2年くらい前は結構Solr使ってたんだけど↓今では遠い昔のようであんまり記憶にございません、とw
- Solrをイジった備忘録その1(データ投入編)
- Solrをイジった備忘録その2(TomcatでLog4Jでログ出力)
- Solrをイジった備忘録その3(レプリケーション編)
- Solrをイジった備忘録その4(Apache/文字コード)
- SolrにRequestHandlerを追加する
- SolrのレプリケーションでSnapPull failedエラー
- Solrの範囲検索は結構重い(まぁ、そりゃそうか。。)
またSolrをイジるようになるかも的な感じなので、久しぶりにググってたら、
↓をのブログを発見して、lucene-gosenってとてもナイスっぽい感じなのでイジってみました。
Java製形態素解析ライブラリ「lucene-gosen」を試してみる
■ lucene-gosenを単体で動かす
とりあえずSolr行く前に上記のブログに習ってlucene-gosenを単体で試してみます。
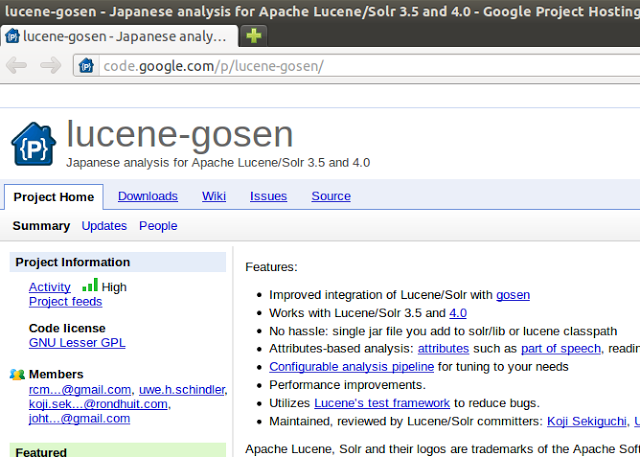
http://code.google.com/p/lucene-gosen/にアクセスしてみると、
↓のようにSolr3.5~って感じになっているようです。

ダウンロードページに行くと↓がダウンロード出来るようになっています。
・Naist(奈良先端科学技術大学院大学)のChasen辞書付きのjar
・IPA(独立行政法人 情報処理推進機構)の辞書付きのjar
・辞書なしのjar

Naistは職場でお世話になってるid:tullioの母校という事でそっちにしてみました。
とりあえずMavenでjarファイル落としてきたいわけなんですが、
↓のチケットみるとまだって事なんですかね~
Issue 20: Register maven central repository
ってことで↓こんな感じでローカルにインストールしましたよ、と。
#Maven3じゃないの?とかそういうのは置いておいてw
>C:apache-maven-2.2.1binmvn install:install-file -DgroupId=org.apache.lucene -DartifactId=lucene-gosen-naist-chasen -Dversion=1.2.1 -Dpackaging=jar -Dfile=C:UsersoreoreDownloadslucene-gosen-1.2.1-naist-chasen.jar
[INFO] Scanning for projects...
[INFO] Searching repository for plugin with prefix: 'install'.
Downloading: http://repo1.maven.org/maven2/org/apache/maven/plugins/maven-install-plugin/2.2/maven-install-plugin-2.2.pom
Downloading: http://repo1.maven.org/maven2/org/apache/maven/plugins/maven-install-plugin/2.2/maven-install-plugin-2.2.jar
[INFO] ------------------------------------------------------------------------
[INFO] Building Maven Default Project
[INFO] task-segment: [install:install-file] (aggregator-style)
[INFO] ------------------------------------------------------------------------
Downloading: http://repo1.maven.org/maven2/org/codehaus/plexus/plexus-digest/1.0/plexus-digest-1.0.pom
Downloading: http://repo1.maven.org/maven2/org/codehaus/plexus/plexus-components/1.1.7/plexus-components-1.1.7.pom
Downloading: http://repo1.maven.org/maven2/org/codehaus/plexus/plexus-digest/1.0/plexus-digest-1.0.jar
[INFO] [install:install-file {execution: default-cli}]
[INFO] Installing C:UsersoreoreDownloadslucene-gosen-1.2.1-naist-chasen.jar to C:Usersoreore.m2repositoryorgapachelucenelucene-gosen-nais
t-chasen1.2.1lucene-gosen-naist-chasen-1.2.1.jar
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESSFUL
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 4 seconds
[INFO] Finished at: Fri Feb 10 18:37:44 JST 2012
[INFO] Final Memory: 4M/122M
[INFO] ------------------------------------------------------------------------
でもって、pom.xmlに↓のように定義を入れてやります。
<dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-gosen-naist-chasen</artifactId> <version>1.2.1</version> </dependency>
↓みたいなコード書いてanalyzeしようとしたら、なんかdeprecatedとか言われて、、

↓ソースみてみたら、あー、そーゆー風な感じなんですねぇ的な。
#こーやってソース追ってるだけで、フィルター的に前処理とか後処理とか
#ちゃんとしてるよねぇって気がしてきたりします。
/**
* Decompose a string into its most likely constituent morphemes
*
* @param surface The string to analyse
* @return An array of {@link Token}s representing the most likely morphemes
* @throws IOException
*/
public List<Token> analyze(String surface, List<Token> reuse) throws IOException {
Sentence sentence = new Sentence(surface.toCharArray());
filterPreProcess(sentence);
List<Token> tokens = viterbi.getBestTokens(sentence, reuse);
tokens = filterPostProcess(tokens);
return tokens;
}
/**
* @deprecated use {@link #analyze(String, List)} instead.
*/
@Deprecated
public List<Token> analyze(String surface) throws IOException {
return analyze(surface, new ArrayList<Token>());
形態素解析した結果を出力してみます。
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import net.java.sen.SenFactory;
import net.java.sen.StringTagger;
import net.java.sen.dictionary.Token;
public class App
{
public static void main( String[] args )
{
// 辞書は内包されてるのでnullでOKみたいです。
StringTagger tagger = SenFactory.getStringTagger(null);
String str = "今夜はみんなでカレーを食べに行きます。";
List tokens = new ArrayList();
try {
tokens = tagger.analyze(str, tokens);
} catch (IOException e) {
e.printStackTrace();
}
// 名詞だけ抽出してみる
for (Token token : tokens) {
if (token.getMorpheme().getPartOfSpeech().contains("名詞")) {
System.out.println("= = = = =");
System.out.println("surface : " + token.getSurface());
System.out.println("partOfSpeech : " + token.getMorpheme().getPartOfSpeech());
System.out.println("readings : " + token.getMorpheme().getReadings());
}
}
}
}
イイ感じです。
= = = = = surface : 今夜 partOfSpeech : 名詞-副詞可能 readings : [コンヤ] = = = = = surface : みんな partOfSpeech : 名詞-代名詞-一般 readings : [ミンナ] = = = = = surface : カレー partOfSpeech : 名詞-一般 readings : [カレー]
—

技術評論社
売り上げランキング: 26985

コメント
[…] « lucene-gosenを試してみる その1 […]
[…] Checkここのところ↓のようにlucene-gosenをいじっていますが、 lucene-gosenを試してみる その1 lucene-gosenを試してみる その2 […]