最近 LegalForce にご転職された @moco_beta さんオーガナイズの #kuromoji のコードを読む会@サムライズムさんに参加させていただきました。なんと出席率100%ということで、素晴らしい!
発表資料は👇コチラ!
//speakerdeck.com/assets/embed.js
趣旨
例えば、普段ElasticsearchとかSolrとかを業務で使っている人が、実際のソースを読んだら役に立つと思うし、楽しいと思う!とのこと。
会場内アンケート
1/3〜半分くらいの参加者が形態素解析器や検索エンジンを作っている!凄い!
リポジトリのチェックアウト
現状Antだけど、あと数ヶ月くらい経つとgradleに移行される。antタスク(例えばant idea)はIDEで開けるようにプロジェクトファイルを作ってくれる。
Kuromoji
元々はMecabのクローン。AtilikaのkuromojiとLuceneのkuromojiは別のものなので注意。特徴としてはアナライザと形態素解析器が一つのjarに入っている。Kuromojiの場合は一個入れるだけで良いので、辞書だけ変えたいとか、そういうのは面倒。
Kuromojiの辞書は大きく2つある。
1. システム辞書。MeCab IPADICをバイナリエンコードしてリソースして組み込む。UniDicの方が再現率が高いのではという話もあるが、現状UniDicのビルドは壊れてる[LUCENE-4056]
2. ユーザー辞書。今回は割愛。
辞書引き
二段階になっていて、文字列→見出し語ID→単語エントリ
例えば、『東海道』を渡すと東、東海、東海道とそれぞれで単語をゴッソリ抽出するようになっている
Kuromojiの辞書
– 見出し語
単語エントリへのポインタを取得。連想配列的な。
文字列のマッチングはオートマトンになってる。
– 単語エントリデータ
辞書をバイナリエンコードして単語には内部ID
– データ構造はトライ木に似てるが木構造ではない
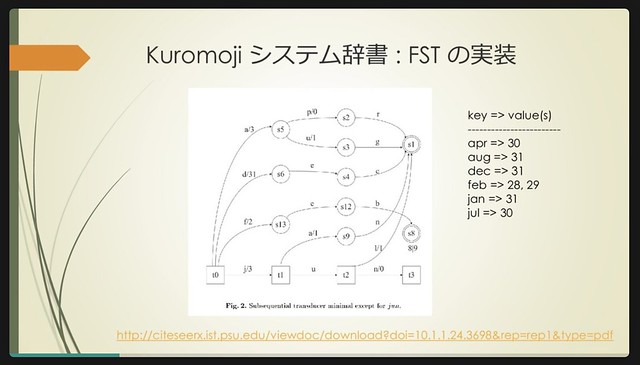
– FST
1回の辞書引きでゴッソリ持ってこれる(👆の東海道の例を参照)
東海道なら、東海道 / 海道 / 道 の3回辞書を引けば良い
kuromojiの入力単位は2バイトchar。サロゲートペアがあると4バイトなので2回
👇は例。kuromojiのFSTは8|9みたいなデータの持ち方はしないようになってる、とのこと(1つしか返さない)
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
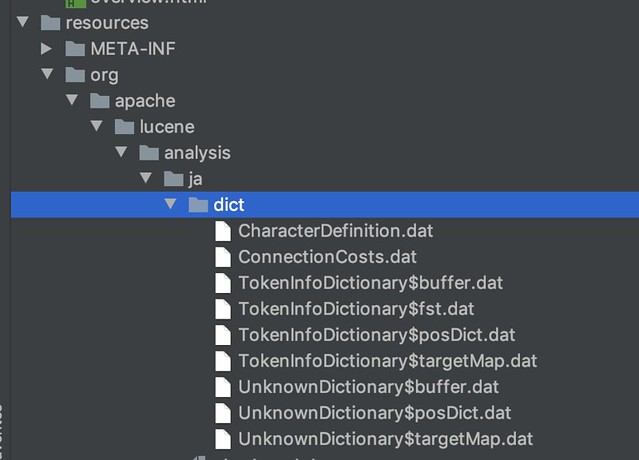
– Kuromojiの辞書はエンコード済みのバイナリ(datファイル)が入ってる
👇この辺ですかね〜
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
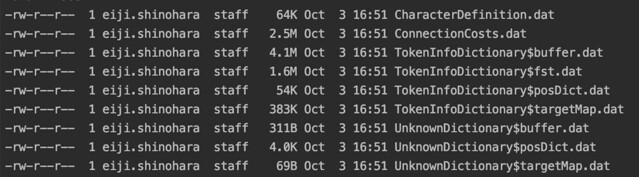
👇サイズを小さく出来ているには魔術がある、とのこと
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
辞書圧縮に関するソースリーディング
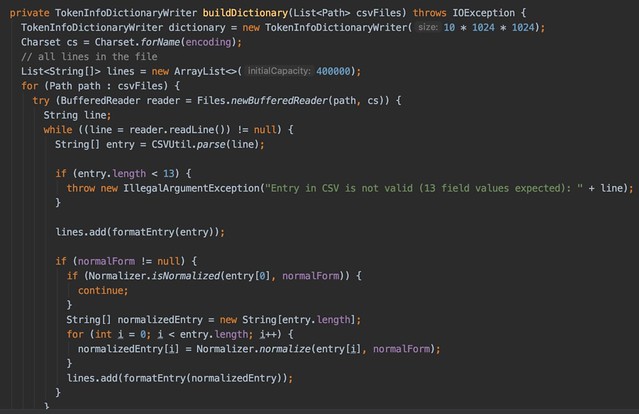
TokenInfoDictionaryBuilder。👇ここを読むと大体何やってるか分かるはず
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
見出し語検索 fst.Builder&fst.FST
KuromojiはAnalyzer。o.a.l.util.fstそのものはsuggesterとか色んなところで使われている。
TokenInfoDictionaryBuilderの99行目〜。PositiveIntOutputsは符号なしのlongらしい。
Builder.addでオートマトンに追加していく👉fstBuilder.add(scratch.get(), ord)
# オートマトンの構築の詳細を追うのは大変らしい…。論文読んでアルゴリズムを理解してからじゃないと、、、
有向グラフのArc(弧)をシリアライズする(逆側からエンコードしている)
フラグ: 1byte
ラベル: 2byte
出力: variable length
ターゲット: 後ろからエンコードすると遷移先は分かってる
ラベルは、int(4バイト)をshort(2バイト)にキャスト。
アウトプットは、long(64bit/8byte)なので可変長のバイト配列に変更している
→longの場合は上位は大抵ゼロなので上6バイトを全部ゼロにしてる
復元する場合は先頭1ビットが1だったら続きがあるけど、0だったらそこで終わり、とか。
一般的な圧縮テクニックと言えるらしい。
書き出しは TokenInfoDictionary$fst.dat。1.7MB
# FSTのコードを追っていくと、なかなか理解が難し気なコメントが続いたり、
# コメントアウトされたSystem.printlnが沢山あって、
# SIerに居た頃の自分を思い出しますヌ…
単語エントリ
BinaryDictionaryWriterで単語エントリをエンコーディングしている
→put()とaddMapping()の2つのメソッドが重要。
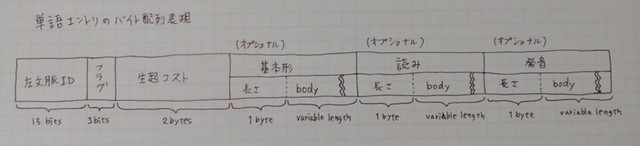
Mecabu IPADICは左文脈IDと右文脈IDが同じなので左文脈IDと右文脈IDがいつも同じとして扱っている。しかし、この構造の図はとても分かりやすい!
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
CSV: 立ち止まら(表層形)、基本形(立ち止まる)
→4(共有接頭辞長)、1(接尾辞長)、る(body) というシリアライズ
基本形の長さが16文字超えるとIllegalArgumentException…
読み: Mecabu IPADICは読みは全てカタカナ
→Unicodeだと30A0から30FFまで⇒なので30は削れる⇒1バイト(半分)でOK
発音: 大体読みと同じ。ちょっと記号があったりするけど、一緒だったら保存しない
強引とも思える圧縮によって、今の小さいサイズbuffer.datの4.2MBが実現されている
デコーディング
エンコーディングが分かってれば、、っていう話だけど、デコーディングもややこしい…
それでもファイルサイズを小さくすることが大事。
👇Javaとは何か、みたいなコードが出てきたり。笑
https://github.com/apache/lucene-solr/blob/167c65afadc164beb870337a1076ef146387b55d/lucene/core/src/java/org/apache/lucene/store/DataInput.java
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
—-
いやー、大変勉強になりました!ありがとうございました!!
ハードルたけぇぇぇええw