
初版からSolrエンジニアのバイブルとして活用され続けているSolr本の第3版が出ました!
このクオリティの情報が日本語で手に入るというのは本当に素晴らしいことだと思いますし、私も読み進めながら、こんな設定あったんだ的な連続でした。
日頃から業務で検索エンジンに触れているエンジニアや、今はRDBMSのlikeクエリで頑張っているけどそろそろ限界なのでこれから検索エンジンを導入しようと思っている、といった方などに是非オススメさせていただきたい一冊となっています 🙂
![[改訂第3版]Apache Solr入門 ―オープンソース全文検索エンジン](https://images-fe.ssl-images-amazon.com/images/I/51uS%2BFQXIXL._SL160_.jpg)
売り上げランキング: 7,856
はじめに
打田さん(↓の写真の右前から2番目の方。その奥の大須賀さんも左手前の平賀さんも本書の著者。この写真は2014年のLucene/Solr Revolutionの時のもの)による”はじめに”によると、前の版のApache Solr入門から既に3年も経っていると言うことで、時の流れの早さを感じます。
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
私が業務でSolrに触れてはじめたのは2010年くらいで、その頃は本当に初版のSolr本くらいしか日本語の情報はなくて色々苦労しましたが、2014年にSolrベースで構築されたAmazon CloudSearchの多言語対応や東京リージョンローンチに業務で携わった関係で、改訂版にも大変お世話になりました。
実は日頃Lucene/Solrのバージョン6にはあまり触れる機会が多くないのですが、この本を通してガッツリとキャッチアップすることが出来て感謝です。それでは、さっそく中身に入っていきます。
Chapter 1 – イントロ
Solrとは?というところから、今までの変遷など、丁寧に解説されています。また、転置インデックスとは何か?Grepとはどう違うのか?重み付けやスコアリングはザックリどうなっているのか?といった基本的な部分が解説されていて、今まで検索エンジンにあまり馴染みの無かったような人にもオススメな内容になっています。
そしてSolrはJVMで動作するアプリケーションなので、JavaのインストールからSolrを起動して管理画面を通して操作を行ったり、全体的なアーキテクチャがどうなっているか?といったところが解説されています。
そして、私のような旧世代な人間には”managed-schema”って?と、ソワソワしてみたり。
Chapter 2 – スキーマ定義
schema.xmlは今までのお馴染みなアレですが、managed-schemaはAPIによって操作されるものです、と。
で、schema.xmlを変更したらSolrを再起動する必要がありますが(業務でもよくTomcat再起動してたな…)、managed-schemaであればSolrを再起動しなくても即座反映という。便利な世の中になったものです。schema.xmlとmanaged-schemaは混在させることは出来ず、どちらか片方だけ。
StrField(アナライズしない)とTextField(アナライズする)というフィールドタイプの説明や、日本語の形態素解析およびタームとトークンってなんだ?的なところも図入りで非常に分かりやすく解説されています。フレーズ検索ってそもそもなんだろうとかスロップの設定とか、その昔英語のドキュメントを読んでた時はフワフワした理解だったような気がしますが、とても分かりやすいです。また、フィールドのオプション(例えば元データの情報を保存するか?とか)についても例が挙げられている分かりやすい解説だったり、Schema APIでユニークキーが変更出来ないとか、詳細まで抑えてる人が執筆してる感満載。
アナライズに関しては実際の書籍データを用いたトークナイズや正規化の例が記載されていたり、TrieDataFieldなら範囲検索出来るとか、実践的な内容です。
Chapter 3 – インデックス作成
検索エンジンも他のミドルウェア等と同様に、習うより慣れろ的なところもあるような気がして、そういう観点だと、この章にしたがってやってみると理解がより促進されると思います。
また、検索エンジンを叩くアプリケーションを作っているエンジニアからすると部分更新(パーシャルアップデート)とかってサポートされてるとありがたかったりするのですが、Solrは結局delete-insert的な振る舞いをするのでSolrが元ネタを持ってる場合(stored=trueやdocValues=true)の場合だけよ、といった解説は腹落ちするな、と。そしてmultiValuedがtrueの場合にフィールドに値を追加するとか、multiValueフィールドから削除する場合、完全一致だけよ、とか。
SolrはRDBMSではないので、トランザクションの概念が異なるので、そういった注意ポイントも把握することができます。
Chapter 4 – ドキュメントの検索
いよいよ検索に関する章ですが、これも実際にこの章の記載に沿って進めていくと分かりやすいと思います。
業務ではQTime(Solrのサーバー側で処理にかかった時間)とかよく見ることになると思いますし、fq(フィルタクエリ)を使った方がSolrのキャッシュが使えて早いとか、内容も実践的です。そもそもファセットとは?的な詳細な説明も。
Chapter 5 – インデクシング
I/Oの回数を減らして如何に効率よくデータをSolrに登録するか?とか、インデクシング時にデータを加工するか?とか、私は実際に使った事ないのですがScriptUpdateProcessorに関する説明など(JVMでサポートされているスクリプト言語が動く…)。
5.2.4では、主なUpdateRequestProcessorというパートでは両端をトリミングをしたりHTMLタグを取り除いたりなんていうコンポーネントも紹介されています。
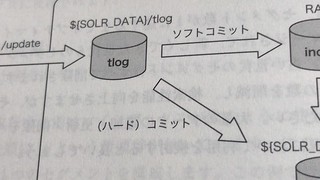
そしてDataImportHandlerに関しては、どこからがSolr4なのかすら分からない状態だったのですが、例えばdelta-importなど、statusの取得など業務でも使いそうな設定が分かりやすく一覧化されています。また、ハードコミットとソフトコミットについても、業務で使うなら抑えておきたいポイントだと思います。ExtractingRequestHandlerのとこはApache Tikaに馴染みがなくてあまり実感が湧かなかったりしましたが、その後の5.6のsolrconfig.xmlの設定は必読。インデックス性能を取るか検索性能を取るかといったところは本当に業務要件等によって変わってくるので、エンジニアの腕の見せどころ感ありますね。また、オプティマイズ時にファイルが実際にどうなるのか?ってlsの結果で見せてくれると大変分かりやすいです。
そして、5.7のトランザクションログの吐き出しと、そのログからのリカバリっていうのもプロダクションで動くサービスの運用やっている人は抑えておきたいところ。
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
Chapter 6 – 高度な検索
クエリパーサーの振る舞いの違いや、Dismaxってそもそも何がどうMaxなの?とか、ファセットは知ってるけどピボットファセットって何?とか、サーチコンポーネントってどんなのあるの?とか、サジェストってどうやって設定するとイイの?とか、緯度経度を使った検索までガッツリ網羅されていて、ここをシッカリ抑えておけるととても良いと思いますし、ファンクションに関してもmixとかmaxだけでなく比較演算子やべき乗の計算なんかが行えると検索エンジニアとしてカッコイイですね 😛
また、高速にレスポンスを返すという観点でキャッシュの戦略に関しても非常に詳細に記述されています。
Chapter 7 – スキーマ設計
どうしても慣れ親しんだschema.xmlの方に目が行ってしまう物悲しさw
スキーマレスモードはとにかく今すぐチャチャっとやってみたい、みたいな時に便利でしょうし、ソートした時に値なかったら先頭にするか最後にするかとかって実は業務的な観点でよく出てきそうなネタだったり、とても実践的な章です。
マッピングファイルを作って文字を置き換えたり、ICUで正規化したり、その中でもNFKC_CFで〜とか、シノニムとは何かとか、といった部分は必読。
Chapter 8 – クラスタ
SPOFは極力割けるべきで、且つ、より可用性の高い構成に、という観点で分散戦略について記述されている章。分散検索した時にshards.infoを指定するとマージされる前の件数とか取れてイイよ、とか耳寄りな情報満載。
私も以前はマスター・スレーブな感じの構成でやりくりしていましたが、今ではそれはレガシーなものとなってしまっています。では今はどうするのが一般的か?というところでZooKeeperを活用したSolrCloud。構築して稼働させて、落としてフェールオーバーさせて、それを管理画面上でトレースして、とか、ノードを追加して、といった一連の流れを実際に手を動かしながら体験することが出来ます。
Chapter 9 – 検索精度の向上
再現率と適合率については検索エンジニアなら必ずおさえておきたいところですが、例えばC++の”+”が記号なのでトークナイズする時に落ちてしまって適合率が下がる、なんていうのは本当によくある話ですし、シノニム展開をクエリ側でするかインデクシング側でするかとか、といったトレードオフ(それぞれでメリット・デメリットがある)や、なんといってもIFIDF→BM25に関しては今まで読んだどの文献より分かりやすかったです。ランキングに関しても非常になりました。そしてF値の説明からのDCGやNDCGら辺はありがとうございます、ご馳走様でした的な感想でございますmm
機械学習やレコメンドエンジンに関する記述があるのもこの章で、ストーリー仕立てになっているので分かりやすく、単なる検索エンジンとしてだけではないSolrのいち面を垣間見ることができます。
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
Chapter 10 – TIPS
JVMで動くアプリケーションはSolrに限らず色々あるわけですが、この章では注意どころや設定どころが解説されています。
また、分散検索用のDistributed IDFとか知らなかったので、大変勉強になりました。FAQ集はここだけ切り取ってもお金払えるくらい、ローンチ後に問い合わせもらうと鼻毛が飛び出そうになるようなことが書かれていて、今後救われる人も多いのではないでしょうか。
Chapter 11 – SolrJ
SolrのクライアントライブラリであるSolrJを使って実際にアレコレやってみようぜ、な章。LBHttpSolrClientといって負荷分散してくれるクラスとかあるのですね。また大量のドキュメントを効率良く、という観点でConcurrentUpdateSolrClientとか。solr-test-frameworkというテスト用のライブラリがあるのも知りませんでした。
Appendix
Git、Pythonでの機械学習、ネストされたドキュメントを効率的に検索する機能が紹介されています。
そして、以前、私が開催した検索エンジンに関する勉強会で登壇してくれた大須賀さんが、
・外国人参政権→『外国』『人参』『政権』にトークナイズされてしまう
・営業部長津田→『営業部長の津田さん?』『営業部の長津田さん?』
といった問題提起をしてくださいましたが、単語と単語の組み合わせ、および、単語の出現しやすさやを数値化してそれを元にコスト計算をして、上記のような問題を解決しようというトークナイズのオプションの”N-best”に関する記載もされています。このN-bestはYahoo!JapanによるコントリビュートとしてSolr6に追加されています。
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
—
ほどよいボリュームで大満足な一冊でした。理論と実践のバランスも良く、とにかくコレ読んでおけば大丈夫!と言える良書だと思いますので、是非手にとっていただければと思います 🙂
献本御礼!!
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js


コメント