Amazon CloudSearchは2014年3月から日本語がサポートされましたが、
Analysis SchemeでJapaneseを選択した場合、形態素解析のみとなり、
N-Gramがあるとイイのにな、と思う場合があります。
Analysis Schemeには”Multi Languages”というオプションがあるのですが、
先日、こちらを選択することで、N-Gramに該当する検索が実現できるようになりましたので
さっそく試してみたいと思います。
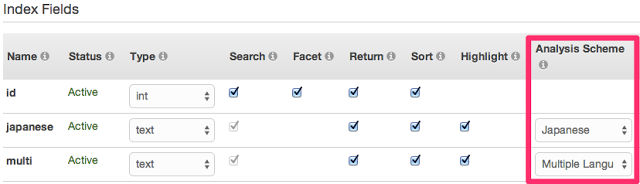
■ Japanese(日本語形態素解析) と Multi Languages(N-Gram) の 2つのフィールドを定義します。
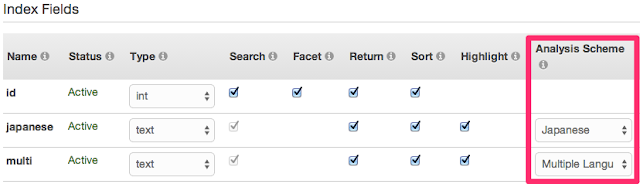
■ それぞれのフィールドに都道府県の名称を入れてみます

■ Japanese(日本語形態素解析) を “京都” で検索してヒットするのは “京都府” のみになります。

■ Multi Languages(N-Gram) を “京都” で検索してヒットするのは “東京都” と “京都府” になります。(スコア同じ)

■ カレット(^)で Japanese(日本語形態素解析) を重み付けしてみます。(デフォルト値は1なのですがjapanese^5にしてみました)

■ わざわざ2つデータを突っ込むのは面倒です。
CloudSearchには”Source Field”という機能があるので、
↓のように設定することで、 Japanese(日本語形態素解析) のデータを copy_multi(N-Gram) にコピー出来ます。

■ copy_multi(N-Gram) は上記の multi(N-Gram) と同様の振る舞いをします。
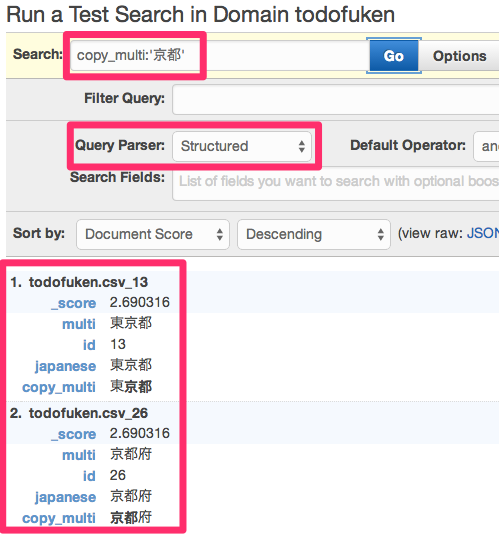
■ Japanese(日本語形態素解析) と copy_multi(N-Gram) を組み合わせてキャレットの重み付けももちろん可能です。

CloudSearchはon goingなプロダクトで、今後も機能追加が沢山予定されております〜 🙂
@imai_factoryが著者の一人の↓オススメです(*´∀`*)

日経BP社
売り上げランキング: 941

コメント