
ビッグデータ分析・活用のためのSQLレシピを読みました。
この本について一言で言えば”圧倒的な現場感”!日頃の業務の中で溜め込んだノウハウが惜しげもなく記述されている神SQLの数々。これが数千円で手に入るなんてお得過ぎる…と思える一冊でした。久しぶりにポストイットがフッサフサになってしまいました。笑
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
『Chapter 1』ビッグデータ時代に求められる分析力とは
2005年の”Google Analytics”の登場から、変遷を経てビッグデータが脚光を浴びるようになってきた背景について。私個人としても2005年くらいにGmailやGoogle MapsといったいわゆるWeb2.0に触発されて、ウェブ進化論 本当の大変化はこれから始まる等を読み漁った結果、新卒入社したSIerから、2007年にインターネットサービス企業に転職しました。そこでまさに求められていたものは↓の”本書で実現したいこと”で記述されているエンジニア像であり、今はソリューションアーキテクトとして様々なエンジニアのお客様と接していますが、それは10年経った今でも全く変わっていないものだと思います。
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
『Chapter 2』本書で扱うツールとデータ群
この本の凄いところは、レシピの中で PostgreSQL, Apache Hive, Amazon Redshift, Google BigQuery, SparkSQL それぞれの場合の記法やユースケースを抑えているところになりますが(かなりの労力だったと想像します)、この章では、各データベースの特徴について触れられています。そしてトランザクションデータ、マスタデータ、ログデータ、、といった形でカテゴライズすることで分析業務を行っていく上でのポイントがまとめられています。
『Chapter 3』データ加工のためのSQL
私はJavaやRubyなどを書いていたプログラマだったので(いや、集計処理は生ログからsedとawk使うことが多かったかな…)、今までプログラムを書いて実装してきたような処理についても、本書では”SQL一発で仕留める”形になっています。そのことは非常に価値があることだと思っていますが(例えばJavaの開発環境整えてjarファイルデプロイして〜っていうのはハードル高い…)、SQLの中でプログラマブルなアプローチをする必要性がでてきます。この章では、文字列操作、日付データの取扱い、値に0が入る可能性がある場合の割り算、数学的なアプローチのための平方根といった、”こうやってやるんだ!”的なTIPSの連続です。しかもそれが上記のように様々なデータベースそれぞれについて記載されています。
そして何よりウィンドウ関数について。集計系の処理には必須であると思いますが、非常に丁寧に記載されています。WHERE句でウィンドウ関数が使えなくて悶絶した、、みたいな経験のある方は是非。
また、現場においては、”xxとxxのデータを集めてきて、xxなテーブル作れればイイのにな…”なんていうのはよくある話で、でもテーブル作成権限はDBAの人にしかない的なあるあるが存在すると思いますが、そういった課題に対する解決策も提示してくれています。
『Chapter 4』売上を把握するためのデータ抽出
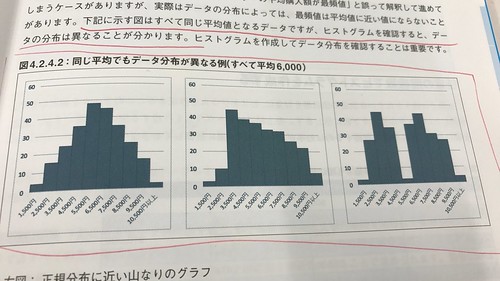
いよいよ分析業務の話になっていきます。移動平均、Zチャート、イケてるヒストグラム、、といった人に見せるための集計を行うためのTIPSがギッシリ詰まっています。UNION ALLはかく使うべしとか、FIRST_VALUE関数とか、こういうのは業務の中でよく出てくるところだと思うので。↓この辺とかホントそうだよね、と。
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
『Chapter 5』ユーザーを把握するためのデータ抽出
ユーザーの行動やデモグラの属性を〜とかっていうのは、広告・マーケティング系のお客様とお話をする際によく出てくる話題ですが、この章はまさにそれ。その中で、例えばROLLUP句に対応していないデータベースについてはUNION ALLを使ってこのように〜みたいのは、刺さる人には激刺さりなのではないかと思いますし、業務的なユースケースと、動くSQLが記載された上での説明となっているので、非常に内容が理解しやすいです。このレベルを英語で理解するのは本当に骨が折れるような思いを日頃することがあり、特にRFM分析のところなどは今まで読んだどの文献よりもバッチリ頭に入ってきました。
『Chapter 6』Webサイトでの行動を把握するためのデータ抽出
もうSQLがあれば、Google Analytics要らないじゃん的な章。ひたすらほえぇ〜と思いながら読み進めていましたが、この本のアプローチの好きなところは、ドヤッ!というところで終わらせずに、キチンと地に足が着いた現場での知見ドリブンになっているところ。
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
それにしても、印刷した紙のレポートを折って〜なんていうのは、やってる人ならでは感がハンパない。
『Chapter 7』データ活用の精度を高めるための分析術
マスタデータどうする?とか、日本の祝日っていうのをシステムで取り扱おうとすると、どうしたらイイの?っていうところからはじまり、要らないデータを取り除いたり(botのアクセスログとか)といったテクニックが網羅されつつ、ランキングの類似度の計算といったアドバンストな内容にまで踏み込んでいます。スピアマンの順位相関係数をSQLでといったところも、”理想的なランキングを人手で作成”して、自動生成したランキングにどれだけ近いか定量的に評価しましょう、なんていうのは極めて実践的だと思いました。
『Chapter 8』データを武器にするための分析術
お仕事でAWSの検索エンジン関連のサービスを担当していることもあって、この章はグサグサきまくりでした。まさに検索の精度を上げるために運用現場で行われていることが、コンパクトで且つ非常に明瞭に述べられています。検索はニッチな分野で日本語の文献も多いとは言えないところもありますが、この検索のパートだけでも一読の価値ありです。
そしてレコメンデーションから続く、スコア計算におけるシグモイド関数の使い方、標準偏差や偏差値の求め方などなど、もうお腹いっぱいです。笑
『Chapter 9』知識に留めず行動を起こす
こういうアプローチで現場でお仕事されているのだな、という実は惜しげもない情報共有な章。俯瞰的な視点にグサっときますし、誰のために、とか、何のために、とか、その辺をブレずに行こうぜ、というのは本当にその通りだと思います。
田宮直人さん
この度、こちらのマイナビ出版様の本は著者である田宮直人さんからお声がけいただいて献本いただきました。
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
田宮さんとは、私が広告ネットワークのシステムを開発していた頃からの旧知の友人で、その当時はお互いWeb系のエンジニアでした。田宮さんがビッグデータを扱う分析屋さんとしてWeb上で連載されている記事などはチェックしていましたが、ここまでの本を書き上げられたということは、インプットを重ねて、現場でアウトプットを出しながら、努力をされ続けてきたことの結晶だと思いますし、まさに”データを扱う職人”になられたのだな、と。
私の場合、例えばAmazon Redshiftであれば、大量のデータを投入した時に、いかにノードをまたがないでJoinさせるか?といったアプローチでのテーブル設計のお手伝いや、高速に集計するための圧縮フォーマットやアルゴリズムのご案内等をすることはありますが、こういった現場の実務からはここ数年遠ざかっていることもあり、楽しく勉強しながら読み進めることができました。本当に献本いただけてラッキーだったので、田宮さん、今度いっぱい奢らせてください 😀

売り上げランキング: 2,469


コメント