
Lucene/Solr Revolution 2016の1日目。
■ Breakfast
こういうアメリカ的な食生活は好きなのでなんら問題なく。
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
テーブルでたまたま一緒になった人と色んな話ができてナイスな感じ。隣のテーブルみてみ?って言われて見てみたら、”logs don’t lie”ってTシャツ着てる人たちがいた。こういう時はTシャツとか服装でレペゼンするのも大事だな、と。ちなみにその左にいる長髪の人のパーカーは2014年のre:Inventのモノで、後にブースでちょっと話しかけてみましたが、AWSのことも詳しくて話が弾みました 🙂
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
■ Keynote
会場の様子。ボストンのシェラトンはイロイロ古い感があるのですが、こういうボールルームとかはさすがに豪華です。
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
Solr in Action著者のTrey GraingerさんからLucene/Solr界隈諸々に関するご案内。
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
Lucene/Solr Revolutionはグローバルなカンファレンスですね、と。(3月に参加したElastic{ON}と比べると小規模ですが…)
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
Stump the Chumpという、Solrのコミッターがオーディエンスからのマニアックな質問にとてもカジュアルな感じに答えますっていう、このカンファレンスの目玉(?)セッションがあるのですが、今回もやりますよ、と。笑
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
Solrはバージョンを重ねるにつれてどんどんモダンになっていっています。(が、色んな人と話したけど、なかなかそんなにエッヂなところを本番で使ってる人って多くない印象ではありますが…)
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
とにかくスケール!っていう印象でした。
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
Solrの今後、ということで、この辺ワクワクするのですが、例えばZookeeperを意識しなくてもイイように〜的な話とかあるけど、結局そのjarのバージョンとかに依存しちゃったりするのとか、どう扱うのかな、、とか。SolrCloudじゃなくて、一本化された”Solr”的なところも、チョロっとローカルのドキュメントを食わせて検索したいーみたいな時にバイナリ落としてきたらデッカイのなってたらやだな、、とか。。。
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
trillionsなドキュメントを食わすためのリニアなスケールを実現して”make solr stable platform”したい、と。
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
そしてLucidworks CEOのWill Hayesさん。
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
ガンガンぶっこんできます。”search is the killer app” だったけど、今や “search is the app killer” だぜ!と。SQL capabilityはAccessを容易にするため〜とか、その辺の言及もあったのですが、Fusion 3.0のBetaの発表とか、反響はそんなに大きくなかったかなと。。
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
検索屋さん的にはyeah, you said it!って感じ。
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
そして、今回の目玉ニュースであろうIBM Watsonとの提携発表とともに、Watson CTOのSridhar Sudarsanさんへマイクをバトンタッチ。
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
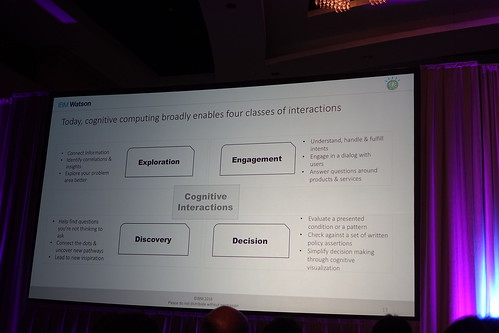
夢が広がるプレゼンテーション。もの凄い量のデータがgenerateされてるけど、構造化されてるわけじゃないし、統一されたフォーマットとかでもない
patterns need to be discovered的な。
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
機械学習技術とかの台頭で、今後、コグニティブなんちゃら〜っていうのはWatsonだけに関わらず、いろんなところで出てきそうですね。
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
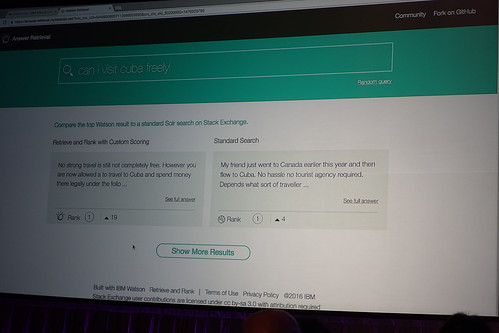
普通の検索と比較するとーっていうデモとか、
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
画面の中のロボットがテイラースウィフト歌ったり、ガンナムスタイル踊ったりしてました。
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
■ Smart Facets at Rakuten
Bostonの楽天オフィスで働くMikeさんとKeithさん。
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
Rakutenはグローバルだよという話。最近だとBitCoinに関する投資(Bitnet)とかも。
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
Facetsは遅いし、OOMも起こるし、扱うの大変。独自ロジックを組んでCustom Collectorを作るのも、Solrのバージョン上がった時に喰らう可能性もあったりする、と。なのでSolrの外側にAPIのラッパーを作ったよという話。APIのラッパーの中身の詳細に関する言及がなくて少し残念でしたが、クリックストリームなデータなどを活用しつつ、とのこと。ビジネス側からの急な変更要求にも対応しやすいしね、と。
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
お約束の。オフィスはSouth Station(ボストン茶会事件の場所とか近い)から直ぐのビル。
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
■ It’s Just Search
Lucidworks co-founderでLucene in Actionの著者のErik Hatcherさん。
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
SolrはSuggesterを提供していて、その中でグルーピングが〜とかっていう流れから、サジェストといっても、今日では”suggest things not strings”。つまりn-gramでただヒットしたものを出すようなものではなく。Signals and Recommendations。この辺の話は未だに英語だとついていくのが難しい…
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
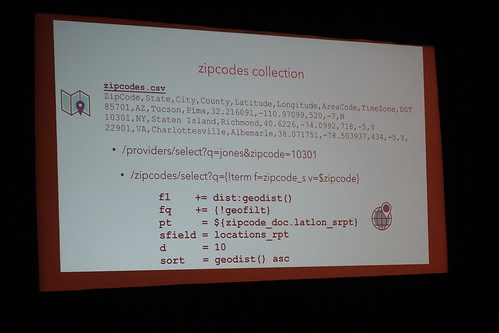
zipcodeでの検索〜とか。
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
それにしてもFusionの機能的な話が当たり前のようにたくさん出てきて、自分がこの界隈のエッヂな機能について全然ついていけてないんだなと。。
■ PlayStation and Lucene: Indexing 1 Million documents per second on 18 servers
今回のカンファレンスで一番楽しみにしてたセッションの1つ。実際内容もとても良かった。SONYのPlayStationの話。
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
San FranciscoのSony Interactive Entertainmentで働くベイエリア歴の長いAlexanderさん。夜のパーティーでイロイロ話したけど、出身はベラルーシだけど、Googleで働いたこととか、Startupにいたこともあるし、経験豊富な人。1つの会社で5年とか働いてる人見ると向上心ないって思われちゃうかもね的な…。
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
4千万デバイス、6千5百万アクティブユーザー、そしてPlayStation Networkだけでなく、StoreやVideoなども。
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
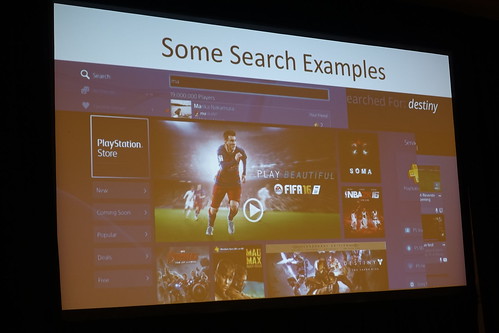
ユースケースはとても分かりやすいところ。
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
チャレンジとしては、高可用性はもちろんのこと、素早くスケールできなければいけない。
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
レガシーなシステムはRDBMSでこの部分を扱ってて、スケールしないし、DBAに頼んでホゲホゲとか辛いし。最初はCassandraでこれを解決しようと思ったけど、Joinしなくてイイように一個の大きいJSONにガッツリ詰め込んだら水平にスケールするんだけど、フレキシブルなクエリは当然叩けません、と。
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
では、Solrではどうだったか?結論としてはあまりフィットしなかった⇒なので、Luceneでいくことにした。
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
ココはガッツリ参考になるとこだったかな、と。マイクロサービスとは言え、オンラインな同じユーザーからのアクセスは同じノードにいくようにスティッキーセッション的な。検索以外のところのデータを持ってるCassandraと検索エンジンの差分については、両方にバージョン番号のフィールドを持って、検索クエリ投げる前にCassandraにアクセスしてバージョンが違ったら〜的なアプローチ。ついでにEhcacheを使ってJVMのヒープからデータを極力逃してGCが発生しないように、とか。(大規模に運用してるとJava辛い的な問題の彼らなりの解決策)
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
中身はこんな感じになってるよー、と
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
Luceneの更新について。
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
その結果、秒間数十万ドキュメントをインデクシングできるようになりました、と。(スゲー)
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
ココらへんからガッツリとメモリに乗っけて高速化しちゃおうぜっていう話。
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
SSD+メモリで。
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
SSDをインスタントストアとして持ってるr3.8xlargeのEC2インスタンスをこんな感じで使ってます、と。
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
もちろんユースケースによるけれども、Luceneまじでちょっぱやだぜ〜
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
いやはや、スゲーあつい話でした。彼ら(ベイエリアで働いてるSonyの他のエンジニアもきてた)とは夜のパーティーも、その後のDiceの人たちが連れてってくれたバーでもいろんな話をさせていただきました。re:Inventでも登壇するよ!っていうことだったので、それも楽しみですね。
■ Lunch
今回ご飯は毎回美味しかったです。クラムチャウダーとか。
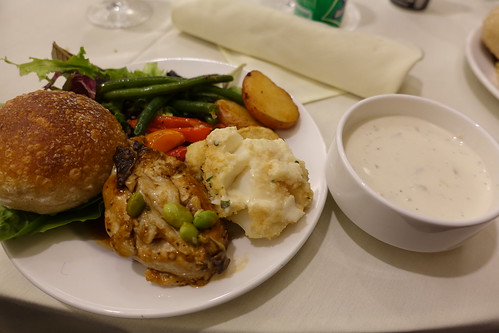 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
お昼一緒に食べた人たちは、可視化はElasticsearch+Kibanaでやってるけど、検索はSolr(バージョン4系)だねーっていう人が多かったです。CloudSearchはもっともっとmake noiseしないとな、、と。改めて。2年前みたいにブースとか出せるとイイな〜
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
■ SearchHub or How to Spend Your Summer Keeping it Real
Lucidworks CTOのGrant Ingersollさんのセッション。CTOとして普段やってることは、Client Facing/Public Speaking/Code Writingですよ〜なんていう話があった後に、
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
https://lucene.apache.org/ の↓のLucidのところを今回紹介するSearchHubにしようかな、なんていう。
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
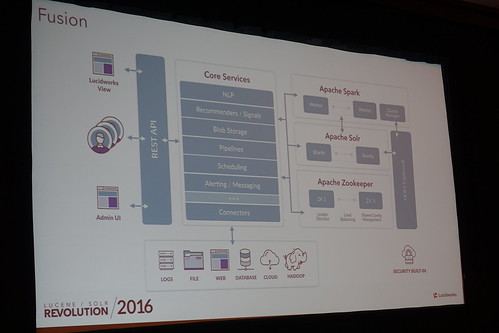
SearchHubは色んなところからデータを集めてきて、Lucidworks Fusionにそれを食わせるもの。
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
そしてFusionの中身はSolrとSparkの組み合わせだぜ、と。(Fusion全然チェックできてなかったので、Sparkさんあなたイキナリこんなところにも、、っていう感じ)
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
なんというか、単純に検索がWebなAPIで叩けるだけーっていうので解決できることって減ってて、ユーザーの要望に答えていこうとすると、こういう形になるんだろうなっていう腹落ち感な構成図。
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
SearchHubはEC2(m4.2xlarge)上にDocker立ててやりくりしてるそうです。
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
K-meansとかWord2Vecとか、このセッションだけじゃなくて、色んなところで目にしたり、耳にしたり。
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
このセッションで何よりよかったのは、ソースコードを見せてくれて、実際にどういう実装してるのか?っていうのを紹介してくれたこと。いやー、ソースコードってほんと分かりやすくて好きです。
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
にしても、Solr6になってJDBC接続できるようになったから、Solrに対する検索で引っかかってきたのとSpark SQLで取得したデータをJoinして〜なんていう、知らぬ間にそういうところ狙ってたんですねーっていう。詳しくは金曜日のセッションで。
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
■ Near Real Time Indexing in Search
インドのインターネットショッピングサービスのFlipkartのお話。ThejusさんとUmeshさん。
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
160K request per secとかハンパないですね、、
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
Sellerの数も凄い。
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
在庫の情報とか直ぐに反映させないと、、っていう。課題が分かりやすい。
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
いわゆる一般的な感じのECなヤツ。
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
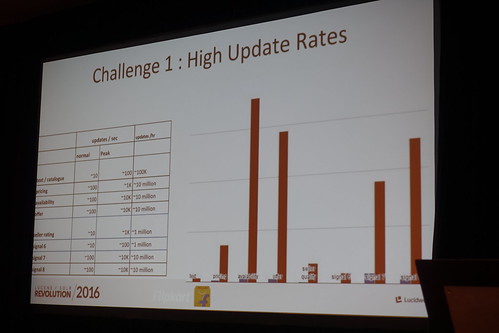
いかに拘束に更新についていくか。
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
だいたいこんな風にワンストップな感じにするけど、、
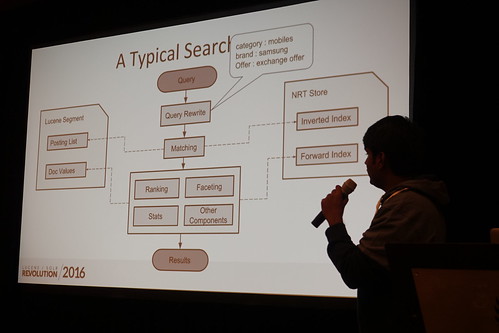 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
Near Real Timeに更新しなきゃいけないヤツと、そうでないヤツを分割してーっていうアプローチ。
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
SolrはRedisとかKafkaとかと組み合わせてモダンな構成に。
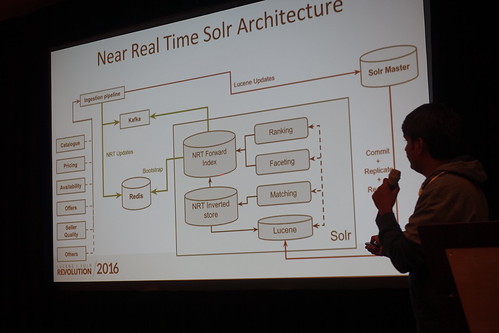 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
■ Autocomplete Multi-Language Search Using Ngram and EDismax Phrase Queries
NetflixのIvanさんの多言語は苦労が多いよね的な話。
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
CJKな話。
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
韓国語の構成的な話から、
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
日本語の形態素解析の話や、
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
ICUでノーマライズとか。
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
イロイロ設定変えてやりくりするのに、今までイケてたのにーみたいなレグレッションに対して、Google SpreadSheetを使って前後の振る舞いの違いをちゃんと見れるようにするっていう、なんとも正攻法なアプローチ。ネットフリックスといえどこうやってコツコツやってるのよね、と。ただ彼らの凄いところは、こういうのを https://github.com/netflix/q っていう形でQuery Testing Frameworkって名前付けてインターネット上に公開してるところなのかな、とか。
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
ちなみにSolrのバージョンは4.6だし、特に日本語のところは、日本の検索エンジニアにとって真新しいことはなかったはず。全言語のデータは同じコレクションの中に入っていて、それぞれの言語ごとにフィールドを分けている、とのことでした。
■ Stump the Chump
例年通りとてもカジュアルで楽しい雰囲気。ベテランのChris Hostetterさんがサンダルで壇上からバンバン斬っていきます。
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
Solrが返すqtimeと、SolrJが返すelapsetimeが全然違うときがある〜とかっていう基本的な質問から、やけにレイヤ低そうな回答が飛び出てきたり、スペルチェッカーとサジェスターってのはそれぞれxxでーみたいなのとか、なんか今年は普通に勉強になったような気がする。
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
とは言え、全然ついていけないところとか、なんで皆んながゲラゲラ笑ってるのか分からなかったりとか、まだまだ精進する必要があるな、と。
■ Conference Party
ホテルの隣にあるPrudential Centerの51階にあるSkywalk Observatoryという360度ドカーンとBostonの景色が楽しめるスペースを貸し切りパーティー。
#LuceneSolrRev party 🙂 (@ Skywalk Observatory (Prudential Center) – @bostonskywalk) https://t.co/cChMQGKxwY pic.twitter.com/mAjwoODuGN
— Eiji Shinohara (@shinodogg) October 13, 2016
//platform.twitter.com/widgets.js
バーテンダーさんがちゃんといて。
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
カンファレンスオリジナルカクテル。
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
食べ物も美味しかったし。
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
何より色んな人たちといろんな話できてよかったです。ソニーの人たち。
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
楽天の人たちと 🙂
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
AWSの検索エンジニアのTomas(アルゼンチンのブエノスアイレス出身)。彼は二年前のこのイベントでCloudSearchのお披露目してました。
//platform.instagram.com/en_US/embeds.js
そのまま会場を完全撤収するまで楽しんでたら、Dice.comの人たちに声かけてもらって二次会へ。ここでもまた色んな話が聞けて大変興味深かったです。やっぱり未だITエンジニアは完全な売り手市場。。
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js

技術評論社
売り上げランキング: 737,924


コメント