
こちらはAlgoliaのSenior Machine Learning EngineerのMarc von Wylが書いた Increase decompounding accuracy by generating a language specific lexicon の翻訳です。
複合語の分割とは、言葉を意味のあるパーツに切り分けていくことです。多くの言語においては、新しい言葉を生成するのに複合語が多用されていることから、これは多言語を扱う検索エンジンにとっては重要なプロセスです。ドイツ語のユーザーがHundehütte(犬小屋)を探している際に、Hütte für meine Hund(私の犬の家)と入力したとしても同じ結果が出てきて欲しいと考えます。ほとんどのeコマースの検索はキーワードベースであり、stop wordsとして für (for) と meine (my) を除いたとして、複合語のHundehütte が Hunde + hütte に分割されれば、Hütte für meine Hundとクエリした場合の結果は同等になるでしょう。
このブログ記事では、複合語を定義し、その分割のコンセプトについてご説明していきます。よくある言葉の分割方法について議論し、Algoliaで行っている方法を紹介していきます。また、分割すべきではないもの(例えばairportをairとportに分割すべきではない)についても触れていきます。
複合語とは何か?
もし、髪の毛を切ったり(haircut)、バイク(motorcycle)を見かけた人は、複合語をよくご存知かと思います。複合語とは、2つ以上の単語(語彙)を組み合わせて新しい単語を作ることです。複合語は通常、名詞、形容詞、そして動詞で構成されています。例えば以下のようなものです:
- soy source のようにオープンなもの
- probability-based や gray-haired のようにハイフンで区切られているもの
- shortcut や whiteboard のようにクローズドなもの
検索という文脈において私たちの関心は最後のクローズドな複合語になります。他の2つは簡単に分割できるので。
全ての言語とは言いませんが、ほとんどの言語が複合語を使って新しい言葉を生み出しています。
- オランダ語: verjaardagskalender (birthday calendar) = verjaardag (birthday) + kalender (calendar)
- フィンランド語: kukkakimppu (flower bouquet) = kukka (flower) + kimppu (bouquet, collection)
- 日本語: お好み焼き (okonomiyaki) = お好み (okonomi, preference) + 焼き (yaki, cooking)
いくつかの言語においては、複合語は非常に長い単語を生み出すことがあります。ドイツ語では、複合語に長さの制限がなく、Donaudampfschiffahrtselektrizitätenhauptbetriebswerkbauunterbeamtengesellschaft (ドナウ汽船電気事業本工場工事部門下級官吏組合) は、1996年にギネスブックに最も長い単語として認定されました。
ゲルマン語では、複合語は通常、headと1つもしくは複数の修飾語で構成されます。headは右(単語の終端)にあって、修飾語は左にあります。これらはlinking(連結)形態素を使って接続されます。言語学において形態素とは意味としての最小単位であり(例えば dogs = dog + s、uncomfortable = un + comfort + able)、連結形態素は言葉をつなぐために使われます。また、genitive(所有格)や複数形を使う場合など、抑揚の度合いを表すのにも使われます。
- Hundehütte
- Voorlichtingssysteem (オランダ語: 防止システム)
- Eftermiddagskaffe (デンマーク語: 午後のコーヒー)
連結形態素は言語によって異なります。ここではいくつかの言語の例をご紹介します。
- スウェーデン語: o, u, e, s
- オランダ語: s, e, en
- ドイツ語: s, e, en, n, nen, ens, ns
Fahrschle(自動車教習所)のように接続の際に部分的にカットされる言葉もありますが、Fahren(運転する)という動詞においてはその語幹の部分までカットされます。
複合語の分割とは何か?
複合語の分割とは、複合語を意味のある語句に分割して、それぞれ意味のあるユニットを抽出することです。
避けなければならいことと言えば、言葉を分割し過ぎてしまうことです。例えば、オランダ語のVoorlichtingssysteem(予防システム)は、Voorlichting(予防) + s(複数形) + Systeem(システム) と分割することができます。ここに留まることに意味があります。VoorlichtingをVoor(〜の前) + lichting(バッチ)と分割してもいいのですが、そうすると、その時点で複合語の本当の意味を失ってしまいます。
一般的な複合語の分割の方法
ほとんどの分割法は、これ以上分割すべきではないという単語の辞書の定義にもとづいています。こういった単語をatomと呼びます。例えば、ドイツ語のWissenschaftskolleg(科学大学)の場合、atomはWissenschaft (科学) と Kolleg (大学)になります。WissenschaftはWissen (知識) と Schaft (シャフト)に分割することもできますが、それを行ってしまうとオリジナルな意味を失ってしまいます。辞書を使って複合語の中にぴったりと収まる最長のatomをみつけることで複合語を簡単に分割することができるようになります。
これにはいくつかの方法があります。
- JWord Splitter は左から右に再帰的に分割
- Banana Splitter は右から左へ長いatomに合わせて貪欲にマッチさせる
- ASV Toolbox はPatricia treeを使う
より高度な方法としては、単語の統計的なプロパティを利用するものがあります。大量のデータの中でatomが出現する頻度を抽出し、単語全体が意味を持つ確率が部分の確率よりも低い場合だけ、単語を分割するというもの。機械学習は、また単語の分割に関しても活用されています。最も引用されているクエリワードの分割(※1)に関するリソースの1つにおいて、その著者は、大規模なコーパスでの出現頻度やクエリの中でco-occurrences(同時使用)といった言葉の統計的なプロパティをsupport-vector machine(SVM)を用いて組み合わせています。
最近では、研究者のMartin RiedlとChris Biemannが、単語の統計的な特性と分布シソーラス上の距離を利用し、複合語をlikely(可能性の高い)とrelated(関連する)な単語に分割するSECOSという手法を提案しています。
Algoliaのアプローチ: 複合語の分割用の辞書の構築
Algoliaではスピードがクリティカルです。検索エンジンの速度を著しく低下させ、search-as-you-typeのような機能を壊してしまうようなアプローチは採用できません。そのため、クエリ実行時に複雑で重い機械学習ベースのアプローチを使うことはできません。
この点において、効率的な複合語の分割システムには、優れた辞書が最も重要であると、私たちは結論を出しました。以下は、ドイツ語のテストセットの例で、テストセットに素材するatomのみで構成された辞書と使って以下の指標を計算しました。マッチングにはシンプルで貪欲なlongest matchアルゴリズムを採用しました。テストセットの半分は、分割すべきではない単語で構成されています。例えば、Handschuh(手袋)はHand + schuh(手と靴)に分割してはいけません。そして残りの半分は分割をするべき複合語を含んでいます。
| Compound | Translation | Split |
| Wissenschaftskolleg | Science college | Wissenschaft + Kolleg |
| Hundehütte | Dog house | Hund + Hütte |
| Handschuh | Glove | Handschuh |
| Hinterziehung | Evasion | Hinterziehung |
テストセットの全てのatomを私たちの辞書に登録したところ(例: Wissenschaft, Kolleg, Hunde)、私たちは以下のような結果を得ました。
| Method | Vocabulary | F1-score | Precision | Recall | Accuracy |
| Greedy longest | 3,702 words | 0.998 | 0.998 | 0.998 | 0.999 |
これは素晴らしい結果ですが、チート(ズルをする)です。現実の世界では完璧なatomのセットはありえません。例えば、HundとHütteだけで構成された辞書は、テストセットがHundehütteだけで構成されていればパーフェクトなスコアになりますが、実際のデータではそううまくはいきません。
私たちは、より信頼性の高い、網羅的な辞書を構築する必要がありました。私たちのアプローチとしては次のようなステップになります。
- 該当言語の大量のテキストを探す
- 頻繁に使われる名詞、形容詞、動詞を抽出し辞書を構築する
- 特定のスコア(詳細は以下に記載)で分割できなかった単語のみを残すことで辞書をトリミング
- ポテンシャルのある語彙で辞書を強化していく
該当言語の大量のテキストを探す
無料で使うことができる教師なしテキストデータはいくつかのソースからオンラインで入手することができます。私たちはWikimediaのデータ、特に、WikipediaとWikinewsのデータが好みです(Wikipediaが十分なデータ量を提供していない言語についてはOSCARという選択肢もありますが、私たちは使ったことがありません)。当然このデータは、スタンダードなテキストプロセッシングを行って記事から抽出したデータを適切にクリーニングする必要があり、そして、言語分類器(language classifier)を使って、抽出した文章のほとんどが望ましい言語であることを確認することも必要でした(オンラインのオプションとしてはfastText, langdetect, そしてCLD3というサービスもあります)。
名詞、形容詞、動詞の抽出
ターゲット言語の大量のテキストが手に入ったということで、その中からポテンシャルなatomを抽出したいと思います。複合語は、名詞、形容詞、そして動詞で構成されるということが分かっていたので、データの中からよく使われているそれらを見出すことができれば、ポテンシャルなatomを見つけることができます。
atomを抽出する上で、私たちはpart-of-speech(品詞。名詞、代名詞、形容詞、副詞など)をマッチさせる分類タスクであるpart-of-speech taggingを用いました。幸いなことに、いくつかの言語で品詞のタグ付のためにDeep Learningで学習されたライブラリが存在していました。それらはよく知られている spaCy, Stanza, flair, そしてtrankitといったものです。私たちはまた、こういったポテンシャルなatomの出現数をカウントして、次のステップに役立てることにしました。
Lemmatization(レンマ化、見出し語化)とは、活用された単語の基本形もしくは辞書形(そのレンマ)を見出すことです。例えば、dogsの基本形はdog、wasの基本形はbe、walkingの基本形はwalkです。単語は形態が変化するものなので、余すことのない量を得るためにレンマ化をしました。そして、中にはノイズやタイプミスの可能性もあるので、出現頻度が低い単語やatomではなさそうな非常に長い単語などをフィルタリングしました。
辞書のトリミング
このステージでは、比較的頻繁に使われている名詞、形容詞、そして動詞が私たちの辞書に含まれており、これらがポテンシャルなatomであるとみなします。しかしながら、これあらのポテンシャルなatomの多くは複合語である可能性が高いです。ここから不要な複合語を取り除くために、ポテンシャルなatomの統計的なプロパティを使いました。ある単語が他の単語の組み合わせによって分割されて、それらの他の単語の確率の幾何平均(geometric mean。以下を参照)が単語全体の確率よりも高いような場合は、その単語を辞書から取り除くことにしました。
私たちはポテンシャルなatomを以下のように計算しました。
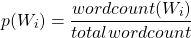
ここでのtotalwordcountは、コーパスの中に含まれている単語の総数、wordcount(Wi)は、単語Wiがコーパスの中に出現する回数です。
私たちはポテンシャルな複合語の分割の幾何平均の確率Wdを以下のように計算しました。
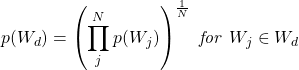
Nは分割されたatomの個数です。
与えられた単語Wnについて、幾何平均の確率であるp(Wd)がそのままの言葉の確率であるp(Wn)よりも高ければ、Wdを分割して辞書からWnを削除します。また、分割する候補においては、言語固有の連結形態素も考慮に入れます。
例えば、私たちのコーパスの中にAkustikgitarreが50回、Akustikが75回、Gitarreが150回あったとして、全部のワードカウントが50,000だったとすると:
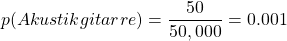
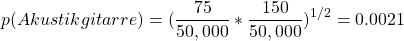
となり、AkustikgitarreはAkustikとGitarreを合わせたものよりも確率が低くなるので、辞書からは取り除かれます。
辞書を強化する
最後のステップとして、レンマ化で行ったものを元の状態に戻しました。私たちは、いくつかの言語におけるポテンシャルなバリエーションをリスト化した内部的な語形変化辞書を保持しており、これを使うことでatomの全てのバリエーションをatom辞書に追加しました。
分割アルゴリズム
辞書ができたので、インデックスの作成時やクエリの際に、ポテンシャルな複合語に対して分割アルゴリズムを適用することができるようになりました。残念ながら、上記の確率の幾何平均を用いた分割を行おうとした場合、計算コストがかかってしまいます(指数関数的な数の分割がおこなわれます)。例えば、Donaudampfschiffahrtselektrizitätenhauptbetriebswerkbauunterbeamtengesellschaft のような単語で20個の分割候補が考えられる場合は、100万回の可能性テストをしなければなりません。ということで、単純に右から左(今回の対象言語は全て左に展開するためright to left)に最長一致するアルゴリズムを採用しました。この強欲なアルゴリズムは単純に単語の最後からはじめて、右から左に向かって、その単語の中で可能な限り長い単語とのマッチングを試みます。その後、単語の残りの部分を、その単語に含まれる全てのatomにマッチするまで続けていきます。また、atomの間に存在する言語固有の連結形態素は許可します。
分割の評価
私たちは自分たちの結果をSECOS(※2)の結果と比較しました。私たちのメトリクス評価の詳細はappendixに記載しました。
テストセットとして、SECOSのGitHubページに公開されているドイツ語のテストデータセットを用いました。このベースデータセットは、複合語のみが提供されていて、分割すべきではない複合語は提供されていません(例えばHandschuh)。
分割してはならない単語があるということは、今回のやり方の精度を評価する上でとても重要です。ということで、テストセットに含まれている他のatomによって分割されない7文字以上のatomを”分割すべきでない”セットとして活用しました。最終的なテストセットは1851語の複合語と1851語の分割すべきでない単語を含む3702語で構成されています。若干ノイズが目立つものの手法の比較には十分であると思います。
以下のプロットは生成された辞書のサイズを変更して作成されたものです(フィルタリング基準として単語の頻度を使用しました)。辞書のサイズが大きくなるとリコール(再現率)が増加し(より多くの複合語を分割することができるようになりました)、その代わりプレシジョン(適合率)は減少する(分割すべきではない単語を分割しはじめる)ことに注意が必要です。
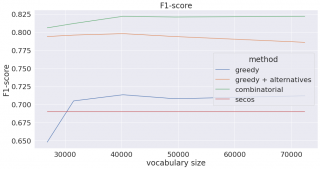
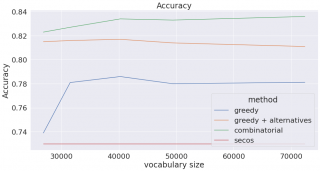
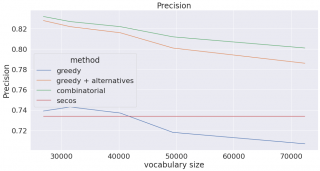
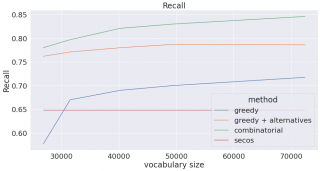
Combinationalは、3つ目の点までの私たちの方法で構築された辞書(つまり私たちの変化形辞書で補強をする前のもの)に、上記の幾何平均を用いたコンビネーショナルな方法を使っています。Greedyは、同じ辞書を用いた強欲な手法をあらわしています。Greedy+alternativeは私たちの語形変化辞書によって強化された(上記4つ目の点まで)辞書です。Greedy+alternativeの語彙の数は、追加の語形変化をカウントしていないので正確ではないことにご注意ください。私たちはSECOSのボキャブラリーは変形せず、GitHubページで公開されている学習済みのモデルを使いました。
繰り返しになってしまいますが、組み合わせの方法は計算コストが掛かってしまうため実際には使用することができませんが、私たちの方法(greedy+alternatives)は、より高速な計算時間でF1-scoreに近づきます。
SECOSの結果が、研究者による論文の記事として報告されたものと近くないことに気づいた方もいらっしゃるかもしれませんが、これは、私たちの評価が研究者のものよりも厳しかったからと言えます。私たちは、複合語の分割方法(※3)について論文で定義されている評価に従って、部分的に正しい分割であったとしても、間違っているものと判断しました。例えば、Wissenschaftskolleg -> Wissen + Schaft + Kollegは、完全に間違っていますが、SECOSの評価では部分的に正しいことになります。それにもかかわらず、ドイツ語のテストセットで彼らの評価スクリプトを使用したところ、彼らの手法のF1スコアは0.87であり、私たちの手法(greedy + alternatives)は0.92でした。
分割機能 in action
Algoliaは6つの言語の複合語分割をサポートしています: オランダ語(nl)、ドイツ語(de)、フィンランド語(fi)、デンマーク語(da)、スウェーデン語(sv)、ノルウェー語のBokmål(no)です。複合語の分割について詳しくは、ドキュメントをご参照ください。
生成された辞書は一般的なデータには適していますが、多くのお客様は非常に特殊な語彙を持つニッチな分野を生業とされています。私たちのcustomer dictionariesを使えば、任意の方法で指定された単語の分割をお客様のご要望に応じて行うことができます。
まとめ
私たちは、適切な辞書が優れた複合語の分割アルゴリズムにおける最も重要な部分であるということを示しました。そして、私たちはより良い辞書を計算する方法を実装しました。この方法では以下のみが必要です:
- 対象言語の大量のテキストデータ
- 対象言語の品詞分類器
- 言語特有の連結形態素
この辞書は、強欲な最長マッチ分割アルゴリズムを組み合わせることで、より複雑な実装に勝り、クエリなインデクシングのスピードを犠牲にすることはありません。
※1 Decompounding query keywords from compounding languages. E. Alfonseca et al., Proceedings of ACL-08: HLT, Short Papers, 2008.
※2 Unsupervised Compound Splitting With Distributional Semantics Rivals Supervised Methods. M. Riedl, C. Biemann, HLT-NAACL, 2016.
※3 Empirical Methods for Compound Splitting. P. Koehn, K. Knight, 10th Conference of the European Chapter of the Association for Computational Linguistics, 2003.
Appendix
A.1 Measures
複合語の分割の品質を評価するために、通常のテストであるprecision, recall, F1-score, accuracyを使いました。precision, recall, そして, F1-scoreに関しては、KoehnとKnightが複合語の分割に関する論文で使用した定義に従いました。
- Correct split = #words which should be split and were split correctly
- Correct non = #words which should not be split and were not
- Wrong not = #words which should be split but were not
- Wrong split = #words which shouldn’t have been split but were
- Wrong faulty = #word which should have been split, were split, but wrongly
- Correct = correct spilt + correct non
- Wrong = wrong not + wrong split + wrong faulty
以下をもたらします
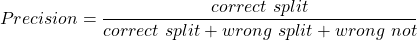
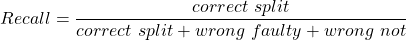
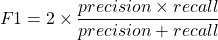
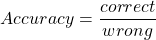
また、望んでいた分割と一致して、且つ、連結形態素の場合、その分割は正しいと考えます。例えば、AdressenListeを分割したときにAdresse + Listeではなく、Adressen + Listeだったとしても正しい分割とみなします。ここでは厳密な評価をしているので、部分的に正しい分割であっても、間違っていると判断していることに注意してください。


コメント