
こちらの記事は、Algoliaの Julien Lemoine (@jlemoine_algo) が書いた Advanced keyword search is built upon natural language processing (NLP) の翻訳です。
検索エンジンは、クエリを実行する前に、検索バーに表示された言葉を “処理”(process) する必要があります。この処理とは、クエリに書かれている内容とインデックスにある内容をそのまま(exactly)比較するというシンプルなものから、クラシックなキーワード検索においては、クエリをより小さなピースにトークナイズおよびノーマライズするといったより高度なものとなります。このプロセスは簡単なもの(単語がスペースで元々区切られている場合)と複雑なもの(アジアで使われている言語のようにスペースを使用しないためコンピューターが単語を認識する必要がある場合)があります。
クエリがブレークダウンされていくことで、検索エンジンはスペルミスやタイプミスを修正して、シノニム(同義語)を適用し、さらに語幹に絞り込んだり、複数の言語をやりくりするなどして、ユーザーがより “自然(natural)” なクエリを実行できるようになります。
自然言語キーワード – Natural language keywords
一般的には、人々は検索を行う際に、単一の言葉もしくは短いフレーズのクエリを入力します。つまり、文章全体や質問ではなく、キーワードを使用するということです。(しかし、音声検索技術やGoogleによる Question and Answer の成功により、この状況は変わりつつあります。)
このようなキーワード検索は、シンプルなものから高度なものまで、検索が始まった当初から存在しています。自然なものであるほど、その技術は高度になっていきます。検索エンジンは、検索インデックスから結果を取得する前に、入力されたクエリを構造化していく必要があります。この前処理的な技術は、自然言語処理(NLP)と呼ばれるものに該当します。NLPは、written(書かれた)やspoken(話された)によらず、人間の言葉をコンピューターが理解できるようにするあらゆる技術の包括的な用語です。
自然言語処理 (“NLP”) は、コンピューターが扱いやすい形にテキストを変換していきます。一般的なNLPの作業としては、ストップワードの除去、単語のセグメント化、複合語の分割などがある。また、品詞を特定したり、テキスト内の重要なエンティティを特定したりといったことも行います。
— Dustin Coates, Product and GTM Manager at Algolia
Algoliaでは、自然言語処理(NLP)についてかなり多くの記事を書いてきました。例えば、NLPの定義、NLP vs NLUの比較、そしてポピュラーなNLP/NLUアプリケーションなどをご紹介してきました。さらに、Algoliaのエンジニアは、Algoliaのエンジンがどのように言語を処理して、多言語検索をやりくりしているのかについて説明してきました。こちらの記事では、AI/MLベースのベクトル埋め込みとハッシュ化を含むハイブリッド検索ソリューションにおいて重要なピースであるキーワード検索を、NLPがどのように行うかを見ていきます。
キーワードとNLPの結びつきを理解するために、まずはキーワード検索を深く掘り下げていくことが重要です。
キーワード検索とは何か? – What is keyword search?
キーワード検索エンジンの最も基本的な機能は、クエリのテキストを検索インデックス内の各レコードのテキストとそのまま比較することです。一致するすべてのレコード(完全一致か類似かによらず)が、検索エンジンによって返されます。マッチングには、シンプルなものと高度なものがあります。
私たちは、洋服や映画、おもちゃ、車などをキーワードで表現します。ほとんどのキーワード検索エンジンは、構造化データに依存しているので、インデックス内のオブジェクトは、単一の単語もしくはシンプルなフレーズで明確に記述されています。
例えば、花はタグもしくは “keys” を使って、key-value のペアを構成することができます。Values (大きい、赤い、夏、花びら4枚) は Keys (サイズ、色、季節、種類、花びらの枚数) とペアとなることができますし、また、この花は “4.99” という “price(価格)” で販売することができます。
この keys と values の構造を以下のように表現することができます:
{
"name": "Meadow Beauty",
"size": "large",
"color": "red",
"season": “summer”,
"type of object": "flower",
"number of petals": "4",
"price": "4.99",
"description": "Coming from the Rhexia family, the Meadow Beauty is a wildflower.”
}これらの key-value ペアは、検索インデックスに格納できるレコードを構成し、例えばは “red flower” というクエリは、”type = flower” かつ “color = red” の花のレコードをすべて返します。
さらに、”red” のような部分的なクエリでも、”color = reddish-green” にヒットします。これは “red” が “reddish” に含まれるためです。
多くのキーワード検索エンジンは、マニュアルで定義されたシノニム(同義語)を使っています。したがって、”blue” と “azure” が同義語であることを明示的にエンジンに設定することで、”blue” のクエリで “azure” の花を返すことができます。
そのほかにも、スペルミスやタイプミスを修正するテクニックもあります。”4 pedels” というクエリにはタイプミスがありますが、タイプミスに強いエンジンは正しいスペルの4枚の花 (“petals”) を返すことができます。このエンジンは “4” を “four” の同義語として扱うこともできます。また、複数形の “petals” と単数形の “petal” を、同じ語幹の “petal” に基づいてマッチングさせることもできます。
“4 pe” のような部分的な検索は、 “4 petals” にマッチします。ほとんどのキーワード検索エンジンはプレフィックス検索が可能で、ユーザーが入力中に検索結果を表示させたり、クエリの候補を表示させたりできる重要な機能である “as you type” を実現しているからです。
他にも様々なものがありますが、もう一つの例として、Transliteration があります。トランスリテレーションは、その言語の文字や読みを別の言語の文字や読みにマッピングするというものです。例えば、ラテン文字 (a、b、cなど) を入力してロシアのキリル文字を検索したり、日本語のひらがなを入力してカタカナを検索したりすることができます。
キーワード検索の レレバンス&ランキング アルゴリズム
キーワード検索エンジンは、これらの言語処理技術を使って、優れた検索ソリューションの2つのゴールであるレレバンスとランキングを行います。
レレバンス
レレバンスは、クエリに一致するすべてのレコードを探し当てます。
レレバンスは、タイポトレランス、部分的な単語のマッチング、マッチした単語間の距離、マッチした属性の数、シノニムやルール、ストップワードや複数形などの自然言語の特性、地理的なロケーション、その他人々が検索から期待する多くの直感的な側面、特にGoogle時代のものを考慮に入れたインテリジェントなマッチングに依存します。
ランキング
ランキングはヒットしたレコードを順番に並べます。
ランキングは、検索によって返ってきたレコードを、より正確な結果が最も上に(最初の数ページに)表示され、より正確でない結果が後に表示されるように並べる手法です。
キーワード検索のアルゴリズム
ベストなレレバンスとランキングを達成するために、エンジニアはベストなアルゴリズムとデータ構造を設計して、ベストなテキストの比較を可能にする必要があります。
レレバンスについては、数多くのデータ構造と検索アルゴリズムの中から選択することが可能ですが、キーワード検索は、転置インデックスを使用して、キャラクターベースの比較を適用するのが最も効果的であると言えます。これは、それぞれの文字 (文字、数字、キーボード上のほとんどの記号) が、その文字を含む1つ以上のレコードを参照するように、検索エンジンがデータを前処理を行うことを意味します。例えば、あるエンジンが “aardvark” を検索インデックスと比較を行う場合、upside-down lookup (逆から参照する) を実行して、a-aa-aar-aard-aardvard-aardvar-aardvark という文字を含むすべてのレコードを探し出そうとします。
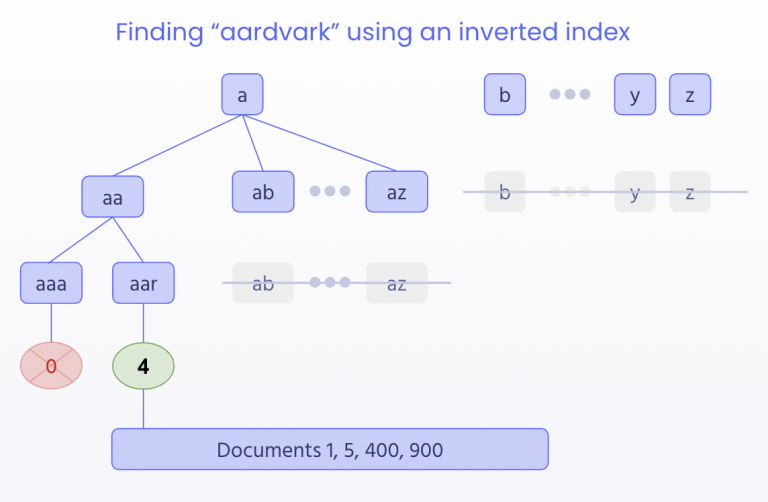
この転置インデックスは、タイポや他のキーワード検索にも適用することができます。
レコードが見つかったら、最後のタスクはエンジンが結果のランキングを行い、最もマッチしたものがリストのトップに表示されるようにすることです。ここにもさまざまなテクニックがあります。例えば、マッチした単語の頻度(frequency)に基づく統計的なランキング等があります。私たちが選んだのは、tie-breakingアルゴリズムです。これは、エリミネーションゲームに似たようなトップダウン型のタイブレーク戦略を適用して、レコードをランク付けするというものです。
良い例としては、1つ目と2つ目のクライテリアであるタイポ(typo)とジオロケーション(geolocation)について見てみましょう。アメリカで “theatre” を検索すると “theatre” または “theatre” のどちらかを含むレコードが返され、イギリスのスペルはタイポとして扱われます。タイブレーキング(tie-breaking)アルゴリズムはベストマッチを優先するので完全に一致するレコード (タイポなし= “theater”) がベストマッチとして選択され、イギリスのスペリングはリストの下になります。
続いて、(“theater”を含む)ベストなレコードは、2つ目のクライテリアであるジオロケーションにかけられます。ユーザーの近くにある(座標が似ている)劇場が、ベストとして選択されるのです。同点解消アルゴリズムは、すべてのレコードが順位付けされるまで、次の6つのテスト(部分一致の前に完全一致がある、2単語のクエリの単語間の距離、など)を適用し続けます。
自然言語処理 – Natural language processing
キーワードに基づくレレバンスとランキングのアルゴリズムは、自然言語処理(NLP)を元にして構築されています。NLPは言語の複雑さをやりくりします。例えば、単数形と複数形、動詞の変形(現在形/過去形/現在分詞形 等)、膠着言語や複合言語といったことなどが挙げられます。以下にNLPのテクニックをいくつか紹介しますが、まずNLPの基本であるtokenization(トークナイゼーション)とnormalization(ノーマライゼーション/正規化)の2つを定義していきます。
トークナイゼーションとは何か
トークナイゼーションは、大きなテキストをより小さなピースに分割します。ドキュメントを段落に、段落をセンテンスに、センテンスを “トークン” に分割することもあります。トークナイゼーションはとても難しい場合があります。例えば、段落内の文を識別するような簡単なことでさえ、厄介なのです。”Michael J. Fox” は、ピリオドの後に大文字の単語が続いているので、2つの別々の文なのでしょうか?といったようなことがあります。
ノーマライゼーション/正規化とは何か
自然言語処理におけるlow-levelのステップとしてよく知られているのがノーマライゼーション/正規化です。このステップの目的は、すべてのクエリを標準化して、タイプされたものよりもletter(文字)に依存させることです。例えば、大文字の “Michael” と小文字の “michael” を区別して扱うのではなく、両方を “michael” に正規化するといったものです。アクセント記号や特殊文字についても、同様の正規化を行います。
- カノニカルな形式に: À → A and ß → ss
- カノニカルな形式を小文字に: À → A → a
パース(トークナイズおよびノーマライズ)後にNLPは何をする?
ここではNLPの標準的なテクニックをいくつかご紹介します。
- Transliteration(トランスリテレーション): 前述のように、トランスリテレーションはある言葉の文字を別の言葉のアルファベットで検索することを可能にします。例えば、ロシア語のラテン語→キリル文字、日本語のひらがな→カタカナ、中国語の繁体字→簡体字 などがそれにあたります。
- ステミング: ステミングは、接頭辞や接尾辞を取り除いて、単語を基本形に変換することです。ステミングでは “run” と “running” をマッチさせたり、”change” と “changing” をマッチさせることができます。キーワード検索においては “puppy” と “puppies” の語幹である “pupp” といった名詞の語幹処理に関わることが多いのが特徴です。
- レンマ化: レンマ化は、ステミングと同様に単語をベース(もしくはroot)の形に分解しますが、それぞれのコンテキストと形態上の基本を考慮に入れて行われます。例えば “feet” を “foot” に、フランス語の “œil” を “yeux” に変換するといった不規則な複数形の変換を行うことが可能です(但し、エンジンは最初に “œ” → “oe” にノーマライズするでしょう)
- セグメンテーション: 英語や多くのラテン語ベースの言語では、スペースが単語の区切り記号(もしくは単語のデリミタ)となりますが、それぞれの言語で単語のパーツの組み合わせや区切り方が異なるため、この概念には限界があると言えます。例えば、英語の複合名詞の多くは可変長の表記になっています(ice box = ice-box = icebox)。しかし、このスペースはすべての書き言葉にあるわけではないため、その場合は単語の分割が困難な問題となります。また、単語分割を行わない言語としては、単語ではなく文を区切る中国語や日本語、単語ではなくフレーズや文を区切るタイ語やラオス語、単語ではなく音節を区切るベトナム語などがあります。
- 膠着化: いくつかの言語(ドイツ語、オランダ語、フィンランド語 等)では、複数の名詞をスペースなしで連結して新しい単語を作ることが可能です。例えば、BaumhausはBaum(木)とHaus(家)からなるドイツ語で、”木の家” を意味します。”Baumhaus”(木の家) を検索する人は、”Baumhaus” だけでなく、”Haus in einem Baum”(木の中の家)のような単語を含む結果に興味を持つ可能性も非常に高いと言えるでしょう。さらに驚くべきチャレンジは、アイスランド語の “Vaðlaheiðarvegavinnuverkfærageymsluskúraútidyralyklakippuhringur” で、これは意味を持つ小さな単語を組み合わせたものとなります。これは “ヴァズラヘイジ荒地にある道路作業員の用具保管用の小屋の外扉の鍵のリング” という意味なのだそうです。道路作業をする人にとって、非常に的確で、おそらくヴァズラヘイジ荒地の用具小屋を開ける必要があるときに役立つものでしょう。
- 品詞のタグ付け: 品詞タグは、文法的なタグ付けとも呼ばれていて、特定の単語やテキストの一部について、その用途やコンテキストに基づいて品詞を決定する処理になります。”make” は、”I can make a paper plane” では動詞として、”What make of car do you own” では”種類”という名詞として識別されます。
さらにNLPを使いこなす – Semantics (セマンティクス)
キーワード検索技術に、NLU(自然言語理解)やベクトルベースのセマンティック検索など、よりAIを駆使した技術を取り入れていくことですることで、検索を新たな次元に引き上げることができます。
以下はほんの一例になります:
- ニュース記事やブログ記事の要約
- ウェブページの言語の検出と翻訳の提供
営業電話の記録から重要なトピックの特定
Twitterで表現された感情の分類
カスタマーサービスの依頼を受けるボット
検索要求に対しる適切な商品の提供
スマートボイスアシスタント
そして、以下がセマンティックベースのNLPのテクニックのサンプルです。
- エンティティ抽出: エンティティ抽出は、音声検索において特に重要となっている。その名の通りに、エンティティ抽出とは、クエリのさまざまな要素(人、場所、日付、頻度、数量 等)を識別してマシンがその情報を”理解”できるようにする方法のことを言います。エンティティ抽出は、単純なキーワード検索の制限を克服するための非常に優れたソリューションです。
- 語感(Word sense): 言葉の中から複数の意味を見出すことです。例えば、”make the grade” (達成) の “make” という動詞は”make a bet”(ベットする)の意味とは異なるでしょう。
- 共参照解析(Co-reference resolution): 2つの単語を同じエンティティとして扱ったり(例: “She” + “Mary”)、文章中の比喩や慣用句の表現の見出したりします(例: “bear”は動物ではなく”大柄で毛深い人”)。
- センチメント(感情)分析: テキストから態度、感情、皮肉、混乱、疑念といった主観的なものの抽出を試みます。
まとめ – NLPはキーワードの曖昧さを低減させる
人間の言葉は曖昧さに満ち溢れているので、テキストや音声データの意図する意味を的確に判断するソフトウェアを書くことはとても困難です。同音異義語、同訓異字、皮肉、慣用句、比喩、文法や用法の例外、文構造のバリエーションなど、人間が何年もかけて学習した人間の言葉の不規則性は数多くに渡りこれらはほんの一例でしかありません。アプリケーションが有用であるためには、プログラマーが自然言語ドリブンなアプリケーションに正確に認識、理解できるように学習させる必要があります。
言語の最も複雑といえる側面に対応するために、NLPは時代とともに変化してきました。この変化の中心となっているのが、人工知能、特にベクトルや大規模言語モデル(LLM)といった機械学習モデルです。翻訳や自然言語理解(NLU)の分野では、機械学習によって検索プロセスが大幅に簡略化および改善されました。ベクトル空間は、同義語を手動で作成する必要性をなくしました。この記事では、キーワード検索の目的と方法、および特定の必須なNLP技術に焦点を当てました。NLPは、キーワード検索のクエリレベルの機能を強化するために進化し続け、私たちが日常的に行っている単純なクエリを処理する方法として残っていくことでしょう。


コメント