
Best and Brightestな感じのスゲー技術者が集まってる事で有名な
Treasure Dataですが、Fluentdとかは試したことありますが、
そう言えば本体使った事ないなと。。
ということで、さっそく試してみます。
Matzとかがインタビューに答えてるトップページから Sign Up for FREE ボタンを叩きます。

シンプルなフォームに入力してサブミットすると、
Treasure Data Support(support@treasure-data.com)からメールがきます。
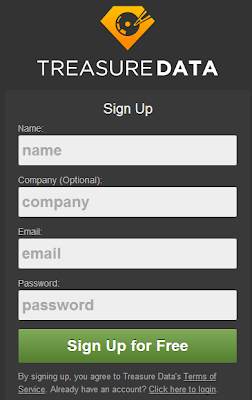
メールに埋め込まれてるリンクをボチって押すとTreasureDataをはじめるガイドページ。
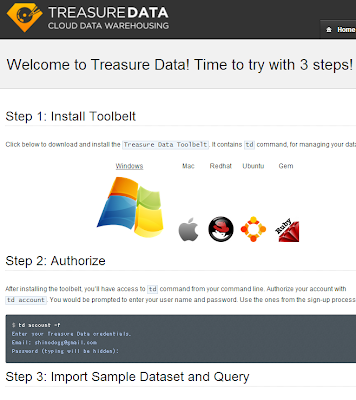
今回はWindowsのマシンで試すので、Win用の Treasure Data Toolbelt をダウンロードします。
インストーラーに従って次へ次へ的な感じですが、インストールされたモノをみてみるとなかなかシンプル。

コマンドプロンプトを立ち上げてみます。ほうほうって感じですね。
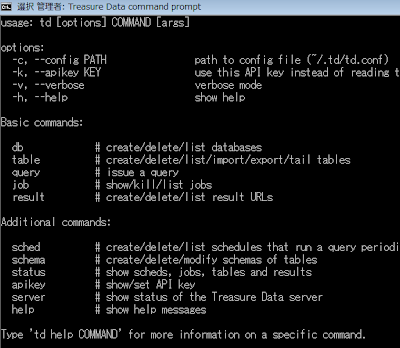
ネットワーク越しにホゲホゲやるので、事前にプロキシの設定いれておきます。
Windowsのコマンドプロンプトだと↓こんな感じ。
C:Usershoge>set http_proxy=hogehoge.proxy.co.jp:9999
Step 2: Authorizeに沿ってアカウントの設定をします。
C:Usershoge>td account -f
Enter your Treasure Data credentials.
Email: hogehogehoge@hogehoge.com
Password (typing will be hidden): **************
Authenticated successfully.
Use ‘td db:create <db_name>’ to create a database.
Step 3: Import Sample Dataset and Queryもやってみます。
データベースをcreateします。rakeコマンド叩くような感じですね。
C:Usershoge>td db:create testdb
Database ‘testdb’ is created.
Use ‘td table:create testdb <table_name>’ to create a table.
続いてテーブル作ります。
C:Usershoge>td table:create testdb www_access
Table ‘testdb.www_access’ is created.
5000レコードのサンプルデータがあるらしく、
C:Usershoge>td sample:apache apache.json
Create apache.json with 5000 records whose time is
from 2012-11-16 00:54:44 +0900 to 2012-11-16 18:47:14 +0900.
Use ‘td table:import <db> <table> –json apache.json’ to import this file.
サンプルデータをテーブルにインポートします~、と。
C:Usershoge>td table:import testdb www_access –json apache.json
importing apache.json…
uploading 117342 bytes…
imported 5000 entries from apache.json.
done.
上記で作ったtestdbデータベースのwww_accessテーブルに5000件のデータが入ってますね~、と。
C:Usershoge>td table:list
+———-+————+——+——-+——–+
| Database | Table | Type | Count | Schema |
+———-+————+——+——-+——–+
| testdb | www_access | log | 5000 | |
+———-+————+——+——-+——–+
1 row in set
クエリー叩くとHive的なあれがズダダダン、と。
ここまでモノの数分。ハンパねぇ楽チン…。
C:Usershoge>td query -w -d testdb “SELECT v[‘code’] AS code, COUNT(1) AS cnt FROM www_access GROUP BY v[‘code’]”
Job 999999 is queued.
Use ‘td job:show 999999’ to show the status.
queued…
started at 2012-11-16T09:55:33Z
Hive history file=/tmp/9999/hive_job_log__99999999.txt
Total MapReduce jobs = 1
Launching Job 1 out of 1
Number of reduce tasks not specified. Defaulting to jobconf value of: 4
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapred.reduce.tasks=<number>
Starting Job = job_20120999999_99999, Tracking URL = http://ip-999-999-999-999.hoge.hoge:50030/jobdetails.jsp?jobid=job_201209999999_99999
Kill Command = /usr/lib/hadoop/bin/hadoop job -Dmapred.job.tracker=999.999.999.999:8021 -kill job_201209262127_88771
2012-11-16 09:55:45,476 Stage-1 map = 0%, reduce = 0%
2012-11-16 09:55:49,522 Stage-1 map = 100%, reduce = 0%
2012-11-16 09:55:58,632 Stage-1 map = 100%, reduce = 25%
2012-11-16 09:56:06,708 Stage-1 map = 100%, reduce = 50%
2012-11-16 09:56:13,794 Stage-1 map = 100%, reduce = 75%
2012-11-16 09:56:21,880 Stage-1 map = 100%, reduce = 100%
finished at 2012-11-16T09:56:24Z
Ended Job = job_201209999999_999999
OK
MapReduce time taken: 44.482 seconds
Time taken: 44.619 seconds
Status : success
Result :
+——+——+
| code | cnt |
+——+——+
| 404 | 17 |
| 500 | 2 |
| 200 | 4981 |
+——+——+
3 rows in set
最後にサンプルテーブルを消してキレイにして今回のお試しを終わります~
C:Usershoge>td table:delete testdb www_access
Do you really delete ‘www_access’ in ‘testdb’? [y/N]: y
Table ‘testdb.www_access’ is deleted.
テーブルがリストに出てこなくなりました~
C:Usershoge>td table:list
0 rows in set
There are no tables.
Use ‘td table:create <db> <table>’ to create a table.



コメント
[…] ライブラリを使って 昨年試して放ったらかしてるTreasureData にデータを入れてみます。 […]