
こちらはAlgoliaのChief Product OfficerのBharat Guruprakashが書いたHow neural hashing can unleash the full potential of AI retrievalの翻訳です。
検索について、シンプルであると同時に複雑に感じることがあるかと思います。Googleでの検索はシンプルで、結果はとても適切です(ここ数年Googleは多くのスポンサーされた結果をプッシュしているので、そういった点は議論の余地はあるかもしれませんが…)。また、検索ではありませんが、ChatGPTはその体験をさらに魔法のようなものにしています。しかし、検索機能を実装したことのある人なら誰しも、情報検索がとても複雑なトピックであることを知っているのではないかと思います。
検索クエリから結果を受け取るまでの一連のライフサイクルをシンプルに説明するのであれば、検索というのは、クエリ理解、結果の抽出、そして、ランキングの3つのプロセスに分けることができます。
- クエリ理解(Query understanding): 自然言語処理(NLP)技術は、検索エンジンが分析をするための準備および構造化を行います。
- 結果の抽出(Retrieval): 検索エンジンは最も適合性の高い結果を取得して、適合性の高いものから低いものへと順位付けを行います。
- ランキング(Ranking): 最後に(クリック数やコンバージョン数などに基づいて)、最も良い結果を上位に押し上げ、お客様によって設定されたルールやパーソナライゼーションなどを適用することで行われる再ランキング(re-ranking)処理があります。
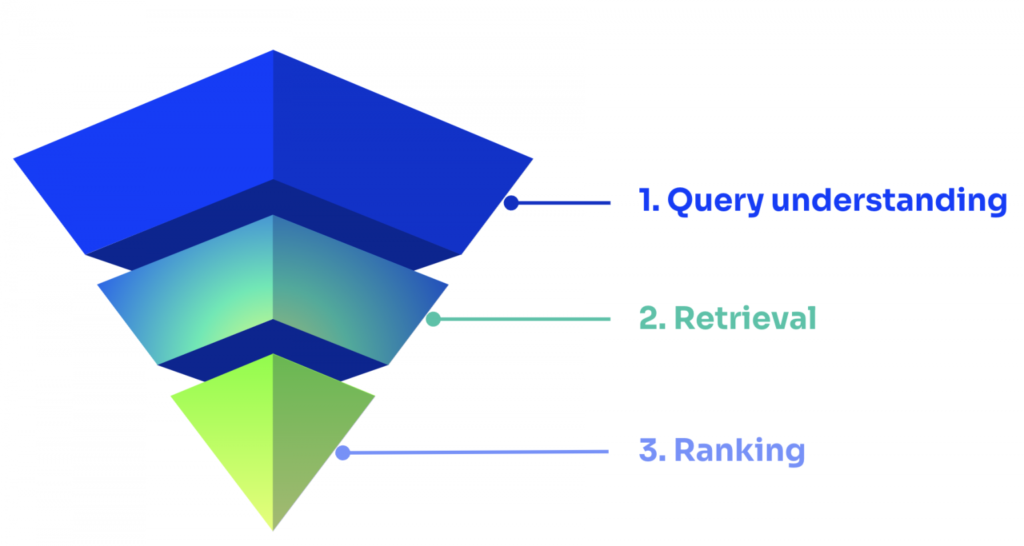
機械学習AIは以前からクエリプロセッシングとランキングには適用されていて、それぞれを大きく改善することができています。そこに欠けていたのは結果の抽出の部分で、それは全体のクオリティを向上させるのに不可欠であると言えます。
検索の品質は、精度(precision)と再現率(recall)を用いて測定することができます。精度は検索されたドキュメントのうちで適合しているものの割合、再現率は検索されたすべてのドキュメントのうち適合しているドキュメントの割合です。どちらの指標も、検索結果が優れているかどうかを判断するのに役立ちます。
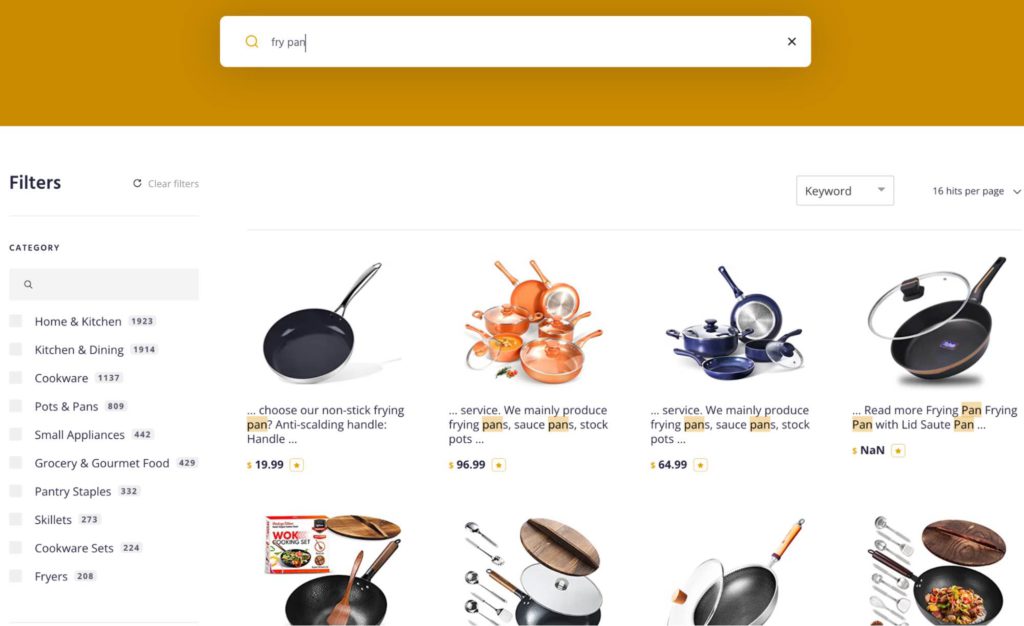
例えば、キッチン用品を買い替えようと、お気に入りのサイトで”fry pan”を検索したとします。その結果としていくつかのアイテムはとてもレレバントです。しかし、ソースパン付きの調理器具セット(下のスクリーンショット)のように、そうでないものも存在します。これは精度(precision)の例ですが、検索結果には含まれなかったものの、このサイトには他にも多くの適合する商品があったとしたら、それは再現率(recall)の例です。
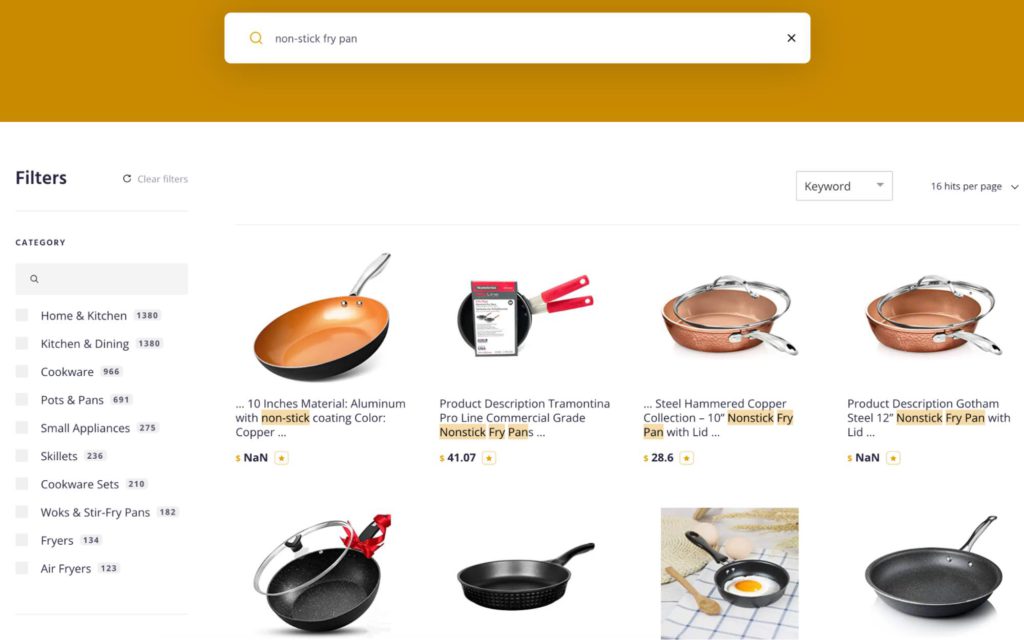
それでは、さらに検索クエリを絞り込んでいきましょう。“non-stick frying pan”(こびりつかないフライパン)と検索した場合、(1)少し異なるキーワードを導入したためクエリの結果の量が異なり、(2)期待していた結果(調理器具セットではなくフライパン)が多くなっている、といったことが見て取れるのではないでしょうか。
実際のところは、精度(precision)と再現率(recall)は陰と陽のような側面があり、精度(precision)を向上させると再現率(recall)に影響があり、再現率(recall)を向上させると精度(precision)が損なわれることがあります。つまり精度と再現率の両方を向上させることが重要であり、これこそがAI検索が為せる技と言うことができるでしょう。
検索による抽出(Retrieval)は、AI検索のパズルの最後のピースで、いくつかの理由から最も困難な作業でした。
- AI検索のスケールとパフォーマンスをやりくりするには、コストがかかり過ぎるのです。ストレージ、CPU、アルゴリズムといった全てを最適化させる必要がありました。
- AI検索モデルは”brittle”(脆く壊れやすいもの)です。検索インデックスに新しいコンテンツが追加されたり、既存のコンテンツが変更されると、モデルも更新をする必要があります。
- 正確なマッチングと広いコンセプトのマッチングにはトレードオフがあります。
こちらの記事では、このAI検索の最後のチャレンジを解決するために、私たちがどのように取り組んできたかをご紹介します。今後また別の記事で、検索ピラミッドの他の部分について、より詳しくお話しさせていただきます。
AI information retrieval (AIによる情報抽出)
検索には特定のクエリに対する適合性を判断する技術が必要です。長年、検索エンジンの世界ではキーワード検索に力が注がれていました。それが今、変わりつつあります。キーワード検索を超えるようなベクトル検索という技術が登場し、クエリのコンセプトが理解されるようになりました。
ベクトル検索は、AI検索のための機械学習技術です。言葉はベクトルによって数学的に表現されます。ベクトルは、多次元(n次元空間とも言います)にプロットされて、クラスタリングされます。ベクトル検索は、検索クエリや対象のアイテムに対する複数のオブジェクトの類似性を、ベクトル表現によって比較します。類似するものを見つけるために、オブジェクト(データやコンテンツ)をベクトルに変換するのと同じモデルを使って、クエリ(もしくはその対象)をベクトルに変換します。そして、お互いに類似したベクトルがデータベースから返され、最も近く一致しているもの見つけて、正確な結果を提供すると同時に、従来の検索技術では返されたかもしれないような無関係な結果を排除します。

HNSW(Hierarchical Navigable Small World)、IVF(Inverted File)、PQ(Product Quantization、ベクトルの次元数を減らす技術)といった技術は、ベクトル間の類似性を求める近似最近傍(ANN)手法として最もよく知られているものになります。それぞれの手法は、PQによるメモリ削減、HNSWやIVFによる高速かつ正確な探索時間など、特定の性能特性の向上に重点を置いています。特定のユースケースに対して最適なパフォーマンスを得るために、複数のコンポーネントをミックスして’composite'(複合)インデックスを作成することは一般的な手法と言えるでしょう。
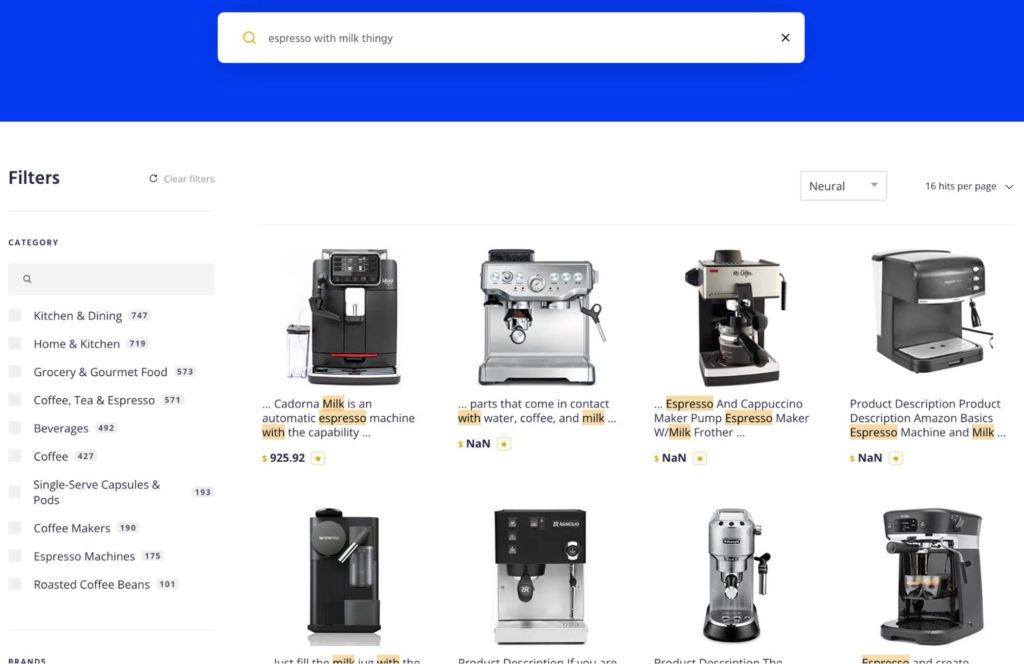
Dimension(次元)が何千も存在することもありえます。各ベクトル間の近接度と角度は、検索エンジンが用語と意味の類似性を判断するのに役立ちます。例えば”espresso with milk thingy”と入力すると、ベクトル検索エンジンはスチームワンド付きのエスプレッソメーカーを返すように類似性を探します。しかし、エスプレッソメーカーのブランドである”Delonghi”(デロンギ)のような1つの単語を入力すると、ベクトル検索エンジンは他のブランドや別のマシン(Nespresso, Keurig, KitchenAidなど)も同様に返す可能性があります。それは、ベクターがデロンギというコンセプトしか理解していないからです。
新しいベクトルエンジンとは異なり、従来のキーワード検索エンジンは高速かつ正確です。したがって、”Delonghi Magnifica”を検索すると、まさにそれに該当する検索結果が得られます。しかし、キーワード検索エンジンは、クエリが検索インデックス内のコンテンツと一致しない場合に苦戦することがあります。この問題に対処するために、ルール、同義語、キーワードタグ付け、といったような回避策を追加することができますが、すべてのユースケースをカバーすることは不可能であると言えるでしょう。
例えば、”coffee”, “espresso”, “machine”, “milk” というキーワードを含むクエリは、すべて “espresso machine with steam wand” と同じ意味であるというルールを書くことができます。問題は、あらゆるロングテールなクエリのエッジケースをカバーしきれないということにあります。また、別の例として、”java”という単語を検索してみましょう。Javaはコーヒーやエスプレッソと同義で使われますが、検索エンジンに同義語やルールがない限り、クエリーは失敗となってしまいます。
ベクトルの効率的なインデックスを設計し、構築することは、複雑で高く付く作業です。同様に、ロングテールのクエリに対応する効率的なキーワード検索エンジンを構築することも、同様に困難な作業と言えます。ベクトル検索とキーワード検索は、それぞれ独立した技術としては非常に優れていますが、一緒に使えば、素晴らしいものとなります。
これはハイブリッド検索と呼ばれ、完全一致、あいまいな短いクエリ、ロングテールなクエリに有効です。
AI検索パフォーマンスのブレークスルー
ベクトルとキーワード技術をslap(引っ叩く)して一緒にしたら完成完成ってこと?ハイブリッド検索エンジンで解決だね!
そんなに簡単ならよかったのですが、、ご想像の通り、ここにはいくつかの課題があります。最大の課題は、ベクトル検索のスケールとコストです。ベクトルは基本的に浮動小数点数で表現しますが、コンピュータは浮動小数点数の扱いには手を焼きます。そのため、AIやベクトル操作にGPUなどの専用コンピュータが使われるようになっています。ベクトル検索を実行するためには専用のデータベースが必要なだけでなく、継続的に開発や保守運用を行うための専任の開発リソースが必要になります。AIモデルでは、モデルに供給されるデータが常に新鮮で、レレバントで、最適化されていることが非常に重要です。データが常に更新され、スピードが重要なeコマースやエンタープライズのビジネスにおいては、AI検索は本番運用するあためのコンピュートにかかるコストが高すぎます。
一部の会社では、キーワードによるクエリが失敗した場合にのみAIによるクエリを実行することで、この問題を回避しようと試みています。しかし、これでは処理コストを最小化するのに役立ちますが、お客様に最適な結果を提供することはできないでしょう。
多くの企業活動においては検索エンジンのインフラ整備に時間を取られることなく、自社のビジネスに時間とお金を使いたいと考えていることでしょう。その解決策として、私たちが開拓したアプローチが挙げられます。これはニューラルハッシングと呼ばれる技術です。ハッシュ化とは、情報を失うことなくベクトルを圧縮するための技術です。2000進数の複雑な長さを、単純で静的な長さの表現に変えることができるので、計算が非常に速く、コストは低くなります。ハッシュ化は、ベクトルに適用されるAIという観点においては、新しいコンセプトではありません。
Locality-Sensitive Hashing(LSH) は、類似した入力項目を同じ”バケット”に高い確率でハッシュ化する、よく知られたアルゴリズムです。通常”バケット”の決め方には、類似度が高いか低いかというトレードオフが存在します。しかし、今回のニューラルハッシュにおいてはそのトレードオフはありません。その結果、ニューラルネットワークを使ったベクトルを、最大99%の情報を保持したまま、通常の1/10のサイズに圧縮(ハッシュ化)することができるようになったのです(これがニューラルハッシュの名前の由来です)。また、一般的なハードウェアやデータベースで保存および管理をすることができます。実際にハッシュ化されたベクトル(バイナリベクトル)は、標準的なベクトルの類似性に比べて最大500倍高速に処理でき、キーワード検索と同等のスピードで配信することが可能です。しかも、通常のCPUで処理できるというのがポイントです。
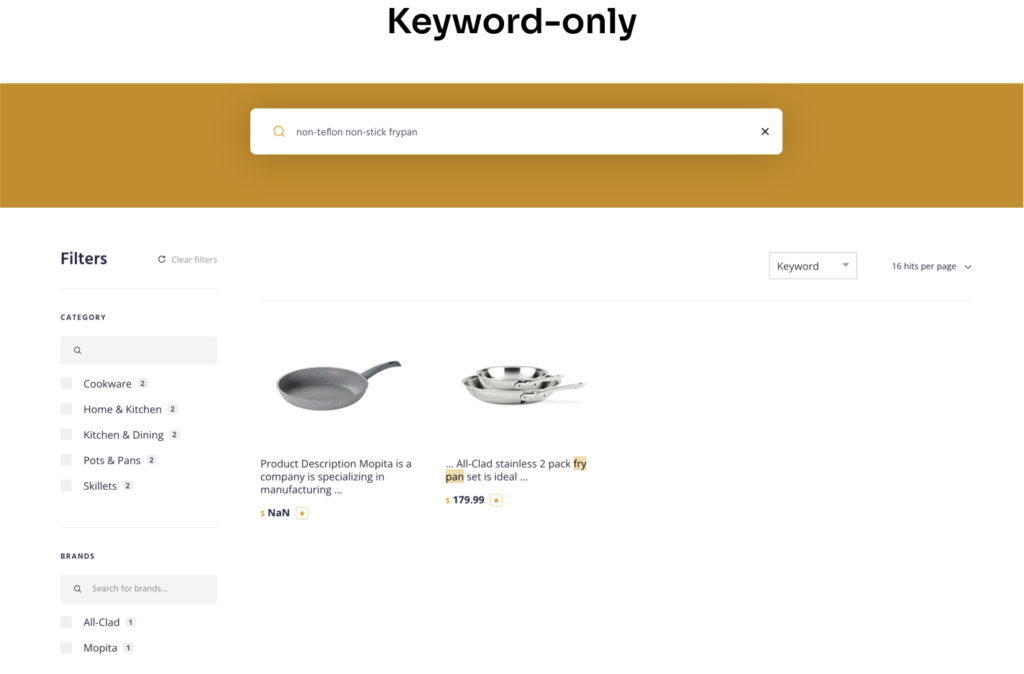
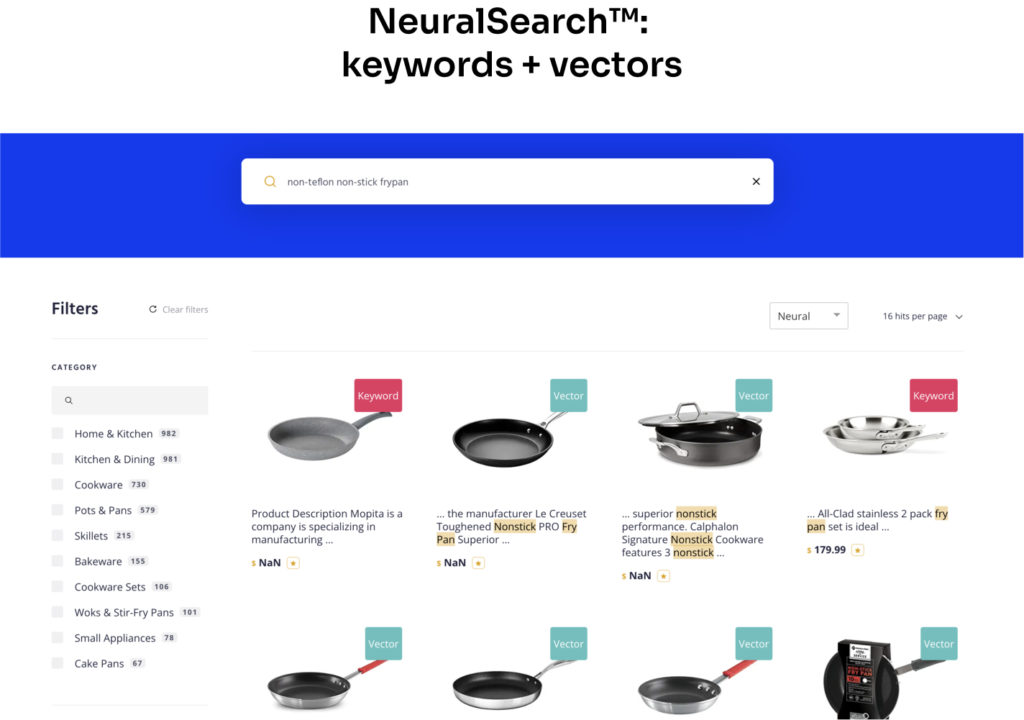
上のスクリーンショットからはいくつか重要な考察を得ることができます:
- ハイブリッドエンジンは、高い精度(precision)と高い再現率(recall)を両立しています。
- ハッシュとキーワードの両方を1つのクエリで実行しており、結合されたハイブリッドの結果はレレバンスによってスコアリングされ、ランク付けされます。
- これはコモディティなハードウェア上で動作しており、結果はほぼ瞬時に得られています。ハイブリッドによる検索結果は、キーワードのみの場合よりも遅くはありません。
また、”frypan”は2つの単語ではなく、1つの単語として書かれています。”fry pan”、”frying pan”、”skillet”と書くこともできますが、この検索エンジンはそのいずれにも対応します。このことは、AI検索のもう一つの重要な特徴であると言えます、検索結果のレレバンスを高めるためのマニュアルな作業の負担を大幅に軽減することにつながります。一般的な用語の同義語ライブラリを作成したり、特定の種類のクエリのルールを作成したりする必要はもうありません。また、Q&A検索の提供など、まったく新しい可能性も見えてきます。
この新機能は、Algolia NeuralSearch™で利用可能です。現在はプライベートベータ版となっていますが、こちらからサインアップしていただければ、利用可能になった際にお知らせ致します。
検索は、当然情報を抽出するということ以上の行為です。私たちのエンドツーエンドなAI検索ピラミッドのど真ん中に抽出(ニューラルハッシュ)があります。AIピラミッドの両端には、クエリ理解とランキングの機能があります。今後のブログでは、この他の2つの能力について触れていきたいと思います。
次のステップ
ニューラルハッシュは、さまざまなユースケースでAI検索を実用化するためのブレークスルーとなるものです。AIを利用したクエリ処理やリランキングと組み合わせることで、AI検索のパワーを最大限に引き出すことをお約束します。私たちは、これらの新しいエンドツーエンドのAI機能を間もなくリリースすることを楽しみにしています。今すぐ登録して、全く新しいAlgolia NeuralSearch™ プラットフォームをいち早くお試しくださいませ。


コメント