
Lucene/Solr Revolution 2016の2日目。
■ Breakfast
朝ごはんも美味しかったわ〜。いきなり白髪のオッサンに声かけられて何かと思ったら、以前CloudSearchの開発に携わってた、と。今は検索技術系のコンサルをやっててボストンに住んでるそうで。カンファレンス期間中はずっとCloudSearchのパーカーを着ていたのだけど、こういう場では服装も大切なのだな、と。
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
■ Keynote
CTOのGrantさんが仕切り。今日の夜帰る人はシェラトンに滞在してなくてもカバンはシェラトンのコンシェルジュに預けられるよーとか、夕方のキーノートは気合い入れて準備してきたから出てね、とか。
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
CommvaultのRajivさん
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
エンタープライズバックアップっていう領域では有名な会社なのですね。メールをバックアップしてoutlookのビューでそのまま過去メールを検索して参照できる的なデモとか便利そうでした。
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
続いてSalesforceのCathyさん
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
私も業務でSFDCをガッツリ使ってますが、そりゃ裏側大変だろうなって感じですよね、、
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
いろんなデータあるし、
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
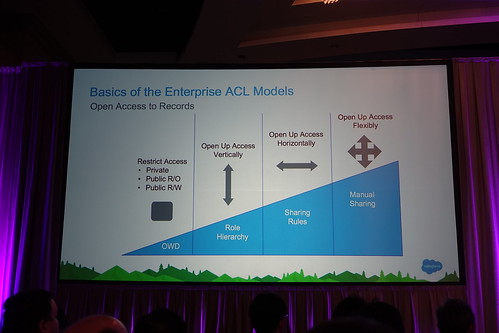
この人はアクセス許可するけど、この部門の人はーとかそういうのをエンタープライズ領域ってキッチリやらなきゃいけない。
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
元々はLucene使ってスケールアップな戦略で高価なハードウェアでオリャっとやってたのを、Solr使って水平分割してコモディティなハードウェアでっていうアプローチ。
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
Phase1。この辺はブースでも少し話きかせてもらったんだけど、自前でSolrの外でゴリゴリやってクラスタ頑張ります的なアプローチ。
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
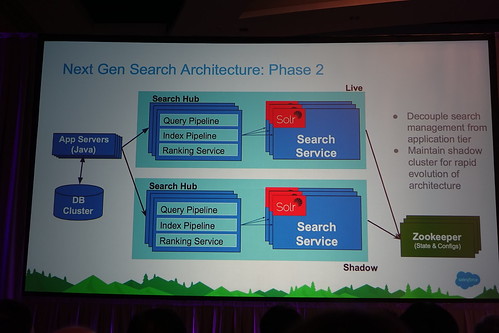
Phase2。Zookeeper自分たちで頑張るよ、と。ブースで聞いた話だと、彼らがこの辺に投資はじめた頃はSolrCloudってまだちょっと、、な感じだった、と。稼働系と諸々変更を加えて行く系に分けて、両方にデータを突っ込む。shadowが稼働系よりイイ感じなクオリティになったら稼働系に。
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
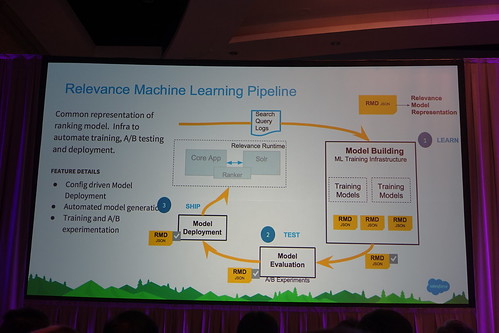
そして機械学習の技術を使って検索の質を向上させていくアプローチ(このカンファレンスは本当にこのアプローチな話が多かったと思います)
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
そして続きは午後のブレークアウトセッションで〜って言われたら、出なきゃいかんがなって気分になりした。
■ Using a Query Classifier to dynamically boost Solr
TargetのHowardさん。このセッションは個人的に今回のカンファレンスで一番印象に残ったというか、ベストなトークでした。とにかくガチな本番での検索の質の向上度合いが素晴らしい。ただ、こういうアプローチを知らなかったのか?って言われれば、そうでもないような気がするけど、実際にここまでの結果を出せたことがないから憧れるわーっていう、そんなセッション。
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
私はHowardでHowじゃないんですけどねーなんていう、割りといちいちウケを取りにいこうするプレゼンスタイル。
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
なんで分類しなきゃいけなかったのか、と。Targetって幅広くいろんなものを扱ってる。アーモンドって言っても、チョコレート/家具/ミルク/キャンディ、、っていう感じ。
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
例えば、何もしないで”7リングなバインダー”とかって検索すると、バインダーより指輪の方が上に出てきちゃったり、elongatedなトイレのトイレカバー探してるのに、、とか、ゼロ件ヒットになっちゃうクエリとか。
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
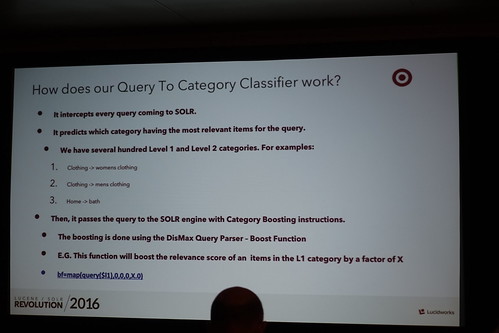
きちんとカテゴリを引き当てて、精度の高いものを返せるようにしようというアプローチ。そしてDismaxでブーストしてやる。
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
つまりこういうことよ、と。
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
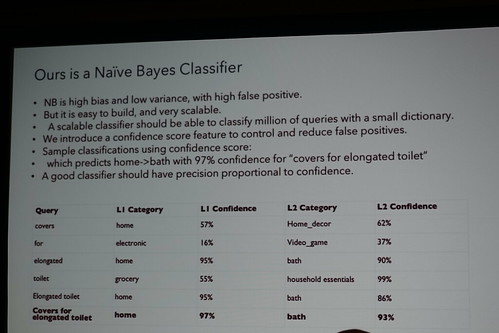
単純ベイズ分類器ってヤツっすねー。簡単にビルドできてスケーラブル。
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
評価はNDCG(Normalized Discounted Cumulative Gain)
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
んでもって、ドヤァ!ってヤツですね。
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
Alarm Navigationで1件もヒットしなかったヤツは単語をバラして検索して分類してっていうアプローチ。
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
辞書は全部シングルワードで定義してて、たった100万語。小さいよね、と。でもって、機械学習のアプローチも取り組んでいるけど、現状は人間がrelevanceを…と。(会場はWowと苦笑いの共存というか…)
こういう話を聞くと、諸々汎用化した形でフルマネージドなアプローチでクラウドサービスで提供できたりしないかなって妄想が膨らんだりします。
■ The Evolution of Lucene & Solr Numerics from Strings to Points
LucidworksのSteveさんの話。内容難しそうだったけど、せっかくボストンまで来たんだし、一個くらいこういうセッション出ておこう、と。
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
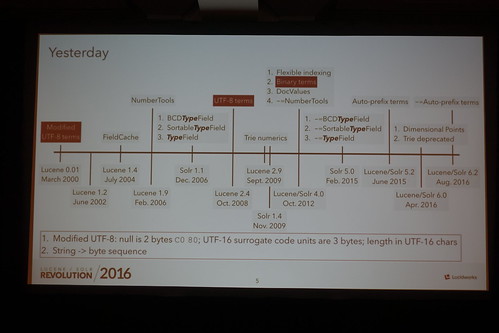
年表にそって今までの歴史を振り返りつつ、今後の模索。Luceneが始まった頃はModified UTF-8だったけど、Trie numericsでレンジクエリが早くなったとか、DocValuesでOSのキャッシュにスワップアウトしたとか、Auto-prefix termsって知らなかったけど5.2で入って6.2で削除されたのとかあるらしい。
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
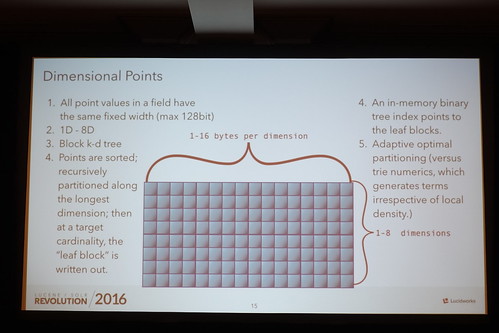
Dimentional PointsはまだLucene Only。SolrはAWSのTomasがやってる、とのこと。
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
こっからはユースケースとかベンチマークの話でした。
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
■ Lunch
毎食ホントに素晴らしい。前日のパーティーで仲良くなったAzureでAzure Searchの開発エンジニアをしているSeattle在住で、以前日本にも住んでたことがある韓国人のNateってヤツと仲良くなって色んな情報交換ができました。 #solrjp でも登壇してたMonotaROの久保さんともお話できました。
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
■ Customizing Ranking Models in Solr to improve relevance for Enterprise Search
Salesforceでの検索のRelevancyのお話。Joeさん(写真)と、Ammarさん。
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
3Tierでこんな風にやってますよ、と。L0:Similarity⇒L1:Attribute(Document/User)⇒L2:Aggregation(ランキングを計算してソート)
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
元々は検索エンジンはSimilarity(L0)のみ
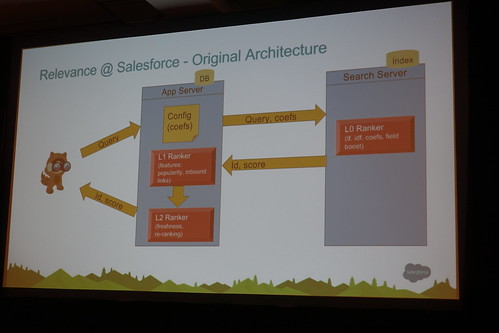 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
L1まで検索エンジンでやりくりするように
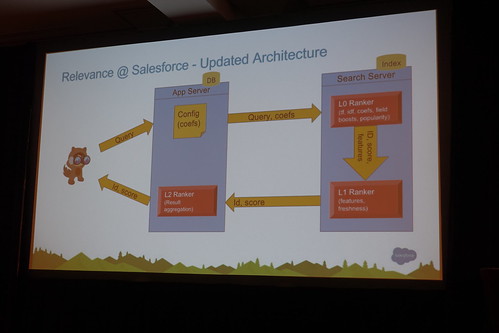 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
L0は一般的なTF-IDFとDixmax Query Parser。Solr本とかに載ってそうなヤツ。
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
L1はL0でヒットしてきたものを独自のコンポーネントで〜
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
SolrのSearchComponentを継承して独自のものを組み込む
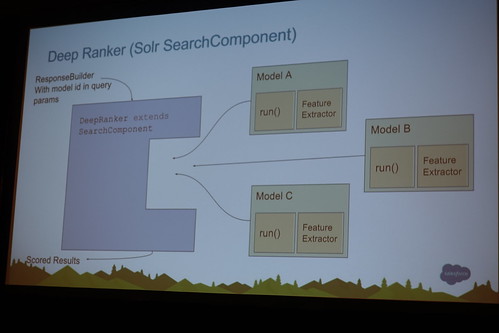 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
こういうデモみせてもらえると腹落ちするし、
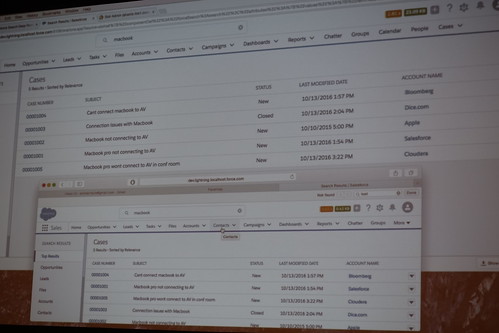 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
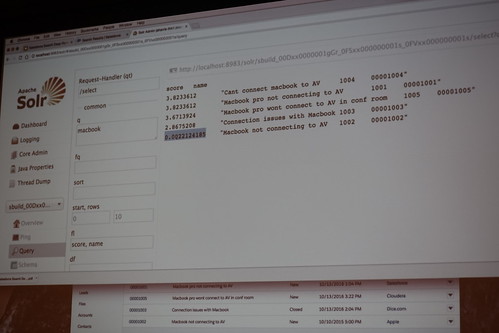
馴染みのあるSolrのコンソール
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
そして詳細をAmmerさんから
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
日本にはチーム無いって言ってたけど、1ユーザーとしても今後これからどう成長していくのか楽しみですね〜
■ Reflected Intelligence: Lucene/Solr as a self-learning data system
前日のKeynoteにも出てきたLucidworksのTrey Graingerさん。今後の方向性とか知るためにもこの人の話は聞いておきたかった。題名からしてNext感あるやね、と。
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
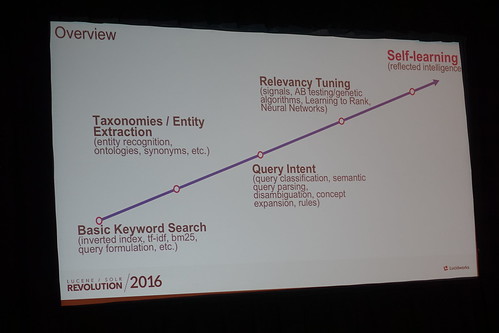
これからは検索エンジンがSelf-Learningしていく時代だぜ、と。いきなりドーンw
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
そこに辿り着くまでの要素技術たち
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
こういうサイクルをグルグル回して検索の質をどんどん高めていく。
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
DiceのConceptual Searchって初耳だったけどシノニム辞書をホゲホゲしてくれるらしい
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
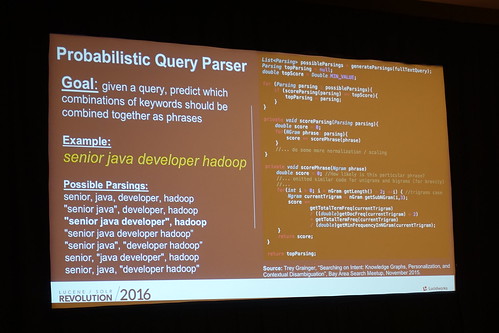
『senior java developer hadoop』って出てきたらどこで区切るか問題。“senior java developer” と “hadoop” なわけですけれども。他にもruby on railsだったら〜とか。
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
辞書だけでなくstatisticalな〜っていう
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
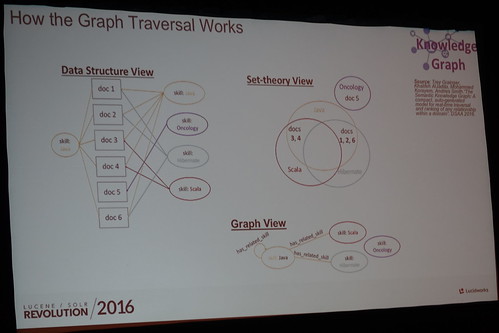
言葉同士の関連はグラフDBなヤツ
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
この辺のスコアリング話は興味深いですなぁ
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
ドライバーって言っても、運転手の場合もあるし、Linux用のドライバとか、JDBCドライバとか。
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
ログデータからホゲホゲする。こういうのの構築とかエンハンスメントは興味あるなぁ、、
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
この人の話はいつもロジカルで語り口調も分かりやすいし、今回も勉強させていただきました
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
■ Your Big Data Stack is Too Big
最後のブレイクアウトセッションもCommitter Talkに参加。LucidworksのTimothy Potterさん。
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
FusionのTweetしてくれれば本プレゼント!っていう(私は荷物増えるのイヤなので…w)
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
Sparkを使ってデータを高速にIngestとかってのも最近いろんなところでよく聞く感じになってきました。
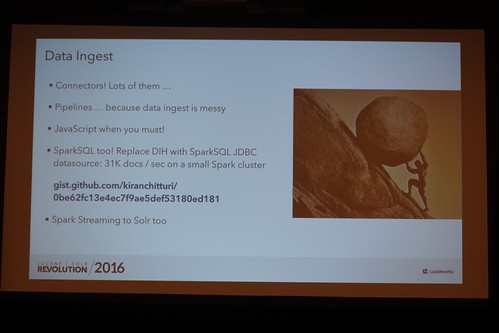 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
いろんな頻度でいろんなやり方でのアクセスへの対応が求められる
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
Solrの中はTieredな感じになってるよ、と。SQLを解釈して、Workerに渡して、それをData nodeに
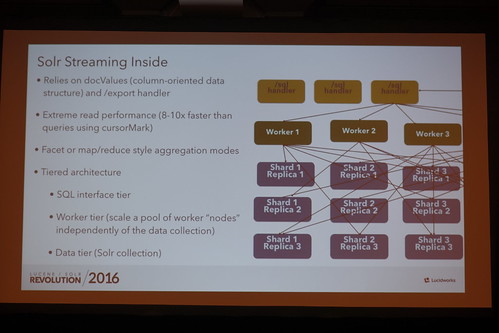 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
ZeppelinからならJDBCで簡単にアクセスできる
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
HiveのクエリでSolrのドキュメントもSQLを使ってHDFSのデータとjoinできちゃうのドヤァ的な
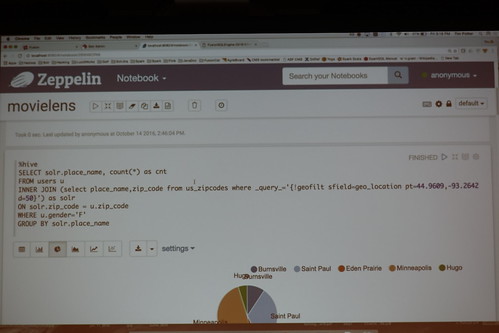 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
Fusionが何をどこまでやってくれるのか未だに分かっていませんが、、、
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
Grantさんが前日のセッションで言ってたSearchHubの話
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
クロールして取り込んだTweetデータから上記の書籍プレゼントな人をSolrのコンソールから検索してww
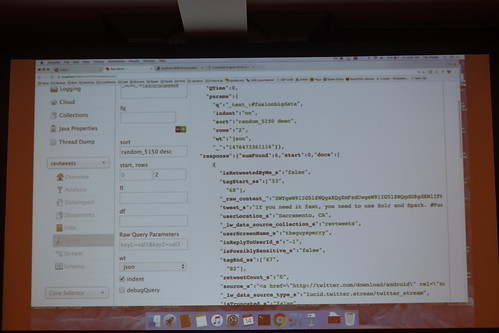 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
■ Closing Keynote
CTO Grantさんおクロージングキーノート
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
エモいお話を、、
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
たくさんの絵文字を使って。この人の話は力強くていつも楽しみ。今回も日本帰ったら頑張るべかなーって気分にさせてくれるお話でした 🙂
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
—
今回も大変勉強になりました。少しでも雰囲気とか最近のSolr界隈どうなの?って辺りが伝わるとイイなーと思ってブログ書かせていただきましたmm

Oreilly & Associates Inc
売り上げランキング: 346,371


コメント