
こちらの記事は Algolia の Co-founder & CTO の Julien Lemoine が書いた The past, present, and future of semantic search の翻訳です。
検索技術によるソリューションをデザインするテクノロジストたちは、セマンティック検索についてよく耳にするようになったと思います。しかし、そのセマンティック検索とは何なのでしょうか?そして、最先端(state-of-the-art)のセマンティック検索とはどのようなものなのでしょうか?
セマンティック検索は一つの技術から成り立っているわけではありません。それは “AI” のように機械学習に関連するほぼ全てのものを意味することができるマーケティング用語であるのかもしれません。1999年、ティム・バーナーズ=リーは、セマンティックWebのアイデアを最初に提唱した一人です。それ以来、”セマンティック検索”という言葉は、クエリプロセッシングに使われるさまざまな技術を指すようになりました。
こちらの記事では、セマンティック検索について説明をしながらクエリプロセッシングを深めていくための主なテクノロジーをご紹介していきます。こういった技術はどこからきて、どのように動作し、どこに向かっているのか見ていきましょう。
Spoiler alert(ネタバレ注意): もし、あなたがeコマースサイトや企業内のイントラネットのサイトに検索機能を構築しようとするのであれば、トラディショナルなキーワード検索とセマンティック検索を組み合わせることで、より完全性および適合性の高い検索結果を得ることが可能となります。
Query Understanding(クエリ理解)の歴史を簡単に振り返る
キーワード検索 と 統計的ランキング: 1970年代にはじまる
キーワード検索は古くからある技術で、書籍の巻末にある索引と同じような仕組みです。キーワード検索のエンジンは、全ての文書に含まれる全ての単語のインデックスを作成し、シンプルなマッチングアルゴリズムに基づいて結果を返します。
検索の適合性と検索結果の順位付けを向上させていくために、検索エンジンはTF-IDFやBM25といった単語の統計的な情報を活用するようになりました。その統計的な検索では、あるドキュメントの中の言葉が頻繁に現れることがない(IDF)ことと、単語がどれだけ頻繁に現れるか(TF)を元に重要度を決定します。例えば、”the” “and” “or” などは至るところにたくさん現れますが、”toothbrush(歯ブラシ)”や”water(水)”はそんなに頻繁に現れるわけではない、つまり一般的ではないとした場合に、単語がどれだけ頻繁に現れるかは、そのドキュメントがどれだけ重要あるいは適合しているかということを示すためのプロキシとして活用することができるということです。
単語の出現頻度ベースの統計的な方法は非常に初歩的なものであり、それは完全一致に依存するものでした。LuceneのAPI を使ってして構築されたキーワード検索アルゴリズムは、今日においても様々なアプリケーションでこの統計式に依存していて、非常にシンプルで素早く実装することができます。しかし、その精度を向上させるためには、同義語ライブラリの作成、ルールの追加、メタデータやキーワードの追加、もしくは、他の種類のワークアラウンドが必要になります。
NLPのはじまり: 1980年代初頭
統計的な手法を用いたランキングは有用ではありますが、それだけでは十分であるとは言えません。例えば、単数形と複数形、動詞の活用形(現在形, 過去形, 現在分詞形 等)や日本語によくある膠着(agglutinative)や複合語などがそれにあたります。
こういった複雑な言語の課題を解決するために自然言語処理(NLP)の技術が開発されるようになりました。そこには、以下のような処理があります。
- ステミング: ステミングは接頭辞(prefix)や接尾辞(suffix)を削除して、単語の基本形にすることです。これによってリソースのユーセージを削減してコンピューティングのキャパシティを向上させることができます。例えば、”changes” や “changing” は基本形の “change” に変換されます。
- レンマ化: レンマ化はステミングと同様に単語を基本形(ルート)にするものです。こちらは単語ごとのコンテキストや形態素をベースにしたものとなります。例えば “changed” は “change” に変換され、”is” は “be” に変換されます。ステミングもレンマ化も単語をオリジナルなフォーマットにすることに使われるので、ほとんどのプロジェクトではどちらか一方が使われているかと思います。
- セグメンテーション: 英語や多くのラテン語がベースとなった言語においては、スペースは単語を区切るデリミタとなりますが、言語によって単語のパーツの組み合わせや区切り方は異なるので、そのコンセプトには限界があります。例えば、英語の複合名詞の多くは可変長な表記となります (ice box = ice-box = icebox)。しかし、このスペースは全ての文章にあるわけではなく、無い場合は単語の分割は困難になります。シンプルな単語分割が行われない言語としては、単語ではなくセンテンスで区切られる中国語や日本語、単語ではなくフレーズやセンテンスで区切られるタイ語やラオス語、単語ではなく音節で区切るベトナム語などがあります。
- 品詞のタグ付け: 品詞のタグ付けは、単語のリストを名詞、動詞、形容詞などに分類することで、クエリをより正確に処理していく方法です。センテンスの中の単語の関係をみて文章の意味をより明確に識別することで精度を向上させます。

- エンティティ抽出: エンティティ抽出は特に音声検索において重要視されているNLP技術の一つです。その名が示すように、エンティティ抽出とは、クエリの様々な要素(人、場所、日付、頻度、数量 等)を識別することで、マシンがその情報を”理解”するのを助けるというやり方です。エンティティ抽出は単純なキーワード検索の限界を克服する上で非常に優れたソリューションではありますが、以下に紹介するオントロジーやナレッジグラフと同様に機能するところが特定のドメインやクエリに限られます。
オントロジーとナレッジグラフ: 2005年に開始
セマンティックなクエリ理解のために開発されていたもう一つの方法は、オントロジーとナレッジグラフの活用でした。ナレッジグラフは、概念, オブジェクト, イベントといった異なる要素の間の関係を表します。オントロジーは書く要素とそのプロパティを定義するものです。
このセマンティックなアプローチは、異なるコンセプトとその間のつながりを一緒に表現しようとするものでした。例えばGoogleは、ナレッジグラフを使って、検索クエリの単語をマッチさせるだけでなく、クエリが表現するエンティティを見つけ出します。これは、キーワード検索の限界を回避する方法であると言えます。
しかし、実際のところとしては、ナレッジグラフやオントロジーのアプローチは、異なるトピックへのスケールやポーティングがとてもに難しく、スポーツチーム、世界のリーダー、あるいは商品の属性など、トピックがすぐに古くなってしまうものもあります。つまり、あるドメイン用に構築したナレッジグラフやオントロジーは、他のドメインに移行することが簡単には出来ないということです。あるトピックにおいては非常に堅牢なソリューションを構築できたとしても、異なる専門分野が必要とされる別のトピックにおいては失敗してしまう可能性があるといことです。そして、そのナレッジグラフを自動で構築できたのは、Googleをはじめとする一部の大企業だけでした。他のほとんどの企業は、手作業で構築しなければなりませんでした。
Autocomplete(オートコンプリート): 2004年に開始
オートコンプリートは、ユーザーが探している結果により早くたどり着けるようにするのを効果的に支援する非常に便利なセマンティック検索ツールです。最も有名な例は、2004年の終わりにオートコンプリートをリリースしたGoogleです。
オートコンプリートは、ユーザーがクエリーを入力する際に、検索キーワードを予測して後押しするといったアプローチになります。また、そのコンテキストに応じたサジェストを行うことで、ユーザーがタイプミスをしないように支援して、ユーザーが居る場所や趣向などに基づいてコンテンツをフィルタリングします。サジェストは、複数の機械学習および自然言語処理アルゴリズムとそのモデルによる一連のアルゴリズムによって生成され、シンプルなプレフィックス文字列から始まり、マッチング、そして結果の予測を行うことで未完成の検索クエリを補完します。
オートコンプリートを効果的に機能させるためには、検索エンジンが全てのセッションで使える多くのデータを持ち、更に、ユーザーの行動、以前行った検索、ロケーション、その他の属性に基づいて、ユーザーごとの検索クエリを予測できる必要があります。
予測型のオートコンプリートは、現代の競争力のある検索エンジンに期待される機能になってきています。
AIによるランキング: 2007年に開始
BM25のような初期型のキーワード統計モデルは、上述のように、単語の出現頻度を用いて適合性を構築していました。AIによるランキングにおいては、適合性を明確に特定するためにユーザーからのフィードバックを取り入れることで、大きな一歩を踏み出しました。その一例が、強化学習です。強化学習の基本的な考え方は非常にシンプルで、ポジティブな結果を強化するためにフィードバックを利用することです。強化学習では、大きな変化を頻繁に起こすのではなく、インクリメンタルな変化を頻繁に起こします。これには、結果を継続的に改善したり、他の潜在的な結果をより早く見えるようにするなど、多くの利点があります。また、パフォーマンスの低い結果は、段階的な実験によってすぐに無くなていく傾向にあります。
オートコンプリートと同様に、強化学習は意味のある結果を返すために多くのデータを必要とします。過去の重要なパフォーマンスデータがない場合は、強化学習は不十分なソリューションとなってしまいます。さらに、強化学習は検索結果のランキングには非常に適している傾向があるものの、レコードの特定には役立ちません。マッチするレコードを特定するには、依然としてキーワードと言語的なリソースに依存します。
そこでベクトルの登場です。
ベクトル検索: 2013年に開始
テキストのベクトル表現は古くからあるものです。その理論的なルーツは1950年代にまで遡り、数十年の間にいくつかの重要な進歩がありました。私たちは2013年に大きなイノベーションを目の当たりにしました。大規模なトレーニングセットを活用したニューラルネットワークに基づく新しいモデル(特にGoogleによる2018年のBERT)がスタンダードになりました。
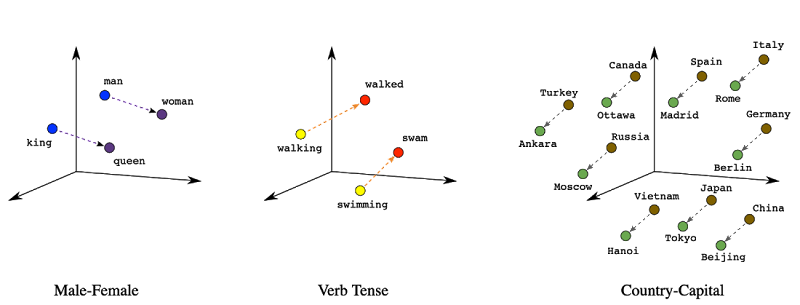
ベクトル検索とは何でしょうか?シンプルに言うのであれば、類似した特性を持つような関連したオブジェクトを見つけるための方法です。マッチングは、インデックス内のオブジェクト間の意味的な関係を検出する機械学習モデルによって実現されます。ベクトルは何千もの次元(dimension)を持つことができますが、シンプルに上記のようにベクトルを3次元の図で視覚化することもできます。ベクトル検索では、単語間の関係を繋げることができ、類似したベクトルはクラスタ化されます。”king” “queen” “royalty” といった言葉は同じクラスターに属し、”run” “trot” “canter ” もまた同様にクラスター化されます。
テキスト、画像、ビデオ、音楽など、ほとんどのオブジェクトはエンベデッドされベクトル化することができます。初期のベクトルモデルは、単語を次元として使っていました。異なる単語がすべて次元で、値は単語のカウントで、これはシンプル過ぎたのかもしれません。しかし、潜在的な意味の解析(LSA: Latent Semantic Analysis)と潜在的な意味のインデクシング(LSI: Latent Semantic Indexing)の登場によって、次元の数を減らすことで文書とその中に含まれる単語の関係を分析するようになり、状況は変わってきました。現在では、ベクトルエンジンを搭載した新しいAIモデルが、高次元空間の情報を素早く検索することができるようになっています。
これは、ゲームチェンジャーとなりました。新しいベクトルベースのソリューションでは、”snow” “cold” “ski” が関連するアイデアであることが分かるようになりました。この進歩にって、先程述べた他の技術、例えば固有表現の抽出、オントロジー、ナレッジグラフなどの一部は時代遅れとなってしまいました。
それでは、なぜベクトルはすべての検索に力を発揮しないのでしょうか?理由は大きく2つあります。ひとつは、速度が遅く、スケールにコストがかかること。もうひとつは、ベクトル検索は、いくつかの重要なユースケースにおいて、単純なクエリと同じ品質の結果を返せないということです。
オンラインでは、消費者たちは検索結果を瞬時に得られることを期待しています(AmazonとGoogleは、100ミリ秒の遅延が消費者の行動に及ぼす悪影響について調査を行っています)。ベクトルのデリバリーを高速化し、スケールさせることは可能ですが、それには高価なコストがかかりますし、キーワード検索と比較して同等のスピードとなることはないでしょう。
ベクトルはまた、いくつかのクエリにおいては、キーワード検索と同じ品質の適合性を提供することはできません。キーワード検索は、シングルワードのクエリやブランドでの完全一致のクエリでは、依然としてベクトルよりも有効です。複数ワードによるクエリ、コンセプト検索、質問形式、その他より複雑なクエリタイプでは、ベクトルがより効果的に機能する傾向があります。例えば、キーワードエンジンで “Adidas” と検索した場合、デフォルトでは、アディダスというブランドのみが表示されますが、ベクトルエンジンのデフォルトの動作は、”Adidas” というクエリに対して、すべての靴ブランド(Nike, Puma, Adidas 等)を表示します。キーワード検索は、より良い、そしてより説得力のある(そしてチューニングしやすい)結果を提供します。
では、どうすれば両方の長所を活かせるのでしょうか?そこでハイブリッド検索です。
ハイブリッド検索: 2022年〜
ハイブリッド検索は、キーワード検索エンジンとベクトル検索エンジンを1つのAPIにまとめた新しい手法です。
同じクエリに対して、キーワードエンジンとベクトルエンジンの両方を同時に実行するのは、非常に複雑なことです。キーワード検索を行って、ある適合性の閾値を満たさない場合は、ベクトル検索を行うというように、これらのプロセスをシーケンシャルに実行することで、複雑さを回避している企業もありますが、この方法の場合はスピード、精度、各モデルの学習能力の制限など、多くの残念なトレードオフが発生してしまいます。
本物のハイブリッド検索は違います。キーワード検索とベクトル検索を1つのクエリに統合することで、ユーザーはより正確な結果を素早く得ることができます。もちろん、ベクトル検索をキーワード検索と同じように高速に動作させるために、非常識なコストを追加することなく、性能面でスケールさせることが必要です。今日のほとんどのベクトルエンジンでは、これは不可能でしょう。
そこで、Search.io から買収した新しいテクノロジーである Neuralsearch™ の出番です。Neuralsearchは、スケールやクエリのスループットに関係なく、シングルミリ秒のクエリ時間を実現する唯一無二のハイブリッド検索サービスです。
こちらは、ベクトルをファイルサイズの1/10に縮小し、特別なハードウェアやGPUを必要としないハッシュ化技術によって実現されています。ハッシュの仕組みについてここで詳しく説明することはしませんが、ベクトルとハッシュ化の比較についてはブログ記事でまとめています。しかし、私たちは驚異的な結果を目の当たりにしました…
- 爆速なキーワード検索に匹敵する性能
- セマンティック検索とキーワード検索を併用することでの格段な精度向上
ワンクリックの学習モジュールで例外の再学習をより簡単に(UIの追加および詳細はcoming soon!)
次の10年
10年後に検索技術がどうなっているかを予測することは難しいですが、ほぼ間違いなくハイブリッド検索(キーワード検索とベクトル検索の組み合わせ)で構成され、どちらかの技術だけというものよりも精度が高くなっているのではないかと思います。
もしあなたがセマンティック検索の実装を任されている技術リーダーであるならば、セマンティック技術の主要なマイルストーン、私たちが現在どこにいて、そして将来的にどのような状況になるかを理解するお役に立てたのであれば幸いです。


コメント