、DBコネクション、メーラー、ロガー、authorizationレイヤー、ルーティング等
短く言えば、unit testingは、integration testingやend-to-end testingでは行うことが難しいようなエッヂケースの問題を検知することができます。
もちろん、ソフトウェアがexposed to in the wild(特にインターネット上に晒される場合等はそうかな、と思います)になった場合に、本当に全てをテストすることは難しいこともありますが、それでもunit testingはエッヂケースが起こった場合に、それが適切に処理されるのかを保証するのに有効なツールであることに変わりはないでしょう。
全てをテストする、そして、どのように
UnitおよびIntegrationテストをするのに以下が必要です:
- ソフトウェアのパーツを独立して動かせること
- 全てのconcernがそれぞれ独自のscopeにあるように独立させることでそれを行う
- エッヂケースをコード内で発生させる
- 依存する部分の振る舞いをコントロールし、モックを活用する
- dependencyとの依存をダミーのdependencyで置き換える
- モックdependenciesをinjectingする
Single Responsibility Principle: ソフトウェアを分割しそれぞれ独立して動作可能に
通常、ソフトウェアは一つ以上の複数のことを行い、単一の機能であったとしても、他のいくつかの機能に依存します。
しかし、1度に行うテストは1機能にしたいので、そういった観点でソフトウェアを分割したいと考えます:
- テストのセットアップを容易に
- 全てのケースのテストを行うことを可能にし、
- テストが失敗したピンポイントな理由を明らかにすることができる
このレベルのソフトウェアの分離を実現するために、私たちはSingle Responsibility Principle(SRP)を導入しています。全てのソフトウェアは単一のsingle-concernを扱うべきというものです。
concernのスコープはソフトウェアの文脈に沿ったものとなります。例えば、メールを送信するようなソフトウェアにおいて、メーラーサービスはSMTPにメールを届けるという一つのresponsibility(責務)を持ちます。しかし、電子メール送信プラットフォームのコードにおいては、多くのconcerns(SMTP, templating, security, permissons, rate limits,…)を扱わなければならない可能性があります。

ここで、clean-cutなconcernがdependencies(依存)に出てきたので、コードの中でどのようにして依存関係を解決してアダプティブにイニシャライズしているのかを見ていきましょう。
コードの中でのエッヂケースへの促し
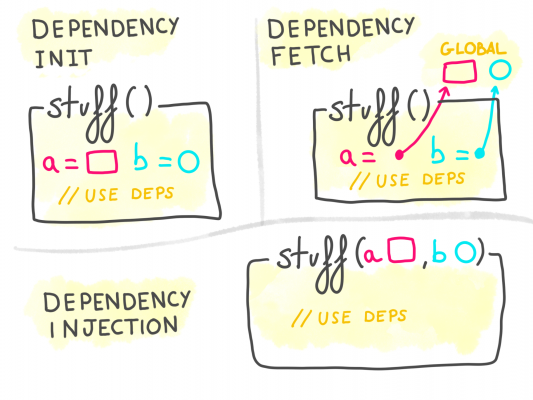
トラディショナルな依存関係のハンドリングの方法としては、ビルドしたり、自分自身でフェッチしてきたり、といったことが挙げられます。例えば、JSON APIで問い合わせを行うようなサービスは、独自のAPIクライアントをビルドしたり、グローバルなシングルトンからそれをフェッチしたりします。
これについては、イニシャライズ済みのdependenciesを渡すことにより、ビルドやフェッチをさせるのではなく、自分たちで依存関係の初期化方法をコントロールするといったことが挙げられます。
つまり、コードその門おな依存関係の制御をすることはなく、完全に初期化済みのものを受け取ることを期待する、ということです。
このパターンは“Inversion of Control” (IoC) や “Dependency Injection” (DI) と呼ばれています。
これはパワフルな原則であり、testabilityという点においては、次のセクションで詳細を述べますが、異なるものということが出来るでしょう。
依存関係の実装をダミーの実装を用いて置き換える
ここまで見てきたように、依存性を外部から注入することは、依存関係を使用するコードの外側で初期化(そして次に、振る舞い)を制御することでした。
依存関係がJSON APIクライアントという先ほどの例の続きとして、エッヂなケース(slow response, timeout, broken json, invalid response,…)に関してはどのようにテストをすれば良いでしょうか?
APIクライアントを改造して人為的に待ち時間を増やしたり、サーバーから帰ってきたJSONを壊したりすることも出来るかもしれません。しかし、それは実際のAPIクライアントそのものに多くの”testing”コードを追加することであり、プロダクションでの使用において問題となる可能性もありえます。
これを解決するためには、通常のケースとエッヂケースをシミュレートすることが可能なAPIクライアントの別実装、つまりモックの実装を用いることが出来ます。
依存関係をモックするということは、テストされたコードの振る舞いを完全にコントロールするということであり、あらゆる種類のエッヂケースをより少ない労力でシミュレーションすることが可能になります。
モックは外見上は本物と同じように見えますが(実際に同じメソッドをexposeします)、実際には中身はなく、テストケースに必要な出力(normal output, slow output, error等)を生成するだけです。
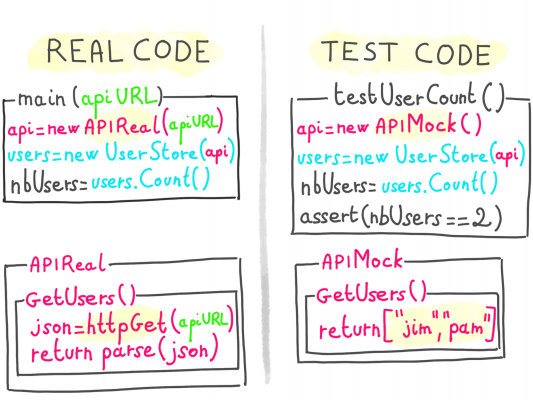
本物ではなくモックを受け付けるようにするためには、concrete typeのinjectを期待するのではなく、抽象化されているものを依存関係に定義すべきです。
この抽象化は、依存関係がどのような実装になっているか?という点は考慮にいれずに、依存関係が何であるか(すなわちメソッドのシグネチャ)に焦点を当てるものになります。
これを実現するためにサポートされている言語を使い、私たちは通常はインターフェースを使っています。
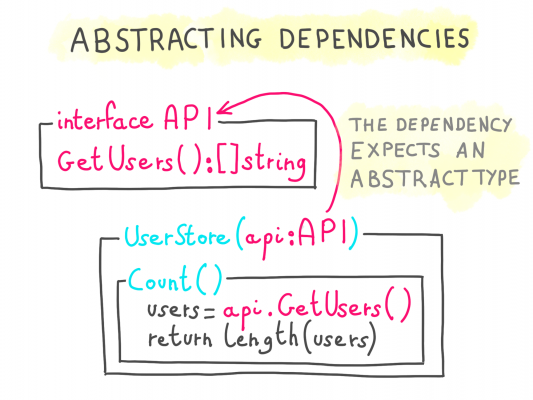
インターフェースはコードの中で実装を抽象化します。つまり、同じインターフェースに従っていれば、実装そのものは別のもので置き換えることが可能ということです。
Note: インターフェース(Interface)という用語を広く解釈されているように使っていますが、言語のAPIレベルでインターフェースや型付けをサポートしていない言語もあります。そういった場合はダックタイピングを用いてこの原則を適用することが可能です。
Usability
Before software can be reusable it first has to be usable.
Ralph Johnson – Programming Wisdom (@CodeWisdom) February 17, 2020, on Twitter
(ソフトウェアがre-usableになる前に、まずusableにしなければなりません)
Ok, それではtestableになりました。ではどうやってこれをusableに出来るでしょうか?
反復になりますが、コードのusabilityとは:
- maintainability 簡単にコードを変更したり修正したりできること
- composability (or re-usability) 簡単にパーツを構成する形で拡張できること
つまり、testableなコードを書くために取ってきた手法は、同時に、より使いやすいものであるということが分かりました。
Maintainability
Testabilityはmaintainabilityにとってhugeなwinです。テストによってコードベースに変更が入った際も、全てのテスト済みのケースが動作することが確認できるからです。
Single Responsibility Principle は:
– コードがアプリケーションのconcernsが正確にマップされた形で分割されていることを示します
- 全てのconcernが明確に識別可能であり、コードベースのdiscoverabilityが向上し、メンテナンスにおいても大きな助けになります。
- SRPは私たちのコードをHighly Cohesive and Lowly coupledにします
Dependency injectionは、APIが必要とする依存関係を明示することを保証します。ソフトウェアの依存グラフはコードのAPIを通じて可視化されるとともに、メンテナンスにも役立つと言えるでしょう。
抽象型(interfaces)を活用することによって、モックを依存するコンポーネントに用いることができ、よりクリーンで結合度の低いAPIが生成されます。これとSRPを組み合わせることで、抽象化された依存関係の実装の詳細を隠すことができるのです。なぜこれが望ましいかというと:
- これはInterface Segregation Principleに沿っていて、ソフトウェアの結合度を下げることに繋がる
- デルメルの法則(Law of Demeter)に沿っていて、ストラクチャーに関する事前知識なしに、usableな情報を提供することで、やりとりを行う部分の結合度を下げることができる
つまり、loose coupling(結合度を下げる)ことは、要件が変わった時にリファクタされるコードの量を減少させ、maintainabilityを向上させるということです。
Composability, (re-)usability
Composability: SRPとDIを併用することにより、互いに独立した機能として利用することが出来るため、既存のコードを活用して新しい機能をソフトウェアに組み込むことが容易なる、すなわちコンポーザブルなソフトウェアを実現することができます
Reusability: 依存度の低いパーツは、reusabilityを可能にします
Mock “unmockable” dependencies
依存の中には簡単にモックにできないものもあります。例えば以下のようなもので解決策とともにご紹介します。
抽象化するには広すぎる “open” なAPI問題
inputが非常に様々で、且つ、outputも幅広いようなメソッドを扱うかもしれません。例えば、GetTodos(additionalSqlFilter: string)のような場合。
では、additionalSqlFilterが取りうる全ての値をテストすることは出来るでしょうか?(恐らく難しいでしょう。あぜならこれはopenなAPIであるSQLに依存するからです)
これを解決するためには、依存関係を抽象化してカプセル化し、限られた数のメソッドをもつクローズドなAPIを公開する方法が考えられます。
上記の例の続きで考えるならば、データ取得のために必要な事前に決められたユースケースのみを公開する、ということです。例えば、GetAllTodos(done: boolean)そして、GetLateTodos(done: boolean)などです。
このパターンはData Access Layerと呼ばれていて、抽象化されたデータベースと他のqueryableなAPIとのやりとりをtestableに表現する方法として優れていると言えるでしょう。
抽象化するには扱うconcernが多すぎる問題
3rdパーティーの依存関係においては、異なるconcernsの用途で異なるAPIを公開することがあります。
コードの中で具体的な型としてそれらを使ってしまうと、コードが複雑になり、必要以上にモックを使ったテストが煩雑化することになってしまいます。テストされたコードの一部は、依存関係によって公開された全てのconcernを一度に使用していない可能性が高いためです。
SRPは全ての依存関係を単一のドメインに集約させることが解決策だとしていますが、自分たちでAPIを保持していない3rdパーティーの依存関係でこれを実現するにはどうしたら良いのでしょうか?
Algolia APIクライアントを例にしてみると、もし、あなたのソフトウェアが”Search”機能だけをつかているのであれば、”Search”メソッドだけを公開するインターフェースを持つクライアントを抽象化したいかもしれません。そうすることで良い副作用もあります:
- テストは、”Search”以外の別のメソッドを使用しないことを保証してくれる(インターフェースを更新しない限り)ので、必要なテストの設定を減らすことが出来ます。
- 検索のためだけにAPIクライアントを使っていることが明示されるので、インターフェースの名前を見るだけで責務が明確になります(例えばSearchClientといった名前がユースケースに合うでしょう)
もし、同じソフトウェアにindexを操作するような実装を追加する必要があるのであれば、”Search”と”Index”のconcernは異なるコンテキストで使用されるべきです。同じAlgolia APIクライアントを別のインターフェースのIndexerClientの下に”Index”操作のメソッドのみを含むようにしたいと考えるかもしれません。
この原則はInterface Segregation Principleと呼ばれています。
Isn’t this SOLID?
その通り!SOLIDの原則の中にはこの記事で紹介したものが含まれます。
SOLIDはこれらの原則をよりオブジェクト指向プログラミング(OOP)、例えば、Open-Closed Principle(まさーるさん訳: むすんでひらいての法則)に重点を置いています。
私は、SRP, DI, Abstraction, そしてMocking(もしくはそのサブセット)は、その言語がOOPであるかによらず受け入れることができると考えています。
また、、
It’s about controlling the code
最後に、testabilityに関するコードのデザインは、その振る舞いを詳細にコントロールすることを余儀なくさせます。これこそが、まさにコードを(re-)usableにするために必要なことです。
このようなトピックについてご質問や気になるところなどありましたら、Twitterの@jeromeschneiderまでご連絡ください。


コメント