
こちらは Algolia Co-founder CTOのJulien LemoineがHigh Scalabilityに寄稿した Scaling Indexing And Search – Algolia New Search Architecture Part 2 の翻訳です。
全く新しいサーチエンジンのアーキテクチャとはどのようなものでしょうか?AlgoliaのCo-founder CTOのJulien Lemoineが検索の未来がどのようになるかを説明します。この記事はシリーズの第2回目となっており、パート1の翻訳記事はこちらになります。
検索エンジンはReadとWriteの両方のオペレーションにおいて、高速なスケーリングをサポートする必要があります。ほとんどのユースケースで迅速なスケーリングは無くてはならないものと言えます。例えば、マーケットプレースにベンダーを追加した場合、Indexingオペレーション(Write)が跳ね上がり、マーケティングキャンペーンを行う場合、クエリ(Read)が跳ね上がります。ほとんどのユースケースにおいては、ReadとWriteの両方のオペレーションがスケールアップするわけですが、それは同じ瞬間に同時にスケールするわけではありません。ほとんどのユースケースにおいては、ReadとWriteオペレーションのスケーリングは時間の経過とともに変化をするため、アーキテクチャはこういった状況を効率的に管理する必要があります。
現在まで、検索エンジンは、ReadとWriteオペレーションを同一のVM上に配置してスケーリングしていました。このスケーリング方法には、WriteオペレーションがReadのパフォーマンスを不用意に低下させてしまったり、Indexing時に重複してCPUを大量に使用するといった欠点が存在します。こちらの記事では、これらの決定をご説明し、ReadとWriteのオペレーションを分割することで、より迅速かつ効率的にスケールアップする新しい方法をご紹介します。
1. Indexの解剖学
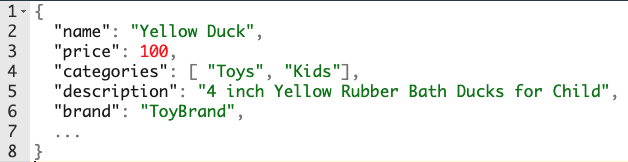
検索エンジンはリレーショナル・データベースと共通点は多いものの、データの表現方法は異なります。検索エンジンは、相互に接続し合ったテーブルではなく、フラットなオブジェクトを保持します。例えば、リレーショナル・データベースは、eコマースのユースケースの場合、複数のリンクされたテーブルを介して商品を保存します。図1はeコマースプラットフォームに格納されているシンプルな商品の例です。

データベースと比べて、検索エンジンは商品情報をフラットにして、全てのプロパティを1つのレコードに配置します。先程の例では、検索エンジンは2つの異なるオブジェクトを使います。1つは英語の情報を全て含むオブジェクトで、products_enインデックス(図2)、もう1つは中国語の情報を全て含むオブジェクトでproducts_cn(図3)です。
このフラットな表現によって、検索エンジンはインデックスを複数の独立したデータセットに分割することができます。必要な情報を全て含むオブジェクトは、これらのデータセットのうち1つだけに配置することができます。この特性によって、検索エンジンは1つのインデックスをN個の小さな独立したスペース(シャードと呼ぶ)として表現することが出来ます。このモデルによって、大部分のReadとWriteのオペレーションを並列に行うことができ、パフォーマンスが向上します。

検索エンジンのスケールを理解するためには、Indexingのフェーズで使われるCPUについて知ることが必要です。検索エンジンでは、データ構造の更新が行われる前に多くのデータ処理がなされます。それぞれのレコードは、words/entities/categoriesを認識するために処理されます。例えば、中国語では単語の間にセパレータがないため、機械学習モデルを使って単語を識別します。各単語は転置リストのデータ構造を更新します。また、検索パフォーマンスを最適化するためにIndexingの際にランキング計算のスタティックな部分を事前に行っているような検索エンジンもあります。検索エンジンがベクターベースのインデックス、大抵の場合はセマンティックIndexingや画像Indexingなども計算するような場合、IndexingのCPUの消費は更に顕著になります。つまり、検索エンジンのIndexing用のCPUがボトルネックとなってしまい、Indexingプロセス全体の速度低下を招く可能性があるため、Indexing用のCPUを分散させておく必要があるのです。
2. 一般的なスケーリングのパターン
多くのリレーショナルデータベースや検索エンジンのアーキテクチャは、より多くのReadオペレーションをサポートするための典型的な共通のパターンがあります。より多くのクエリをサポートするためにデータのコピーを行い異なる場所に配置します。例えば、3台のサーバーに3つのデータのコピーがあるとして、この場合、1つのサーバーに1つのコピーのみの場合と比較すると、3倍のクエリを処理することができます。より多くのWriteオペレーションをサポートするために、データをシャードと呼ばれる小さいピースに分割し、これらのシャードを構築するためにCPUを追加します。つまりReadとWriteの両方の処理をスケーリングさせるには、シャードを追加し、複数のマシンに複数のコピーを持たせる必要があるということです。
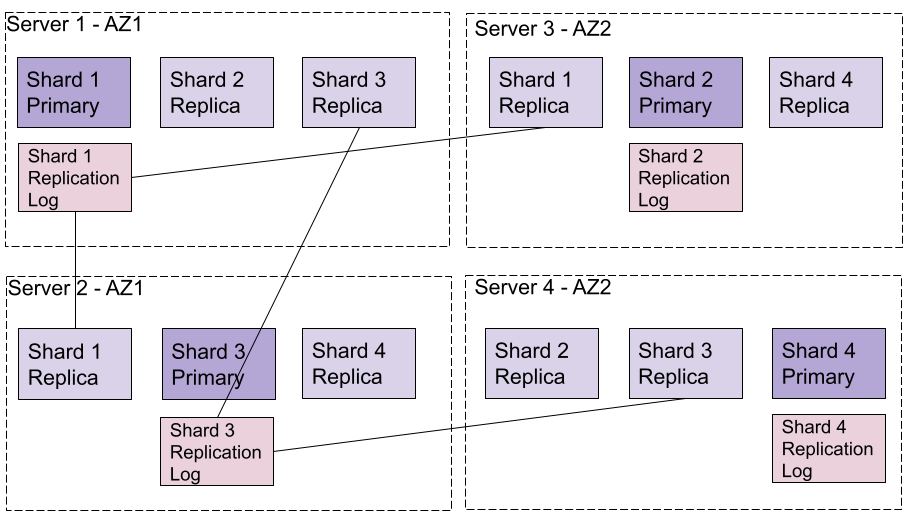
このロジックを実装するための主な仕組みとしては、primary/replicaアーキテクチャで、プライマリのデータを複数のレプリカにレプリケートします。データをレプリケートするには、各シャードにWriteオペレーションを受け付けるバージョンが1つ必要です(the primary)。他のバージョンのシャード(N個のレプリカ)は、プライマリシャードをsource of truthとして使用します。プライマリシャードとレプリカの間でデータを同期させる仕組みの多くは、プライマリシャードにあるログファイルです。このログ・ファイルには、プライマリシャードが受けた全てのWriteオペレーションがシーケンシャルに記録されています。各レプリカシャードは、このログからWriteオペレーションを読み取り、自分のローカルに適用します。図4は、それぞれが2つのレプリカを持つ4つのシャードのインデックスにおけるリンクを表しています。
このアプローチの欠点としては、Indexingと検索を同じマシン上でコロケートしていることです。これはデータの複数のコピーを構築する必要があり、Indexing用のCPUとメモリが重複してしまうことを意味しています。Readオペレーションだけが必要な場合には、重複してしまうCPUとメモリによって大きなオーバーヘッドが生じてしまうことになります。Indexingと検索を同時に行う必要がある場合は、レプリケーションファクターが大きくなり、大きなボリュームのデータに適用されてしまうため、大変なオペレーションになってしまいます。
Indexing用のCPUとメモリのリソースはIndexingオペレーションと検索クエリを同じマシンで行う場合、エンドユーザーの体験に悪影響を与えてしまう可能性があります。エンドユーザーが行う検索トラフィックがスパイクした場合、Indexingに使われるリソースによって、このトラフィックのスパイクに対してその能力にリミットがかかってしまいます。
Algoliaの最初のアーキテクチャにおいては、この問題に対してIndexingと検索を異なる2つのプロセスに化けることで軽減をしてきました。私たちはLinuxカーネルの機能を使って異なるNICE値を設定することで、検索を処理するプロセスをIndexingするプロセスよりも優先させてきました。この優先順位付けは良い回避策ではあったものの、それでも最適とは言えませんでした。すなわち、より大量の検索クエリをサポートするには、新しいレプリカを作成し、Indexingに使う全てのCPUとメモリを確保する必要があります。
このアプローチのもう1つの大きな欠点としては、auto-scaleの能力が制限されてしまうことです。新しいレプリカを追加するには、既存のマシンからデータを取得してログを再適用する必要がありますが、これには何時間もかかることも多く、既に限界に達してしまっているマシンにさらなる負荷がかかります。シャードを構築するためにリソースを追加すると、マシン間でシャードを移動させる必要がありますが、これにも同様の欠点があると言えます。結果としてアーキテクチャ全体のサイズを大幅に拡大させて、データクエリの増加に備えなければなりません。検索処理と同じマシンでIndexingオペレーションを行うアーキテクチャにはこの問題がついて回ります。
3. スケールのためのもう一つの方法
レプリケーションにはもう1つ別の方法もあります。Indexingオペレーションのログをレプリケーションする代わりに、Indexingタスクが終わった後にディスク上にコミットされたバイナリデータをレプリケーションするというものです。
このアプローチのメインの利点としては、Indexingに使われるCPUとメモリが検索によっても使われることが避けられるということです。一方で、不利な点としては、オプティマイズを行うオペレーションによってデータ構造が書き換えられると、バイナリファイルが大きくなってしまい、遅延が生じてしまうことです。
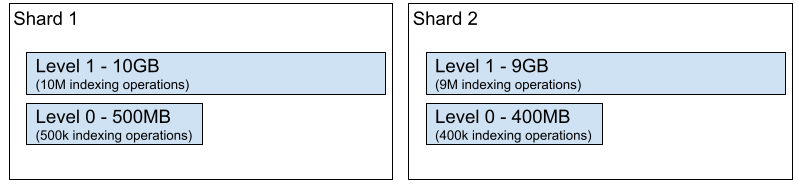
検索エンジンのアーキテクチャにおいては、1分以内を目標とした大量のIndexingオペレーションと、それを行いながら検索をハンドリングするといったことが求められることが多く、これがこのアプローチを採用しなかった理由になります。また、検索エンジンは世代別のデータ構造に依存していて、実際のところは、ディスク上にシャードを表す1つのバイナリファイルがあるわけではなく、ファイルのセットがあるということになります。そして、その実装はシャード全体に適用されるLog Structured Merge Tree(LSM Tree)と同等のものが多いでしょう(転置リスト、オブジェクトストア 等)。シャードが新しいIndexingオペレーションをウケると、ディスク上のより小さなデータ構造に格納されます。図5は、2つのシャードに2つのレベルだけを適用した単純なLSM Treeを表しています。新たなIndexingオペレーションは、シャードが一定のサイズなったらマージされてレベル1になりますが、それまではレベル0で実行されます。
重複する部分を取り除き、検索効率をオプティマイズするにはこういったマージ処理が必要になります(各クエリはそれぞれのレベルで実施され結果をマージする必要があります)。これの欠点はディスク上の全てのファイルが変更されて、各レプリカが全てのシャードデータを含む新しいバージョンを取得する必要があるということです。
図6は、図5のシャード1が毎分1000回更新のオペレーションを受け付けた場合の、レプリカに転送されるデータ量の時間経過を示すものです。毎分1000回のIndexingオペレーションにより、シャード内の既存のレコードが更新されます。更新されたレベル0のファイルは、レベル0とレベル1のマージ(レベル0が1GBになった時)が発生するまで、レプリカに転送されます。このマージは午前8時過ぎに発生し、新しいレベル0のファイル(10GB)がレプリカに転送されます。
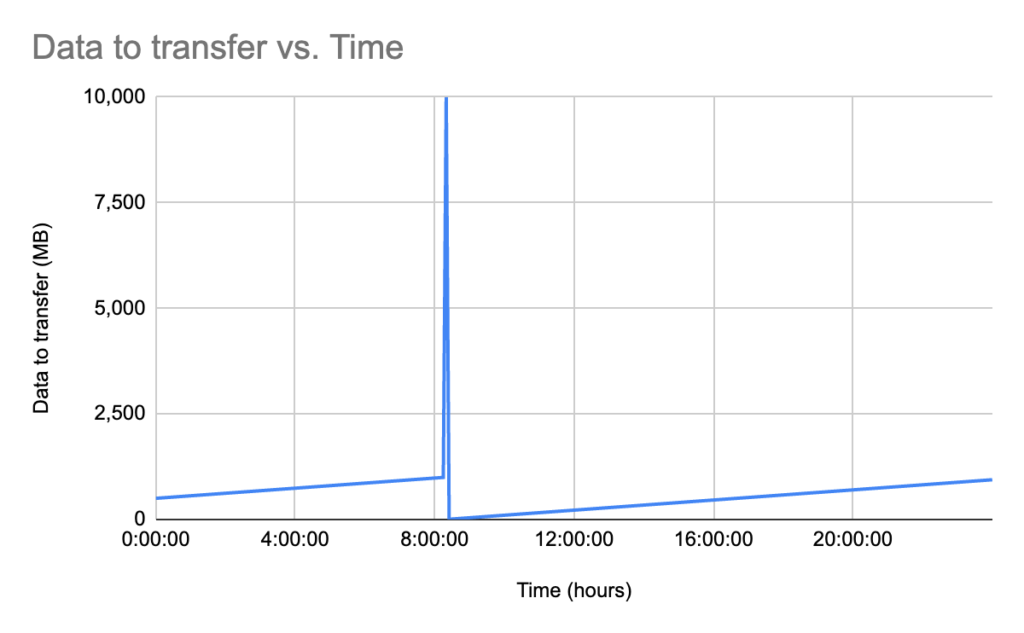
このグラフには様々なファクターが影響を与えています。重要なのは以下2点です。
- シャードのサイズ。このサイズは全てのレベルのマージの後に行われる転送データの最大ボリュームを定義します。
- LSM Treeのレベル数。全てのレベルのマージの頻度(最大データサイズを転送する回数)に直接影響を与えます。
セットアップにベストなシャードのサイズと、ツリーの適切なレベル数があるとすれば、残る問題はネットワークとディスクの問題です。レプリカでのIndexingのレイテンシーを1分未満に抑えるためにはどうすればよいでしょうか?
4. 高速ファイルレプリケーション
Goodニュースとしては、クラウドのインフラがこの10年で劇的に進化しており、膨大な帯域幅(最大で100Gbpsのインターフェース)にアクセスできる新しい世界観をもたらしたことが挙げられます。このような進化によって、Indexingの遅延によるネガティブなインパクトを受けずに、Indexingと検索の分離を力強く推し進められるようになりました。この分離によってより効率的でダイナミックなスケーリングが可能となります。
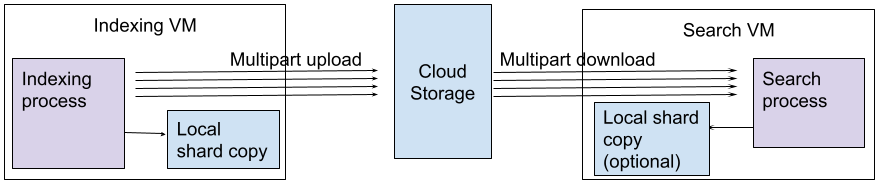
図7は、クラウドのストレージインフラストラクチャを利用して、1つのシャードを構築する方法を示しています。同じロジックでN個のシャードを並行して構築することができます。アーキテクチャは以下のようなコンポーネントで構成されています:
- Indexing VMはローカルのSSDにファイルのコピーを保持しています。もしハードウェアが故障したら、新しいマシンが起動し、クラウドストレージからコピーを取得
- 新しいファイルについてはIndexingプロセスによってメモリ上で処理
- ファイルのアップロードはマルチパートアップロード。全ての巨大ファイルはクラウドストレージにもプッシュ(ファイルをN個の小さなセグメントに分割)
- クラウドストレージのアップロードとともに、ファイルはIndexing VMのローカルにキャッシュとして保存
- クラウドストレージのプッシュがファイナライズされると検索用VMはマルチパートダウンロードで全ファイルをローカルに取得
- 全ファイルがメモリに載ったら、検索処理は新しいバージョンのデータに切り替え
- オプションとして、検索VMがデータサイズよりも小さいメモリしかないような構成になっている場合、コピーされたローカルディスクのデータを使う
このアプローチのメインのアドバンテージ:
- シャードのマルチパートアップロードによりマージのインパクトを1分以内に抑えることが可能に。例えば、シャードサイズを1GBといった小さいものにすることでnear-real-timeなIndexingをターゲットにすることもできる
- 検索オペレーションとIndexingオペレーションはそれぞれ独立してスケール。どちらにも専用の仮想マシンを割り当て
- Indexingのレイテンシはシャードが数GBを越えない限り、1分以内
- 新しい検索用VMの追加/削除は非常に高速(数GBのシャードであれば1分以内)
- 新しいIndexing VMの追加/削除や、より多くのコア数を持つVMに入れ替えを行うのも高速に実施可能。1GBの20個のシャードを構築する1台のVMを10個のシャードで2台のVMに置き換えるのは1分以内に実現可能
このような今までとは異なるアーキテクチャによって、データのリバランスに時間やコストをかけることなく、リソースの追加および削除が可能になります。また、このアーキテクチャでは、非同期処理を用いることにより、Indexingの処理を中断することなく、1つのインデックスのシャード数を変更するなど新しい機能も実現できています。
クラウドストレージは、レプリケーションファクター3で、Indexingの高可用性を実現します。Indexing用のVMが故障すると、別のVMに置き換えられ、クラウドストレージから以前のデータバージョンを取得することができます。検索の高可用性は、異なるアベイラビリティーゾーンに異なる検索VMを配置することで実現されます。クラウドストレージのもう一つの魅力としては、データを複数のリージョンにレプリケートすることができるということです。これによってリージョンをまたいだ展開が容易になります。つまりそれは、異なるリージョンに検索用VMを配置するだけで良いということになります。
最後に
このアーキテクチャでは、ReadとWriteのオペレーションが完全に分離されているため、これらを独立して拡張し、ダイナミックなスケーリングを実現することができます。トラフィックやIndexingの大幅な増加を予測して、セットアップを大幅にオーバープロビジョニングしておく必要はもうありません。このアーキテクチャは、転置リストインデックスだけに限らず、ベクトル検索エンジンやシャード間の独立性が高いアーキテクチャにも有効です。

コメント