
こないだTomcat7にSolr3.5をインストールしてみましたが、
今回は検索の精度を高めると言いますか、
– 要らんのが検索で引っかからないように取り除いて、
– 意図が同じなのは検索で引っかかるようにする。
なんていう事をしてみようと思います。
■ StopFilter
stopwords_ja.txtでは以下のようにいれてみました。
# Standard english stop words taken from Lucene's StopAnalyzer する ます た だ です ある いる は を 。 、
schema.xmlは、、
<fieldType name="text_ja" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.JapaneseTokenizerFactory"/>
<filter class="solr.StopFilterFactory" words="stopwords_ja.txt"/>
</analyzer>
</fieldType>
“私は眠いです。”とかってのを食わせてやると、

“私” “眠い” ってなってくれたりしてイイ感じです。
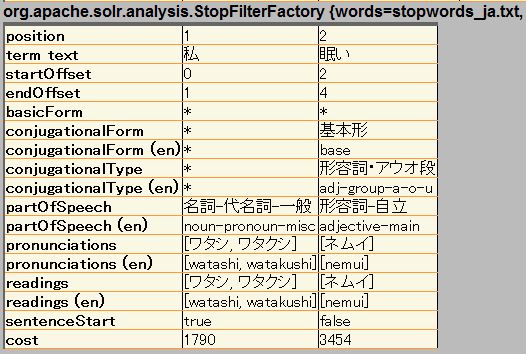
他に要らないのを食わないようにするために、POSFilterFactoryっていうフィルタを使って
pos-deny.txtに定義した特定の品詞を食わないように出来たりします。
■ JapaneseBasicFormFilter
曲名が”会いたかった” なのか “会いたい” なのか、、みたいな歌を検索したいとします。
んま、どっち入れても引っかかって欲しいですよね、と。
schema.xmlは、さっきのstopとあわせて↓以下のように設定します。
<fieldType name="text_ja" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.JapaneseTokenizerFactory"/>
<filter class="solr.StopFilterFactory" words="stopwords_ja.txt"/>
<filter class="solr.JapaneseBasicFormFilterFactory"/>
</analyzer>
</fieldType>
以下のように”会いたかった”でインデクシングして、”会いたい”で検索したとします。

結果は”会う”と”たい”でマッチしました。

“たい”の助動詞はPOSFilterで落としちゃってもイイかなぁというような気がしますが、
とりあえずやりたかった事は出来ました。
■ SynonymFilter
“マクドナルド”の事を、関西の人は”マクド”って言ったり、関東の人は”マック”って言ったりしますが、
どれでも、引っかかって欲しいところだと思います。
あとは、”Google”と”グーグル”って同じ事指してるよね、と。
synonyms-ja.txtに以下のように書きこんで、
(マクドナルドは展開。Googleは寄せる。)
マクドナルド, マック, マクド Google => グーグル
schema.xmlは更に追記する感じで、synonyms-ja.txtを指定してやります。
<analyzer>
<tokenizer class="solr.JapaneseTokenizerFactory"/>
<filter class="solr.StopFilterFactory" words="stopwords_ja.txt"/>
<filter class="solr.JapaneseBasicFormFilterFactory"/>
<filter class="solr.SynonymFilterFactory" synonyms="synonyms-ja.txt"/>
</analyzer>
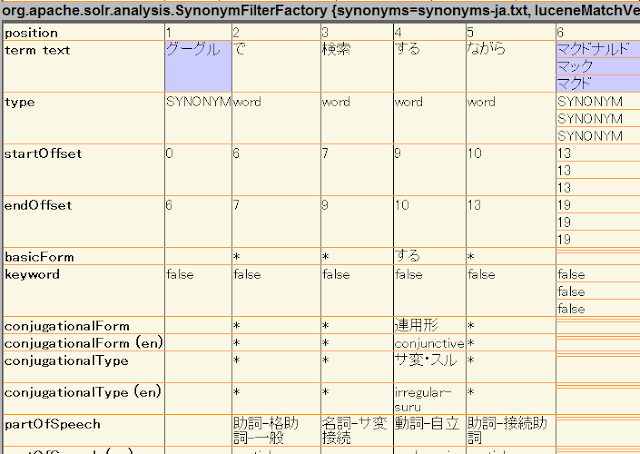
あんまり良い例か分かりませんが、”Google”と”マクドナルド”という単語が入った文字列をインデクシングして、
“グーグル マック”というキーワードで検索してみます。

結果は狙ったように↓検索出来ました。
他にも、カタカナの最後の”ー”を取るとか、ケースインセンティブにするとか、
追加すべきフィルタはチョコチョコありますが、基本的には上記のような感じで試しながらやってみる、と。
ただ、一回インデクシングしちゃった後に、ファイルに何か足すとかなると、もう一回インデックス作りなおしかよ的な
感じになってしまうところもあったりして、運用も想定した上で構築していかなきゃならんなぁと。
にしても、ほんとSolr使いには↓バイブルだな…。

技術評論社
売り上げランキング: 19771


コメント