こちらはAlgoliaのHamish Ogilvyが書いた Vectors are over, hashes are the future of AI の翻訳です。
AI(人工知能)はベクトルの演算を元に構築されてきました。最近では、技術的な進歩により、AIアプリケーションによっては精度を大きく犠牲にすることなく、その他のバイナリ表現(ニューラルハッシュ等)の方がパフォーマンス(メモリやスピード)の面で劇的に優れていることが分かるようになってきました。
ニューラルハッシュのような技術を使うと、AIにおける多くの分野がベクトルからハッシュベースな構造に移行することができ、AIの進化のスピードを劇的に向上させるトリガーとなります。こちらの記事では、その背景にある考え方と、これがなぜ大きな技術のシフトに繋がるのかを、簡潔にご紹介します。
ハッシュ
ハッシュ関数とは、任意のサイズのデータを固定サイズの値にマッピングする関数のことです。ハッシュ関数が返す値はハッシュ値、ハッシュコード、ダイジェスト、もしくは、シンプルにハッシュと呼ばれます。
ハッシュについてはWikipediaの記事をご覧いただければと思いますが、そこでは以下のように図解されています。
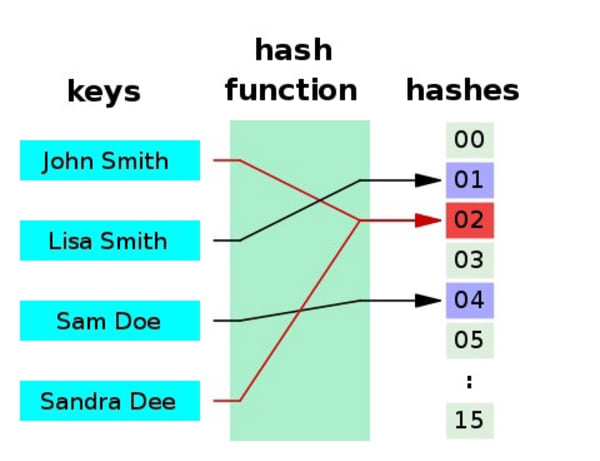
ハッシュは、正確さ(accuracy)、データのストレージサイズ、パフォーマンス、情報検索のスピードといったもののトレードオフに適していると言えます。
重要なことは、これらは確率的(probabilistic)なものであるため、複数のインプットされたアイテムが同じハッシュになってしまう可能性があります。これは、遅くて正確(slower exactness)と爆速で高い確率(exeremely fast, high probability)のトレードオフという興味深いことであると言えるでしょう。アナロジーとしては、『1秒間で世界中のどこでも好きな都市の郊外に行ける』 vs 『10時間で世界中の好きな都市の特定の家に行ける』のはどちらが良いのか?といったような話になります。10時間あれば郊外から特定の家に行くことは簡単なことがほとんどなので、多くの場合、前者の方が良いと言えるのではないでしょうか。
ベクトルについて考えると、データ表現としてまず挙げられるのはフロート(浮動小数点)になります。これはハッシュと比較すると絶対的な性質を持っていますが、それでも厳密に正確とは言い切れません。フロートについては以下に述べます。
フロート
AIを理解しようとした場合、コンピューターがインテジャー(整数)ではないベースの数をどのように表現しているか理解をする必要があります。もしよろしければWikipediaの浮動小数点の演算の記事をご覧ください。
フロートの問題点としては、スペースを取ること、計算が複雑になってしまうこと、そして、それでも尚、近似値(approximation)であるということが挙げられます。Rob Pikeがbignum calculatorについて話しているのを見ていた時が、おそらく私がそのことについて深く考えるようになった最初のきっかけであったと思います。そして、それ以来ずっと関心を持ってきました。ありがとうRob😁
このバイナリ表現は、ベクトル計算に関して、モデル予想(predictions)に関してインパクトがほぼゼロだとしても、軽微な数値の変化に対してもワイルド(激しい)ところがあります。例えば 0.65 と 0.66 を例にとると、float64 (64ビット浮動小数点)の2進数では以下のようになります。
- 11111111100100110011001100110011001100110011001100110011001101
- 11111111100101000111101011100001010001111010111000010100011111
人間の目に見やすいものではありませんが、たった1%の数値の変化に対してほぼ半分(64ビットのうちの25ビット)が異なっています!行列演算のベクトルという視点では、この2つの数値は非常によく似ているわけですが、その下にある2進数(全ての重労働が行われる場所)においては全く異なるということです。

私たちの脳みそはこのような働きをすることはありませんので、浮動小数点の2進数表現を使って数字を保存することはしません。少なくともニューロンにとっては奇妙なことのように聞こえるかもしれませんが(円周率の小数点以下の60,000桁以上を記憶できる人を除けば…)、私たちの脳は視覚的であり、脳のニューラルネットワークは、分数を扱うのに長けています。1/2や1/4と言われたら、グラスやピザなどをすぐに思い浮かべるのではないでしょうか?それは仮数(mantissa)や指数(exponent)は意識していないでしょう。
浮動小数点の演算を高速化して、スペースを節約するためによく使われる技法としては、解像度をfloat16(16ビット)や更にfloat8(8ビット)に落として、計算を高速化するというものです。しかし、この場合、明らかに失われる部分が出てきてしまいます。
それは、つまりフロートの演算は遅い/悪いってこと?
そうではありません。この問題は多くの人々がそのキャリアをかけて取り組んできたものです。チップのハードウェアとその命令セットをより効率的にして、より多くの計算を並列で処理させることで、より速く演算を行えるように設計されてきました。GPUやTPUや使われるようになった背景も、大量の浮動小数点演算をさらに高速で処理できるようになったからと言えるでしょう。
ブルートフォース(力ずくなやり方)で速度を上げることはできるでしょうが、果たしてその必要があるでしょうか?また、解像度を妥協することもできますが、これも必要なことでしょうか?フロートとて絶対的なものではないのです。ここでは、遅いということよりも、いかにしてもっと速くするかということが重要です。
ニューラルハッシュ
ビットセットにおけるXORのようなバイナリ比較は、フロートベースの演算よりも非常に高速です。では、0.65と0.66の局所性センシティブ(locality sensitive)を考慮したバイナリハッシュで表現したらどうでしょうか?そうした場合、そのモデルでの推論は高速に行えるのではないでしょうか?
Note: 1つの数値にのみ注目したのは意図的な例にはなりますが、多くの浮動小数点を含むベクトルでは、ハッシュは実際に全ての次元のリレーションを圧縮することもできるわけで、そこでマジックが起こります。
そして LSH(Locality Sensitive Hashing) という、まさにこれを実現するようなハッシュアルゴリズムのファミリーが存在することが分かりました。元のアイテムが近ければ近いほど、そのハッシュのビットは同じになるというものです。

このコンセプトは、新しい技術が新たな利点を見出したことを除けば、特に新しいものというわけではありません。歴史的には、LSHはランダムプロジェクションや量子化といった技術を使っていましたが、精度を保つために大きなハッシュスペースが必要になるという欠点があり、利点が損なわれていたという側面があります。
シングルフロートであれば些細なことですが、高い次元(多くのフロート)のベクトルの場合はどうでしょうか?
ここで、既存のLSH技術をニューラルネットワークが作成するハッシュに置き換えるのがニューラルハッシュ(もしくはlearn-to-hash)の新しいトリックです。生成されたハッシュは非常に高速なハミング距離計算を用いて比較され、その類似性を推定することができます。
こちらは一見、複雑そうに聞こえるかもしれませんが、実はそれほどでもありません。ニューラルネットワークは以下のようなハッシュ関数をオプティマイズします。
- 元のベクトルと比較してほとんどパーフェクトな情報を保持
- 元のベクトルのサイズと比較してはるかに小さいハッシュ値を生成
- 演算が大幅に高速化
これが意味することは、情報の解像度はほとんど変わらずに、非常に高速な論理演算が可能で、サイズの小さなバイナリ表現を得ることができるということです。
事例
元々のユースケースとしては、高密度な情報検索を行うための近似最近傍(ANN)でした。こちらの処理では、ベクトル表現を使って情報を検索するため、概念的に似ているものを見つけ出すことができます。そのため、ハッシュのlocality sensitivity(局所性)がとても重要になってきます。私たちはこれを更に推し進めており、複雑なデータの高速であり且つ近似的な比較のために、より広範囲にハッシュを活用しています。
高密度な情報検索(Dense information retrieval)
いくつのデータベースを思い浮かべることができるでしょうか?おそらく沢山あると思いますが、その中で検索インデックスはどうでしょうか?あまり無いのではないでしょうか。もしくは、それらはほとんど同じ古い技術に基づいているのではないでしょうか。これは歴史的に言語がルールベースな問題 – トークン, シノニム, ステミング, レンマ化 等であったことが大きな理由であると言えるでしょう。これらは非常にスマートな人々がその全てのキャリアを懸けて取り組んでいるものの、未だ解決されているとは言えません。
グーグルのファウンダーであるラリーページは、検索は私たちが生きている間には解決されない問題であると言っているのだそうです。その世代の最高の頭脳、何千億円もの投資、それらをもってしても解決されないってこと…?
検索技術は、主に言語的な問題からデータベースに遅れをとってきましたが、ここ数年で言語処理に革命が起き、今でもなおスピードアップしています!技術的な観点からは、ニューラルベースのハッシュが新しい検索技術やデータベース技術のバリアを下げるのではないかと考えています(私たちAlgoliaもその一員です!)。


コメント