こちらはAlgolia Blogの Facets and faceted search, every JSON attribute counts の翻訳記事です。
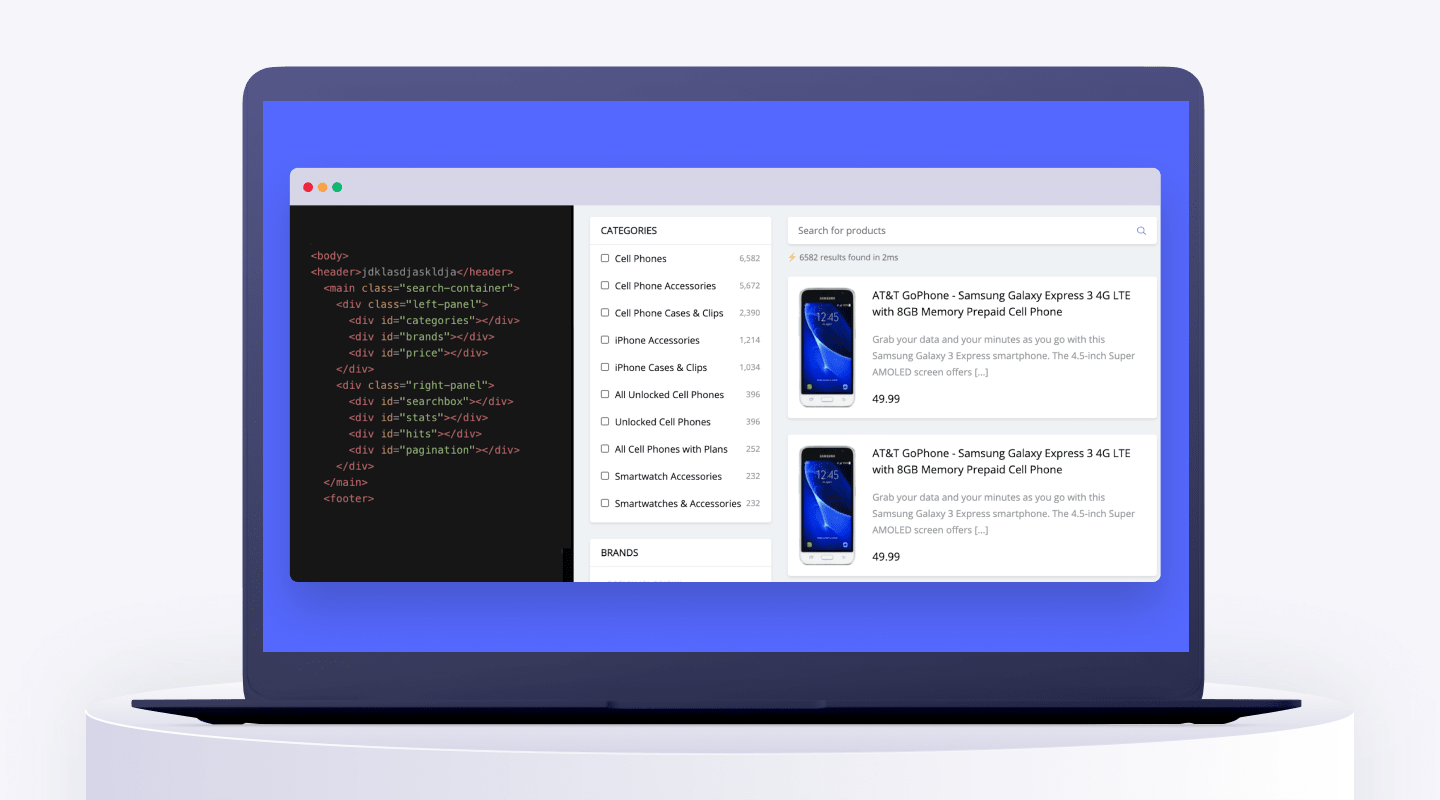
Facetとは? Faceted Searchとは? そしてどのようなデータがファセットを最もよく表している?
簡単な定義: Facet とは、エンドユーザーが検索結果を絞り込むためのスクリーン上のフィルターのことであり、検索結果の適合度をよりコントールさせます。eコマースにおけるよくあるファセットの例としては、”ブランド”や”値段”が挙げられ、ファセットの値はそれぞれのブランド名や価格になります。ユーザーはファセットの値をクリックすることで、商品のカテゴリー全体を含めたり除外したりすることができます。例えば、”Brand”のカテゴリーで”Apple”を選択すると、Apple製品以外の全てを除外することが可能になります。
私たちはこれを Faceted Search体験と呼んでいて、検索バーにおけるテキストと同様に、カテゴリーや共通の言葉が検索をドライブします。優れたオンライン検索環境では、Facet化された検索が提供されています。
Faceted Searchの裏にあるデータ
この記事では、データからUIに至るまで、Facetを一番はじめから見ていきます。具体的には、JSONを用いて優れたFaceted検索体験を実現する方法を書いていきます。ファセットのために考え抜かれたデータ戦略は、効果定期なフィルタリングとハイスピードのパフォーマンスを可能にします。また、それはフロントエンド開発者がコードを書くことを容易にし、速いペースのコーディング環境における大変重要なものとなります。
ファセットはデータをキレイにする
良い検索は、いつもCleanなデータからはじまります。最高の検索インデックスとは、well-structuredで、well-writtenで、そして、誤解を招いたり無駄と思われるようなものが含まれていないものを示します。インデックスとは、検索可能なデータセットのことで、インデクシングとはインデックスを作成するプロセスのことです。これらは、検索エンジンがどのようにデータを構成しているかを表現するための、検索技術における標準的な言い回しになります。検索エンジンによってデータの構造は異なるものの、最終的にはインデックスがいつもインデックスがあります。私たちはデータセットやデータベースといった用語は使わずインデックスという単語を使います。
全ての検索インデックスにはファセットが含まれます。なぜならファセットはデータをオーガナイズして、シンプルさと完全性を保証するからです。次のような例を考えてみましょう: 最初の例にはファセットはありませんが、次の例には含まれています。
Facet無し
- Title: Star Wars: Episode V – The Empire Strikes Back
- Description: Popular science fiction movie from the 70s, an American space opera, where Luke Skywalker, along with Han Solo, Princess Leia, and Chewbacca, fight Darth Vader and the Rebel Alliance to save the Galactic Empire. Created by George Lucas, the movie was produced by Lucasfilm and is now owned and distributed by Walt Disney Studios films. The ensemble cast includes Mark Hamill, Harrison Ford, Carrie Fisher, Billy Dee Williams, Anthony Daniels, David Prowse, Kenny Baker, Peter Mayhew, and Frank Oz. The film became the highest-grossing film of 1980 with $440 million.
Facet有り
- Title: Star Wars: Episode V – The Empire Strikes Back
- Description: An American space opera. Luke Skywalker, along with Han Solo, Princess Leia, and Chewbacca, fight Darth Vader and the Rebel Alliance to save the Galactic Empire.
- Genre: science fiction, space opera
- Era: 70s, 80s
- Story: George Lucas
- Saga: Star Wars
- Studio: Lucasfilm, Walt Disney Studios
- Production facts: The film is produced by Lucasfilm, now owned by Walt Disney Studios films.
- Actors: Mark Hamill, Harrison Ford, Carrie Fisher, Billy Dee Williams, Anthony Daniels, David Prowse, Kenny Baker, Peter Mayhew, Frank Oz.
- Characters: Luke Skywalker, Han Solo, Princess Leia, Chewbacca, Darth Vader, Yodi, C-3PO, R2-D2
ご覧いただいております通り、”description”は大幅に短くなり、要点が簡潔にまとめられています。また、その内容を”production facts”、”genre”、”actors”、そして”saga”といった属性に移動させました。これらの属性の一部は検索結果に表示されますが、”description”のほとんどの部分は、検索やファセットの処理に役立つ情報のチャンクにブレイクダウンされます。このアナリティカルなプロセスは、ユーザーに優れた検索可能インデックスとFaceted検索体験を提供するための重要なステップです。
このようにデータを詳細に落とし込むことで、それぞれの属性に価値が生まれます。これがファセットの1つの利点です。
基本的な原則としては: 1つの属性に含まれる大量のテキストは、複数の属性に含まれる小さなテキストのチャンクほど検索に適しているとは言えません。これらのfacet-chunkを使って、ユーザーは検索結果をフィルタリングすることが可能になります。
例:
- George Lucasによってプロデュースされた全ての作品
- Science Fiction映画を除いた全てのサブジャンルがSpace Operaの作品
- “Saga”ファセットによる全てのStar Wars映画の絞り込み
ほとんどの企業は既に構造化されたデータを保持しており、検索可能なインデックスを構築するには、その構造化データをトランスファーするだけですが、一方で、複数のデータソースを扱っているような企業もあり、それらのデータソースをマージしながら新しい構造を設計する必要があります。
Faceted検索 – ファセットはフィルタリングためだけではない
bite-size(一口サイズ)の情報をデータにセットアップすることでの利点は、検索エンジンがレコードをフィルタリングできるようになるだけではありません。また、情報に注目することで、フィルタリングされていないような検索をより正確に行うことができるようになります 。これはFacet属性をSearchableなものとして定義した場合にのみ可能となります — つまり、検索エンジンに、”title”や”description”を探す前に、”year”と”type”の属性を探すように指示をする、ということです。そうすることで”70s sci-fi movies”とタイプをすると、フィルターを使わなくてもStar Warsを引き当てることができます。
技術的なこと – エンジンレベルでのFacetingとJSON
インデックスにファセットを組み込むには、技術的なことを考慮に入れる必要があります。
- インデックスへのインプットとしてのFacet
- 検索リクエストのインプットとしてのFacet
- 検索リクエストのレスポンスとして受け取るFacet
- AND, OR, NOTを組み合わせたFacet
- エンジンがFacetを扱う方法
こちらの記事では、facet filteringとfaceted searchにおける基礎的な部分の – データを分解してファセットとする方法 – だけを取り扱います。その他の点に関しても触れはしますが、今後の記事でより詳細をご紹介いたします。
検索インデックスにFacetを定義する
Facetのベストなデータフォーマット:
- アプリケーションやビジネスのニーズに応じた、完全にカスタマイズ可能なファセットのセット
- 理解しやすいデータ構造
- インデックス内のレコードが柔軟に異なる属性の集合を持つことが可能
- 複数のファセットバリューや階層型カテゴリーを可能にするスケーラブルな構造
一言でいえば JSON
JSON vs リレーショナル・データベース
非常に簡単にその歴史を述べます: リレーショナル・データベースは外部キーやアトミックデータなど、それまでのデータテクノロジーを発展される形で標準化を行いました。リレーショナル・データベースでは、データベース内の全てのアイテムを明確に定義された小さな関連テーブルに分散させることで、データを正規化することを可能にしました。これによって、信頼性が高く、理解が容易で一貫した構造を持つ均質性が生まれました。しかし、この均質性は、異なるデータのニーズを持つすべてのアプリケーションの要求を満たすものではありませんでした。そのために、構造の異なるような複数のデータベースを作成して、時にはそれぞれ同様の情報を保持するといった解決策がとられてきました – そのため、メンテナンスが困難となり、余剰のリソースが必要となってしまうソリューションと言えるでしょう。
Entity-Attribute-Value (EAV) モデルは、リレーショナルモデルにフレキシビリティを与えるもの: 同じデータベースの中でもそれぞれのアイテムは異なる定義をすることができる、といった heterogeneity(不均一性)を追求しており、1つのデータベースに多種多様な情報を効率的に格納することができ、すべてのアイテムがKey/Valueと呼ばれる独自の完全な説明タグを保持します。EAVでは、複数のスキーマを使うことで、データの重複を避けるという原則を維持して、多くのバイイ、固有の値を1つのテーブルにローカライズします。
JSONはEAVの原則をカプセル化しつつも、EAVのリレーショナルなルーツからも離れています。特に、テーブルと行のスキーマを廃止することで、データの繰り返しを避けるという原則を緩和しています。JSONは情報を何度も繰り返します。制約はありません。すべてのレコードはvacuumの中にあり、独自の属性のセットを含んでいます。また、エンティティが従わなければならないような事前に定義されたスキーマもありません。そこにあるのはJSONオブジェクト(もしくはレコード)と、keyとvalueだけです。
JSONはなぜSearchableなインデックスを構築することと相性が良いのか?
検索エンジンは他のレコードとのリレーションによらず、インデックス内のすべてのレコードをアトミックに扱う必要があります。また、リレーショナル・データベースのようにデータをノーマライズするのではなく、逆にデータを非正規化する必要があります。
さらに、レコードに何が含まれているかは事前にわからず、コマーシャルプロダクト、映画、もしくは、プロフェッショナル・サービスのようなものなど、どのようなデータがインデックスに取り込まれても検索エンジンはクエリにマッチするレコードをすべて返す必要がある。ほとんどの検索エンジンはセマンティクスには依存せずにテキストマッチングに依存しています。それの意味するところとしては、検索エンジンはアイテムの属性に含まれるコンテンツと検索バーに入力されたテキストをマッチングさせるだけで良いということになります。フルにマッチをしても部分的にマッチをしても良いということです。JSONはその可読性(readability)から、データをそのテキストコンテンツにのみフォーカスさせます。
JSON の key/values は easy-to-read で easy-to-search
[
{
"objectID": 42,
"title": "Star Wars: Episode V - The Empire Strikes Back",
"type": “movie”,
"genre": ["science fiction", "space opera"],
"series": "star wars"
},
{
"objectID": 43,
"title": "LEGO: Star Wars Yoda",
"type": “toy”,
"brand": “Lego”,
"series": "star wars"
}
]ここにどのような情報があるかは一目瞭然でしょう。2つのレコードがあり、1つは映画で1つはおもちゃです。映画には”genre”があり、おもちゃには”brand”があり、それぞれ異なる属性を持っています。しかし、どちらにも”series”が存在し、どちらも”star wars”に関するものなのでオプショナルに2つのレコードをリンクさせることができます。
検索エンジンの中には、JSON形式をそのまま検索のベースとして使い、変換を必要としないものもありますが、ほとんどの検索エンジンではこのデータをプロプライエタリなインデックスのフォーマットに変換をします。どちらの場合でも同じプロセスで: 全てのレコードとキーをループ走査し、値(value)を保存(もしくは検索)します。ベストなアルゴリズムではキーと値以外は何も要求されないものの、ほとんどのエンジンではミニマムな属性の要求があります。例えば”Object ID”は、すべてのレコードに対する一位の識別子となり、インデクシングにおいてレコードを探して更新したりする際に使われます。しかし、誤解をしないでください。”objectID”はリレーショナル・データベースのprimary keyとは異なります。検索においてはprimary/foreignキーが使われることはほとんどありません。興味深いことに、検索においてキーの代わりにファセットを使ってレコードをリンクします。先ほどの例ではおもちゃと映画が”series”というファセットでリンクでされていることが分かります。
REST APIとJSONの生成および可視化の相性の良さ
JSONと同様に、REST APIはかつてのSOAP APIに代替するものを提供することでその標準を簡素化しました。これには、より少ない規約でより多くの柔軟性を持たせるという似たような理由があります: SOAPは厳格な仕様とルールを持ったプロトコルに基づいていますが、REST APIはそれを排除します。REST APIはエンドポイントを提供し、CSV, XML, JSONといった様々なデータ形式を受け入れます。フォーマット化されたデータを何で送信するかといったコミュニケーションは、エンドポイントとREST APIのディベロッパーに任されています。ベストなAPIは多くの特定のデータを必要としません。自分の任務を遂行するのに必要な情報にのみフォーカスしていると言えます。
例えば、こちらは検索の例です:
curl -X POST \
-H "API-Key: 123” \
-H "Application-Id: app_movies” \
--data-binary '{ "params": "query=star wars” }' \
"https://some-movie-api.com/indexes/movies/query"“data-binary”フィールドに全てのメッセージが含まれていて、こちらのパラメーターが検索に使われます。この場合は単純に”star wars”で検索をしているだけです。
Curl から API Client へ
以下はAPIクライアントを使って “app-movies” というインデックスにレコードを作成している例になります。優れた検索エンジンはCurlの面倒なシンタックスを様々なプログラミング言語のAPIでラップします。JavaScriptのAPIクライアントを使うと以下のようになります。
index.search(“star wars”);
index.save('{
"ojectID": 42, "title":"Start Wars: Episode V - The Empire Strikes Back","Description":"An American space opera, Luke Skywalker, along with Han Solo, Princess Leia, and Chewbacca, fight Darth Vader and the Rebel Alliance to save the Galactic Empire.","Genre": ["science fiction, space opera"],"Era": ["70s, 80s"]","story":"George Lucas","Saga: Star Wars","Studio":["Lucasfilm, Walt Disney Studios"],"Production facts":"The film is produced by Lucasfilm, now owned by Walt Disney Studios films.","Actors":["Mark Hamill, Harrison Ford, Carrie Fisher, Billy Dee Williams, Anthony Daniels, David Prowse, Kenny Baker, Peter Mayhew, Frank Oz"],"Characters":["Luke Skywalker, Han Solo, Princess Leia, Chewbacca, Darth Vader, Yodi, C-3PO, R2-D2]"
}' );Curl、JavaScriptのどちらのフォーマットの場合でも “Star Wars: Episode V – The Empire Strikes Back” を簡単にカプセル化することができることがお分かりいただけたと思います。そして、それを人間 – そしてマシン – が読むことができるフォーマットで送ることができるということです。
まとめとFacet化された検索の詳細について
大切なことは、Facetはオプションではないということです。ファセットは検索体験のあらゆる側面で役割を果たします。機能としては、ファセットはデータの検索、レコードのフィルタリング、そして、検索結果の順位付けに用いられます。技術的には、データの品質と正確性を確保し、検索体験の向上に役立ちます。
もう1つ重要なことと言えば、インデックス内のファセットをどのように構成するかによって、その機能的な有効性が決まるということが挙げられます。今日において検索は、あらゆるオンラインビジネスの目まぐるしい変化に対応できる柔軟性が必要とされています。常に変化をし続ける多種多様なユーザーの好みやニーズを管理するための多様性も必要です。JSONはこのような柔軟性と多様性を可能にすると言えるでしょう。開発者は様々なファセットやフィルタリングを最良の方法で表現するために、JSONフォーマットのようなスキーマレスのデータ構造を必要としています。例えばネストされた属性などが挙げられますが、そちらはこの FacetとFacet化された検索 シリーズのパート2でご紹介したいと思います。

コメント