
Seasar Conference 2009 Autumnに行ってきました。
今回は、ひがやすをさんのGoogle App Engine,Google Web ToolKit,slim3のお話と、
Blogopolisのお話を聞いてきました。
GAE,slim3,BigTable周りは前回とあんまり内容が変わってないように感じましたが、
Google Web Toolkitは、中身がそういう風になってるんだーと大変勉強になりました。
Blogopolisはマジで激ヤバというか。すごすぎる。。。
# 昔はDIとかS2Daoとかの話が聞きたくて行ってたのに、
# 業務でS2使うようになってから逆にそういうセッションに出なくなるっていうw
以下、セッション毎の詳細です。
—
slim3入門
- slim3
- APP Engineで使える機能だけ使って
- simple & less is more
- less is more
- 近代建築のエロい人が言ってる言葉
- 省略の美
- 千利休の茶室の話
- 秀吉は庭の朝顔を楽しみにしてた。
- 秀吉が訪れたとき、庭の朝顔は全部切り取られてなくなってた
- 秀吉は、楽しみにしてたのに、、、と思っていたら、
- 通された茶室に1輪だけ朝顔が飾られていて、とてもキレイだった。
- パレートの法則
- 機能を絞っていくと2割くらいの実装で8割くらい実現可
- パレートの法則→less is more
- プログラマにとっての道具
- テストをすること
- TDDの1番最初のステップは自分がクライアントになったつもりでテストすること
- slim3の一番の特徴はTDDのサポート
- HOT Reloading
- TDDで一番大切なのはリズム。ノって開発している時は生産性が高い
- タイプセーフクエリ
- デモ
- libのjarを手動でパス通す。
- EclipseはWEB-INFのlibは勝手に通してくれるが、他はしてくれない。
- 自動で通すようにするとプロジェクト名がハードコードされてしまう。
- プロジェクト名が『slim3-blank』のまま、なんて人いないよね。
- slim3は依存jarはAppEngine以外にない
- web.xml
- slim3.rootPackageをいじる
- Jetty
- GoogleはJettyらしい。本番も。
- カスタマイズで省略が容易だから。
- Tomcatは基本一枚岩でカスタマイズしずらい。
- build.xml(コントローラ)
- gen-controllerでコントローラ自動生成
- /twitter/とか入れると
- 3つのファイルが生成される(controller, test, jsp)
- Test
- テストクラスのstartメソッドでブラウザからのリクエストをエミュレート。
- getDestinationPathでレスポンス先を取得
- slim3でのテスト
- IDEでテスト→緑になったら→ブラウザで確認
- Webアプリを作るなら常に見えるように
- build.xml(VIEWが要らないコントローラ)
- gen-controller-without-view。JSPが要らない場合は作らない
- basePath
- データをストアしてredirectで自分に返す時など
- build.xml(モデル)
- gem-model
- モデルのテストケース+daoを自動生成
- テスト
- startの前にparam(”content”, ”hello”)でリクエストパラメータがセットされる
- count(モデル.class)とか便利なのが追加されてる
- コントローラでデータをストア
- daoをnewしてリクエストの情報をモデルにつめて
- daoのmakePersistenceする。トランザクション用のもある。
- Datastore Viewer
- データがどうはいっているかチェックできる
- libのjarを手動でパス通す。
—
GWTではじめるFull Ajaxアプリケーション
- 会場内でGWT使ったことある人は全体の5パーセントくらい
- 既存のAjaxアプリの問題点
- どこがエラーか教えてくれない
- リファクタリングがつらい
- GWT使えばGmailみたいの書ける
- 個人的にちょっとついていけてないところ
- apt(annotation processing tool)
- アノテーションを処理するための機能
- TigerになってからちゃんとJava追いかけてないので
- この辺がピンとこなかったりします。勉強せな。
- apt(annotation processing tool)
- web.xml(GWTのリクエストを受ける用)
- warの中にある
- サーブレット:GWTServiceServlet
- *.s3gwtがURLパターン
- New GWT Module
- main.gwt.xmlというのができる
- New View Module
- モジュールは複数作る
- 一個のモジュールは入力→確認→登録 とか
- モジュール+エントリポイント+HTML
- New HTML Page
- main/main.nocache.js
- こいつから実際のモジュールがが起動される
- main/main.nocache.js
- 起動
- GWTのHostedモードの画面
- 本番ではJavaScriptだけど、このモードはJavaがそのまま動いてるので、
- ブレークポイント入れたらちゃんと止まる
- JSとJavaが同じように動く
- GWTのHostedモードの画面
- GWTの根本
- JSNI(JavaScript Native Interface)
- こいつでJavaScriptにアクセスする
- Javaのコードの中に↓のようにJSを記述(/*- この中 -*/)
- JSNI(JavaScript Native Interface)
public native void sayHello(String Hello) /*-{
alert(hello);
}-*/
- compile/browseってやるとJSが生成されて実ブラウザで稼動
- 今はテストの時にEclipseのSWTで動いてるけどGWT2系になると
- ブラウザ側にモジュール埋め込むようのがでてくるらしい
- MD5でハッシュ化された文字列.htmlが生成される
- ブラウザにキャッシュさせるけど、コンパイルし直したら、
- MD5の値が変わるから、ちゃんと新しいのがロードされる
- キャッシュが残っちゃってーってよくある話ですもんね。
- プロジェクト右クリックでGWTコンパイル
- 難読化のオプションをはずすと、生成されるJSが見やすくなる
- iframeのソースを使ってロードされる
- WindowオブジェクトとかDocとかはフレームに対する親がどうのこうのとか・・・
- あんまよく分からなかったですw
- nocache.js
- なんかポーリングしててOKになったらイニットとか
- ここもあんまよく分からなかったですw
- サーバーサイドとの連携
- build.xml
- gen-gwt-service
- Asyncなんちゃら
- Ajaxそのものは同期でも非同期でもOKだけど、
- GWTはRPCでやりくりするから非同期オンリー
private EchoServiceAsync echoService =
GWT.create(EchoService.class)
- createの中で自動的にプロキシのスクリプトが自動生成されて。
- なんちゃらバインディング(良く分からず・・・)
- コンパイルすると6種類のJSを生成(ブラウザごと)
- nochache.jsでアクセス元がどのブラウザか判別して、
- 最適化された MD5でハッシュ化された文字列.html が呼ばれる
- Windowクラス
- 普段は、JSNI直じゃなくて使いやすくしているこれを使う
- JDOとGWT
- そのままだとクライアントに返す時に問題がある
- デタッチコピーってのがあるらしい。
- gem-model
- GWTモードはsharedってとこに。サードパーティーのプロダクトとか使っちゃNG
- module.xmlで
<src path="client">
<src path="shared">
↑これで読みにいってくれる
—
SQL脳からBigtable脳へ
- BigTable
- できる事
- Get,Put,Delete,Prefix scan,Range scan
- ソートされてるから、このキーからこのキーはここですよー的なイメージ
- PrefixとRangeはインデックス用
- Transactionは1行を制御するのみ
- その行の最後のタイムスタンプをみて~
- できる事
- GFSにストアされるけれども
- 基本的にはキャッシュがメモリ上に
- どこになにがされたのよってのはログ(ジャーナル)に書いておく
- Bigtable上は最新のレコードだけじゃなくて履歴的にもってる
- BigTableに格納する言語によらないもの
- プロトコルバッファー
- DataStoreサービス
- BigTableよりも、もう少し高水準なAPI
- Table
- 行のキー、Valueはバイナリ
- 以下のようにソートされてる
Parent:aaa
Parent:aaa/Child:bbb
Parent:aaa/Child:bbb/Grandchild:ccc
Parent:xxx
Parent:xxx/Child:yyy
- Index
- キー以外にアクセスするときはここにアクセスしてから
- Kind(テーブル名)でのスキャン
select * from GrandChild
Child
Child
GrandChild これ
GrandChild これ
Parent
Parent
- 言ってみればテーブルフルスキャン
- Single property index
- あるKindのあるプロパティはこんな値
Select * from Parent nam = 10 and age =20
Kind Property Value
Parent age 20これ
Parent age 10
Parent nam 20
Parent age 10
Parent nam 10これ
Parent age 10
- AND条件ならパラレルで動いて、後からマージされる
- イコール条件じゃないとSinglePropertyは使えない
- Composit inex
- プロパティが複数個以上
- XMLで、このプロパティがXX以上、このプロパティはxx以下とかを指定
- デプロイしたタイミングで(?)INDEXを作ってくれる(結構重い)
- DataStoreの制約
- イコールじゃないフィルタは1個のプロパティだけ
- 使えるのは<,<=, ==, >=, > だけ
- INとかORは使えない。
- 数字でなんとか以上とかなんとか以下を使うのは厳しい
- ジョインはできない
- 集合関数とかは用意されていない
- じゃあどうするの?
- 今までRDBMSにやらせてたことを、アプリで書くだけだ。
- 複数以上とか以下とかでてきたら?
- 1つだけ使ってクエリ投げて
- メモリ上でもう一つのプロパティはフィルタリングする
- この辺はDaoで隠蔽しちゃって、
- 呼び出し側からは気づかれないようにしちゃえ。。
- ORを使いたくなったら?
- クエリを2回投げてマージ。(addAllってメソッドで)
- イコールのフィルタとorder byがあるときは?
- フィルタで絞ってから、ソートは自分で(sortメソッド)
- ジョイン
- クエリを2回に分けて、最初に駆動表。返ってきたキーを元にして~
- nested loop的な処理に自前で。
- とにかく1回1回なげて、アプリ側でなんとかしろっちゅうことですね。。
- イコールじゃないフィルタは1個のプロパティだけ
- DataStoreは1000件しか扱えない
- キーだけを取るやつ(?)は1000件以上でもいいらしい。
—
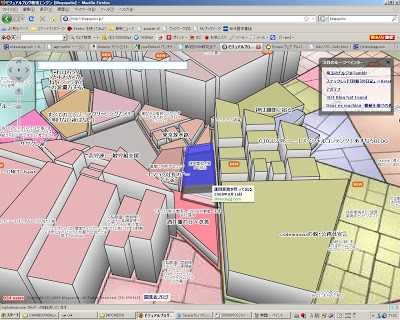
Blogopolisの裏側
- Google検索があらゆる分野でイケてるのか?
- 特定分野に的を定めて新たな価値創造
- blog
- RSS購読者
- ブックマーク
- タグ
- 上記をを組み合わせて最適なものを
- TopHatenerで得たものを元にして
- Blogopolis
- ソーシャルデータを活用したブログ検索システム
- 3次元の中に都市があるイメージ
- ビルの面積がブクマの数
- ズームアウトすると人気のヤツがチェックできて、
- ズームインすると細かい分野の細かいとこまでチェックできる
- ななめにすれば高さで購読者数がチェックできる。GIGAZINEとか。
- 屋根に画像をアップしたりして遊べたりもする。
- 運用状況
- 4つのCPUを3台の仮想マシン
- Webサーバ(Apache)1台,APサーバ(Tomcat)2台,DB(MySQL)1台,集計(Solr)1台
- ActionScriptがすごい行数になっている
- ブログ数23万
- 記事数30万
- DBダンプ9GB
- クローラ
- TopHatenerと同じなので省略
- クラスタ
- ブクマ数と同時にタグも。
- タグは人手でつけてるので下手なやつより精度高かったりする
- 階層型と非階層型
- 非階層
- K-means法。あらかじめクラスタの個数きめて分類
- トーナメント的な図に
- ボロノイ図。キリンのシマとか亀の甲羅とか。
- どのボロノイ図の辺は母点の垂直2等分線
- Additivel Weighted Power Voronoi Diagram
- Centroidal Voronoi Tessellation
- 収束するまで反復処理を繰り返していく
- Voronoi図によるツリーマップ→計算量が多くないのが利点
- 階層
- ツリーをつくる
- ブロゴポリスの配置はツリーで
- 小さなクラスタが集まって大きなクラスタを形成
- 計算量が多いから全部これはできない。非階層で絞ってから、階層で。
- 3D
- AS3でかかれたFlash用3Dエンジン
- QuadTreeレンダラ
- ポリゴンの前後関係を正確に描写
- 人間味を残したい
- トゥーンレンダリング
- キャッシュ
- JCache。60パーセント。TopHatenerは90パーセントのヒット率。
- Java Temporary Caching APIなんてのがあるんですね。。
- フレームワーク
- S2Flex2
- 名前が悪い。Flex3以降でも動作する。AMF3を独自実装。BlazeDSより手軽。
- ByteArray(Flex)
- 直接バイトにつっこんでしまう。さらにzlibで圧縮
- Cubby(画像の送り出しに)
- URLもキレイ。使いやすい。軽量。
- S2JDBC
- 重いところはバークレーDB。
- 1回限りのSQLを気軽に使える。その反面、散在してしまいがち。
- Apache Solr
- Javaの全文検索サーバ。Luceneベース。
- HTTPのAPIで言語問わず利用可能。
- 1.3からマルチコア
- CJKAnalyzer(bi-gram)を利用
- 元データはMySQLに保存。Solrにはインデックスだけ
- タイトルが60メガ、本文が1.5ギガ
- 非常に使うの簡単
- S2Flex2
- 今後
- 検索よりも探索に近い→検索にもっと力を入れていく。
- 時系列で。ビルができて衰退していく様子とかw
—
LT
- モテル 小原さん
- Seasarはプロダクト同士が食い合ってる。
- 例えばSOAP
- S2Flexは他のに比べてあんま知られてなかったり。
- ブルーオーシャン
- バッチじゃね?分散とか、リトライとか。
- Seasarでバッチやってみませんか?
- ジョジョネタとTDD yamashiroさん
- ジョジョ読んでなかったのであまりついていけず。。orz
- 1時間でNetBeansでAndroidでHello World happy ryoさん
- androidのエミュレーターにCPU100パーセントもってかれるから
- マルチコアじゃないと開発はキツイらしい
- GAE/J入門書 栗原さん
- 本の宣伝
- Javaの入門書 木村さん
- 本の宣伝
- 自分も持ってますが、この本いいですよね。
じゃんけん大会
- GAE/J本とセンスが欲しかったけど何ももらえず。。
- 3冊のGAE/J本に対して、N岡さんが最後の4人まで残りつつ 負けてしまった件w
—
Blogopolisに自分のブログもあって嬉しかったです↓
—
セッションの様子

—
ちょいスタディ
http://www.choistudy.jp
↑を開発されている方を紹介していただきました。
無料でIT系の勉強ができてしまいます。
秋は情報セキュリティスペシャリスト受けるので(3回目くらいですがw)
勉強するのに使わせていただきます!会社の新人にもやらせてみようかなと。


コメント
Just a smiling visitor here to share the love (:, btw outstanding layout.