Solrのオフィシャルページで12 April 2012 – Apache Solr 3.6.0 available っていう事で。
我々日本人にとって一番大きいのは↓かな、と。
New Kuromoji morphological analyzer tokenizes Japanese text,
producing both compound words and their segmentation. (SOLR-3056)
↓にイイ感じにまとまっていますが、Lucene-Gosenと比べても遜色なさそうな。
Solrの日本語対応 -新しく追加されたトークナイザ・トークンフィルタ- | 株式会社ロンウイット
Kuromojiは以前、開発者の方にお話を伺った事があるのですが↓
Kuromoji(ピュアJavaでナイスなライセンスの形態素解析エンジン)を試してみる | shinodogg.com
サーチモードとかなかなか良さ気です→http://www.atilika.org/
んま、前置きはそんな感じにして、MacBook Proにインストールしてさっそく動かしてみます。
■ Tomcat7.0.27のインストール
Tomcatのダウンロードページから apache-tomcat-7.0.27.tar.gz を落としてきて、
/usr/local配下に解答してやって、/usr/local/tomcatにリンク貼ってやります。
# pwd /usr/local ln -s apache-tomcat-7.0.27 tomcat # ls -l | grep tomcat-7 drwxr-xr-x 13 root wheel 442 4 16 11:24 apache-tomcat-7.0.27 lrwxr-xr-x 1 root wheel 20 4 16 11:24 tomcat -> apache-tomcat-7.0.27
■ solr.warをTomcatのwebappsに
Solrのダウンロードページから apache-solr-3.6.0.tgz を落としてきて解凍して、
exampleにあるwebapps/solr.warをTomcatのwebappsにコピーします。
# cp solr.war /usr/local/tomcat/webapps/
■ Tomcatのserver.xml
Connector定義に以下を追加する
useBodyEncodingForURI=”true”
■ webappsのsolrのWEB-INFのweb.xml
SolrRequestFilterの手前にSetCharacterEncodingの定義を追加する
<filter>
<filter-name>SetCharacterEncoding</filter-name>
<filter-class>org.apache.catalina.filters.SetCharacterEncodingFilter</filter-class>
<init-param>
<param-name>encoding</param-name>
<param-value>UTF-8</param-value>
</init-param>
</filter>
<filter-mapping>
<filter-name>SetCharacterEncoding</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>
■ exampleのsolrをTOMCAT_HOMEにコピってくる
Tomcatのcatalina.propertiesに以下を設定。
#Solr configuration
solr.solr.home=/usr/local/tomcat/solr
#んま、場所はここじゃなくてもイイんだけど。。
#個人的にはあっちこっち行きたくないのでTomcatの中に入れちゃうのが好き。
そんな感じでTomcatを再起動してブラウザからアクセスしてみます。
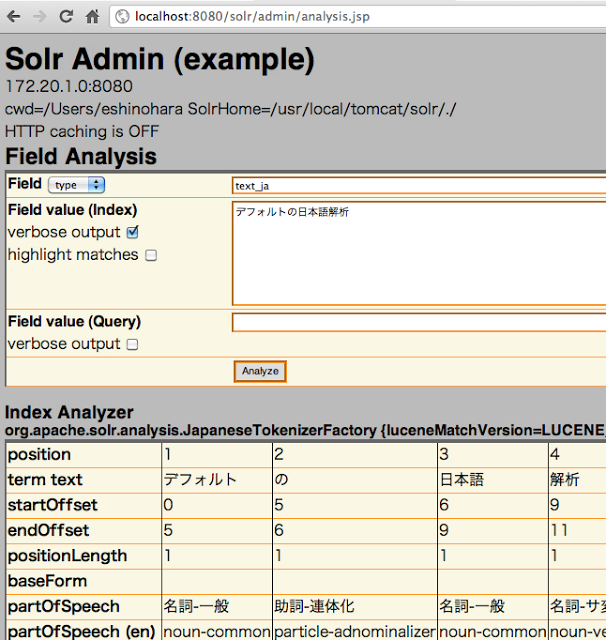
解析機能を動かしてみると type text_ja で↓のようになりました。

上記での text_ja は schema.xml を見ると、下記のようにガッツリ書いてあります。
チョロっと解説すると、デフォルトでは以下のように動作します。
■ サーチモードがデフォルト
<tokenizer class=”solr.JapaneseTokenizerFactory” mode=”search”/>
例) 関西国際空港
関西国際空港:名詞-固有名詞-組織
関西:名詞-固有名詞-地域-一般
国際:名詞-一般
空港:名詞-一般
■ 基本形にするノーマライズ
<filter class=”solr.JapaneseBaseFormFilterFactory”/>
例) 思った → 思う
■ 品詞ごとのSTOP設定が lang/stoptags_ja.txt がお手軽に設定可能
<filter class=”solr.JapanesePartOfSpeechStopFilterFactory”
tags=”lang/stoptags_ja.txt” enablePositionIncrements=”true”/>
例) 食べたからには → 食べる
助詞-格助詞-連語 はSTOPするという設定
■ 半角カナは全角カナにノーマライズ
<filter class=”solr.CJKWidthFilterFactory”/>
例) ガガ→ ガガ
■ STOP Wordが lang/stopwords_ja.txt に100以上ガッツリ
<filter class=”solr.StopFilterFactory” ignoreCase=”true”
words=”lang/stopwords_ja.txt” enablePositionIncrements=”true” />
例) 風と共に → 風
stopwords_ja.txt の 121行目に “と共に” が入ってる
■ U+30FCの「ー」(長音記号)は除かれる
<filter class=”solr.JapaneseKatakanaStemFilterFactory” minimumLength=”4″/>
例) メモリー → メモリ
ただし、minimumLength=”4″なので ソラー はそのまんま。
■ LowerCase
<filter class=”solr.LowerCaseFilterFactory”/>
例) CAT → cat
以下、schema.xmlのtext_jaの部分です。
<!-- Japanese using morphological analysis (see text_cjk for a configuration using bigramming)
NOTE: If you want to optimize search for precision, use default operator AND in your query
parser config with <solrQueryParser defaultOperator="AND"/> further down in this file. Use
OR if you would like to optimize for recall (default).
-->
<fieldType name="text_ja" class="solr.TextField" positionIncrementGap="100" autoGeneratePhraseQueries="false">
<analyzer>
<!-- Kuromoji Japanese morphological analyzer/tokenizer (JapaneseTokenizer)
Kuromoji has a search mode (default) that does segmentation useful for search. A heuristic
is used to segment compounds into its parts and the compound itself is kept as synonym.
Valid values for attribute mode are:
normal: regular segmentation
search: segmentation useful for search with synonyms compounds (default)
extended: same as search mode, but unigrams unknown words (experimental)
For some applications it might be good to use search mode for indexing and normal mode for
queries to reduce recall and prevent parts of compounds from being matched and highlighted.
Use <analyzer type="index"> and <analyzer type="query"> for this and mode normal in query.
Kuromoji also has a convenient user dictionary feature that allows overriding the statistical
model with your own entries for segmentation, part-of-speech tags and readings without a need
to specify weights. Notice that user dictionaries have not been subject to extensive testing.
User dictionary attributes are:
userDictionary: user dictionary filename
userDictionaryEncoding: user dictionary encoding (default is UTF-8)
See lang/userdict_ja.txt for a sample user dictionary file.
See http://wiki.apache.org/solr/JapaneseLanguageSupport for more on Japanese language support.
-->
<tokenizer class="solr.JapaneseTokenizerFactory" mode="search"/>
<!--<tokenizer class="solr.JapaneseTokenizerFactory" mode="search" userDictionary="lang/userdict_ja.txt"/>-->
<!-- Reduces inflected verbs and adjectives to their base/dictionary forms (辞書形) -->
<filter class="solr.JapaneseBaseFormFilterFactory"/>
<!-- Removes tokens with certain part-of-speech tags -->
<filter class="solr.JapanesePartOfSpeechStopFilterFactory" tags="lang/stoptags_ja.txt" enablePositionIncrements="true"/>
<!-- Normalizes full-width romaji to half-width and half-width kana to full-width (Unicode NFKC subset) -->
<filter class="solr.CJKWidthFilterFactory"/>
<!-- Removes common tokens typically not useful for search, but have a negative effect on ranking -->
<filter class="solr.StopFilterFactory" ignoreCase="true" words="lang/stopwords_ja.txt" enablePositionIncrements="true" />
<!-- Normalizes common katakana spelling variations by removing any last long sound character (U+30FC) -->
<filter class="solr.JapaneseKatakanaStemFilterFactory" minimumLength="4"/>
<!-- Lower-cases romaji characters -->
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>

技術評論社
売り上げランキング: 29354

コメント
[…] Apache Solr – Solr 4.0 登場 | にょきにょきブログ Solr3.6でKuromojiを試した時はTomcatを使いましたが、 […]