
AlgoliaのBenjamin BARON(@benjbaron)がAlgoliaのブログに書いた記事の翻訳になります。Algoliaの機能改善のやり方が垣間見える内容になっているかなと思いますので是非ご覧ください。また、私自身がBigtableにあまり馴染みがなく、翻訳が不適当な部分がございましたら @shinodog までメンションいただければ幸いですmm
Our journey to optimize Bigtable’s schema for performance
Algoliaの Personalization は、お客様の目的にあったパーソナライズドな検索体験を提供するものになりますが、こちらの機能のご利用者数が日に日に増え続けています。そこで、増加する負荷に対応できるようにするため、Algoliaではリアルタイムな検索であれ、テラバイト級のデータの分析であれ、スケーラブルな最高のプロダクトを提供するために改善を重ねることを常としております。この機能はGoogle Cloud PlatformでホストされているマネージドなデータベースであるBigtableに大きく依存していますが、今回そのBigtableのスキーマを変更することでユーザープロファイルに関する計算が3倍も向上することが判明しました。こちらの記事では Personalization 機能のパフォーマンス改善がどのように行われたのかについて深堀りし、その中でのキーとなるラーニングについて取り上げていきたいと思います。
Personalized search at Algolia
Algoliaにおけるパーソナライゼーションは、ユーザーによるイベント、すなわちview, click, そしてconversionを元に作られたユーザープロファイルによって行われます。これらのイベントは Insights API を通じて type(view/click/conversion) と 、name (例えば “homepage”) と、オブジェクトのidentifier が送信されます。
ユーザーがホームページでブラックのApple iPhoneをクリックしたとします。Algoliaは以下のようなインベントを受け取ります。user_token はanonymize(匿名化)された一意のユーザー識別子です(Algoliaによって自動生成も可能ですし、お客様がユーザーを識別するIDを既に保持している場合はそちらを使っていただくこともできます)
{
"app_id": "app",
"user_token": "24d64a80-8d1c-11e9-bc42-526af7764f64",
"object_ids": ["af3d4d14-8d1c-11e9-bc42-526af7764f64"],
"timestamp": "2019-05-28T00:04:34.000Z",
"event_type": "click",
"event_name": "homepage"
}製品を見たりクリックしたり購買したり、といったユーザーの行動がイベントを生成、そこからAlgoliaはユーザープロファイルを作成します。ユーザープロファイルはカテゴリやブランドなどに対するユーザーの親和性と関心を表します。より詳細に説明すると、ユーザープロファイルはkey-value structureで、スコアに関連付けされたfilterによって構成されています。以下の例では、filterである color:Red はスコアが12で、これはユーザーと色が red であるアイテムとのやりとりの量によって決定されます。
color:Red -> score: 12
brand:Apple -> score: 10
color:Black -> score: 8
brand:Sony -> score: 3
brand:Samsung -> score: 2ユーザープロファイルにおけるfilterのスコアは各イベントの重み付け(e.g. conversion, view, click)と、イベントに関連する各フィルターの重要度を定義する strategy によって決定されます。
クエリ時に、該当のユーザープロファイルを使って、一致するフィルターで最も適合度の高いアイテムをブーストします。これによってユーザーにシームレスなパーソナライズド体験が提供される、という流れです。
Building real-time user profiles
Algoliaではスピードを非常に重要視しており、ユーザーにリアルタイムなパーソナライズ体験を提供することを目指しています。更に上記でご紹介させていただいたようなパーソナライズのstrategy(スコアの重み付け)が変更された場合も、できるだけ早く新しいstrategyを全てのユーザープロファイルに適応させたいと考えています。
上記により、ユーザープロファイルを計算およびアップデートするための2つのそれぞれ独立したパイプラインを構築することになりました:
- streaming pipeline – イベントを受け取った際の該当ユーザーのユーザープロファイルの計算
- batching pipeline – strategyが更新された際に発生する全てのユーザーのプロファイルの再構築
これらのパイプラインは、Google Cloud PlatformでホストされるKubernetesクラスタにデプロイされています。また、大量のデータに対する高いreadとwriteのスループットに対応するためユーザーからのイベントデータはBigTableに格納しています。multi-tenantなシステムとして使用されるBigtableのスキーマはそれぞれのAlgoliaのお客様のデータを確実に分離するための強力な保証(strong guarantee)を提供します。以下はパーソナライズパイプラインのハイレベルなアーキテクチャの図になります。
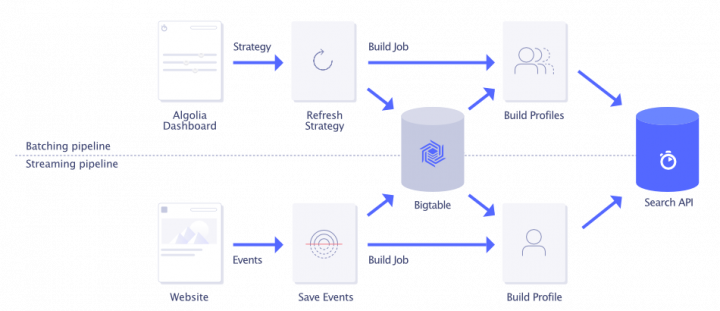
Scaling the batching pipeline
より多くの顧客がパーソナライズ検索を利用するにつれて、ユーザープロファイルの計算の際に増加する負荷をハンドリングしなければなりません。特にbatching pipelineがスケールすることを担保する必要があります。例えば、90日間のデータ保持期間において、1日に平均1000万回イベントが送信されたとして、strategyが更新されると合計で9億件のイベントを処理する必要があります。
パイプラインのパフォーマンスは主にBigtableのreadスループットに依存するため、様々なスキーマでBigtableにデータを保存し、それがどのようなパフォーマンスのインパクトをもたらすか調査を行い、そして、処理のために取得するベントの数がパイプラインの処理時間にどのように影響を与えるか評価をしたいと考えました。
Background on Bigtable
Bigtableは、水平方向にスケールするように設計されている、構造化データを管理するための分散ストレージシステムです。2004年からGoogleの中で開発されていて、2015年にGoogle Cloud Platformの一部として公開されました。
Bigtableはデータをsorted mapとして保持し、row key, column key, そしてtimestamp によってインデックスされます。
(row:string, column:string, time:int64) -> []byteデータは row keyによってlexicographical order(辞書順)に保持され、このことによってプレフィックスを指定することで行のrangeクエリを行うことが可能になります。column keyは family key と qualifier によって構成されます。データはtableとfamily keyによって分割され、individualなtablets(物理ハードドライブ)に一緒に保存されるため、family keyにはいくつかの制約があります: テーブルを作成する際にテーブル名と共にfamily keyを指定する必要があり、同じfamily keyの場合は同じアクセスパターンの要素をストアすることが推奨されています。更に、ドキュメントにはalphanumericな文字のみであまり多くないfamily key(100 at most)が推奨されると記述されています。一方で、qualifierは制約が少なくarbitrary(任意)の文字列を保持することができます

Bigtable schema
Bigtableのスキーマをデザインする上で、row keyのフォーマットとrow valueの構造を決める必要があります。
Row key。row keyの設計はユースケースとアクセスパターンにより行われます。上記でご説明したように、全ての顧客もしくはユーザーの中の1人が送信した全てのイベントにアクセスする必要があります。そにため、プロファイルを作成するたびにユーザーの全てのイベントを取り込む必要があり、読み込みは書き込みよりも重要です。ソートされたキーのブロックで効率的にスキャンをを行うためには、関連する行が互い近いところにある必要があります。そのため、私達は顧客(app_idがidentifier)およびユーザー(user_tokenがidentifier)のシーケンシャルなスキャンを可能とする以下のスキーマデザインをしました。
app_id,user_token,YYYY-mm-DDTHH:MM:SS.SSSZRow value。 row value は、column key (with a family key and qualifier) と column valueで構成されます。rowの値には以下で構成されるイベントが格納されます:
- Event type (conversion, click, view)
- Event name (user defined, e.g., homepage)
- List of filters (of the format
filter_name, filter_operator, filter_value)
Narrow and wide row values。row valueスキーマの構成には様々な方法があります。1つのスキーマが全てのデータ構造をrowのvalueとして保持する方法では、tall and narrowなテーブルが出来上がります。family nameとqualifierが割り当てられ、少数のイベントが各rowに保持されるような形になります。一方で、複数のfamiliesとqualifiersを同じrowに格納し、階層化された構造をvalueとして保持する方法もあります。この場合、short and wideなテーブルが出来上がり、それぞれのrowで沢山のイベントが格納できることになります。


Narrow schema
さまざまなevent typeが固定されていて、且つ、alphabeticな文字で構成されているため、family keyの候補として適していると言えるでしょう。一方でuser nameはユーザーに定義されたものであり、カーディナリティが高い(値の種類が沢山ある)のでfamily keyには適しません。しかし、それはqualifierにはなりえます。filterカウントのリストをvalueとしてJSONフォーマットにエンコーディングできます。例えば、Bigtableとやりとりを行うための公式コマンドラインツールであるcbtを使ってテーブルの行を読み取る際に読み取り可能な値を設計可能です。
この場合のスキーマは以下のようになります。
row: app_id,user_token,timestamp
family key: event_type
qualifier: event_name
value: [filter_counts]これが今日まで私達がイベントを保持してきたスキーマになります。
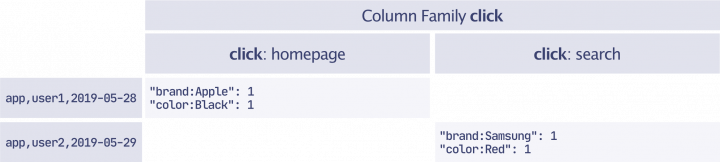
その結果、次の2つのイベントが以下のようにテーブルに保存されます。(タイムスタンプは見易いように省略形になっています)
[{
"app_id": "app",
"object_ids": ["black-apple-iphone"],
"user_token": "user1",
"timestamp": "2019-05-28",
"event_type": "click",
"event_name": "homepage"
},
{
"app_id": "app",
"object_ids": ["red-samsung-s11"],
"user_token": "user2",
"timestamp": "2019-05-29",
"event_type": "click",
"event_name": "search"
}]
Wide schema
上記で定義したnarrow schemaでは各イベントに関連付けられた全てのフィルターを取得してユーザープロファイルを計算する必要があります。しかし、私達はstrategyによって定義されたフィルターからユーザープロファイルを計算しています。これはイベントに含まれるフィルターのサブセットとなります。フィルターを破棄する必要が出てきた場合に高いスループットが必要になり、メモリのオーバーヘッドが発生してしまう可能性があります。
その代わりに、wide schemaはfamilyとqualifiersを使ってwide rowフォーマットを作成し、サーバー側でイベントフィルター名による処理が行われます。フィルターはstrategyの名前で定義されるため、filter nameとqualifierを使ってrow valueにインデックス付けすることができます。family keyにはフォーマットと数に制限があるので、qualifierだけを使ってrow valueにfilter nameでインデックス付けを行うことになります。結果的には、タプル(event_type, event_name, filter_name)をエンコードし、CSVフォーマットでqualifierとしました。family nameは100文字までの制限があり、事前定義が必要なため、costomer-defined valuesに使うことはできません。その代わりに私達は”e“という一文字をfamily keyに使用しました。これによって全てのrowがネットワークを介して送信される際のネットワークのオーバーヘッドを最小限に抑えています。また、family keyにはバージョニングのセマンティックを設定できるので、あるfamilyから他のfamilyにデータを移す時に便利です。row valueは filter_operatorとfilter_value の配列のカウントのなります。strategyに存在するフィルターに基づくインターリブなフィルターを使ってrowのqualifiersはクエリされます。
上記によりwide schemaは以下のようになりました:
row: app_id,user_token,timestamp
family key: e
qualifier: CSV(event_type, event_name, filter_name)
value: [(filter_operator,filter_value)]以下は、上記の2つのイベントを取得する場合のテーブルの例です:

Choice of schema scales performance
イベントを送信するアプリケーションがいくつか存在するため、2つのスキーマのパフォーマンスを比較できるように実際に起こりうるイベントをシミュレーションすることにしました。毎日数百万のイベントを送信する少数のユーザーから、毎日数件のイベントを送信する数百万人のユーザーまで様々なアプリケーションプロファイルを作成しました。そして、上記のnarrowとwideの2つのスキーマを使ってステージング環境のBigtableインスタンスに2つのテーブルを作成しました。
2つのスキーマで実装およびテストを行った後、私達は(GCSやStackdriver logsを含む)他のサービスへのread/writeにおいて、計算処理に紐づくオーバーヘッドを取り除きました。イベントの”raw” readはBigtableからのみ行われ、そのイベントデータからユーザーユーザープロファイルの計算を行うようにしました。テストを実行するため、各アプリケーションのプロファイルとテーブルスキーマのプロファイルの作成を何度も連続して行いました。これによって複数のテストが並列的に行われることがなく、各テストのパフォーマンスに影響を与えることを防ぎました。
テスト結果は以下の表のようになりました。イベントの数が増えると全スキーマでイベントを読み取りユーザープロファイルを計算するのに直線的により多く時間がかかるようになるのが見て取れます。シナリオに関係なくレガシーなスキーマのパフォーマンスは一番低く、90日間に1日あたり100イベント発生する100万人のユーザープロファイルを計算するのに最大16.6時間(60,000秒)かかっています。明らかにwide schameではユーザープロファイルの計算に無視できない大きな影響を与えることが証明されました。これによってwide schemaに移行するという決定は簡単なものになりました。

私たちは今までのnarrow schemaから最も効率の良いwide schemaに移行することに決めました。そして、以下の3つのステップでマイグレーションを行いました:
- wide schemaのテーブルを作成し、narrowとwideの両方にデータを保持することにしました
- 1週間が経過したのち、90日間のりテンション期間の全イベントデータをwide schemaのテーブルにバックフィルしました
- ユーザープロファイルの計算をnarrow tableからwide schemaのテーブルに切り替えました
Caveats
スキーマの変更は、特にクライアント(k8sのpod)側で app_id と user_token の両方のジョブにポジティブなインパクトをもたらしました。これはユーザートークンに紐づく大量のイベントデータを取得する際に、各podが使用するネットワーク帯域、CPU、そしてメモリを削減することができたためです。ただし、このソリューションにはwide schemaに移行するという最終的な選択をするにあたりいくつかの警告があります。
Storage and computation. wide schemaはBigtableクライアントのリソースを節約することが出来るものの、Bigtableサーバーのストレージと計算のオーバーヘッドは発生します。Bigtableはrow valueに圧縮を効かせるため、row valueの値が大きければ大きいほど効率的です。wide schemaでデータを保持するとレガシースキーマと比較してストレージの使用量が増加しましたが、私たちにとっては問題ではありませんでした。更に、rowのフィルタリングにおいてはBigtableサーバー側で適用されるため、narrow schemaと比較して追加の計算オーバーヘッドが発生してしまい、推奨されている80%のリミットを下回っています。
Number of qualifiers. facet数にリミットを設定する必要があるものの、私たちは、顧客が定義したstrategyはデータのフィルタリングに必要な全てのfacetをカバーしないという仮説を立てたため、wide schemaは機能しているといえます。但し、全てのfacetがstrategy内で利用される場合もnarrow schemaと同等のパフォーマンスを発揮することは可能です。
It’s all about trade-offs
Bigtableのusageとアクセスパターンは、スキーマデザインによってドライブされます。私たちの場合は、データを1回書き込むだけで、単一のuser_tokenジョブもしくはapp_idジョブを使って複数回アクセスをする必要があるため、読み取りアクセスの最適化を施す必要性がありました。最適化には3つのレベルがあります。
row keyがBigtableに保存されているデータの読み取りとアクセスに関して最も重要であると言えます。rowはrow keyでlexicographically(辞書式)にソートされるため、関連する行、またはソートされたキーのブロックの効率的なスキャンのために、お互いに近くに格納される必要があります。マルチテナントの場合はrow keyの先頭にアプリケーションのitendifierを付けています。これによって特定のユーザーだけでなく、garbage collection等の管理タスクのためにアプリケーションをシーケンシャルにスキャンするジョブのパフォーマンスが向上します。キーをアプリケーションごとにグループ化すると、頻繁に使用されるアプリケーションのホットスポッティングにつながってしまう可能性がありますが、それらは複数の計算ノードで実行されるかもしれません(他のアプリケーションと比べてより多くのデータを生成しているため)。これについては大規模なアプリケーションだけ他の専用テーブルに移動させることで、他のアプリケーションのパフォーマンスの低下を防ぐことができるかもしれません。
row schemaはBigtableサーバーの計算とストレージのオーバーヘッドと、クライアント側の計算量とネットワーク帯域のトレードオフに繋がります。wider rowsはサーバー側のオーバーヘッドが増加してもフィルタリングはより良くなりますが、一方でnarrow rowsはセルの値を全て取得する必要があるのでクライアント側のフィルタリング処理が遅延します。
最後に、row valueはバイト配列(byte [])として格納されるため、必要に応じて高速なJSON marshallerと、複雑なProtocol BuffersもしくはGobなどのカスタムフォーマットを使ってrowのエンコーディング最適化を行うことが出来ます。
Algoliaでは、成長に伴って、増え続けるお客様に対するための計画を進めています。Bigtableを使って数十億のイベントを処理および保存する方法を改善することで、パーソナライゼーション機能をスケールさせ、機能を改善するために今後数ヶ月におけるチャレンジを見出すことができました。

コメント