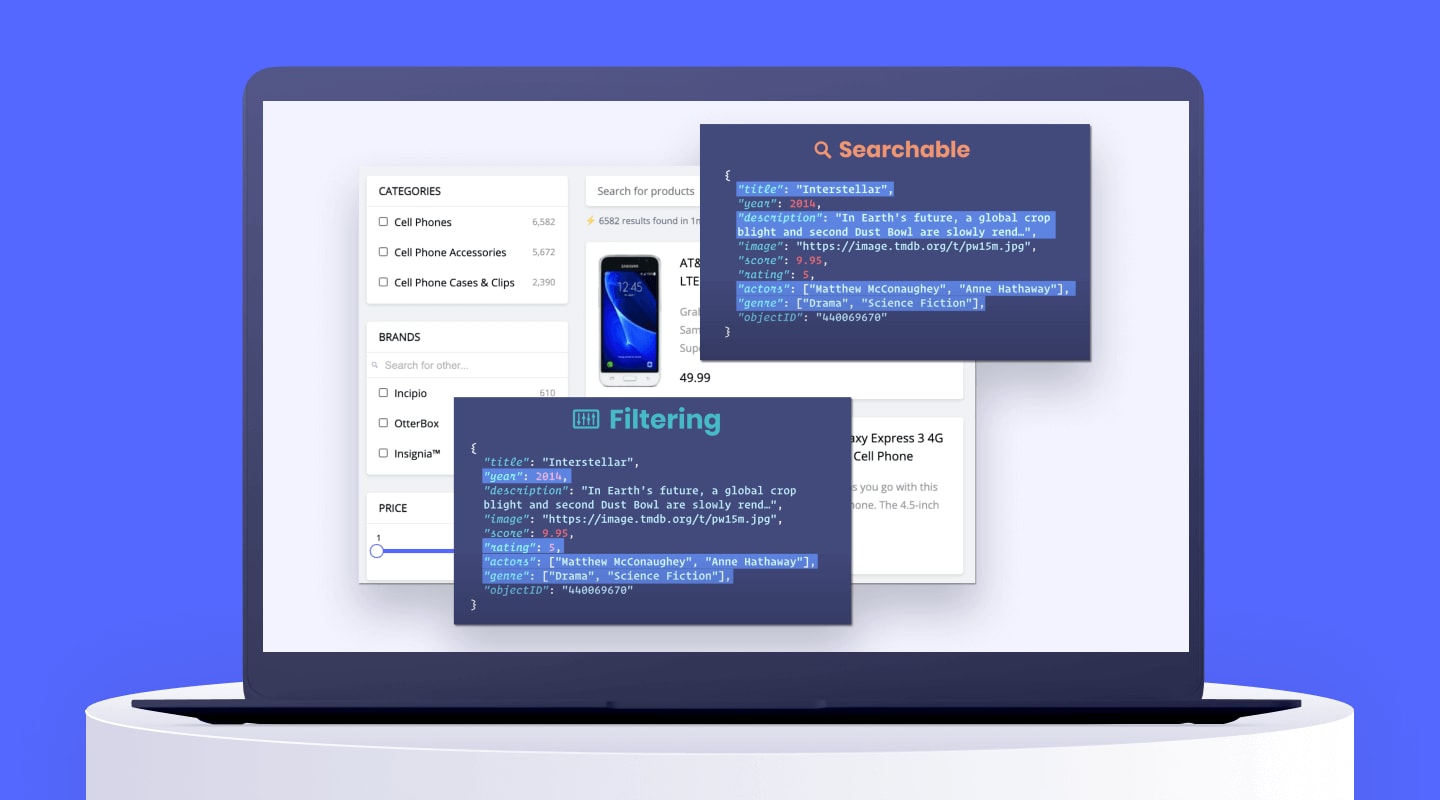
こちらはAlgoliaブログの A facets data model using JSON という記事の翻訳になります。
フロントエンドUXの多くのパターンを実装するために、Facet検索には、正確であり、且つ、well-tailored(仕立て上げられた)なFacetデータモデルを必要とします。JSONのレコードでファセットを表現する方法はたくさんありますが、ほとんどのファセットはシンプルなものであり、プロダクトやサービスを表現するために必要なものはsingle-wordなフィルターのみです – appleは果物、Appleはブランド。つまり1つの属性で”apple”を表現できます。
{
"name": "apple",
"type": "fruit",
"seasonal_categories": ["fruits->late-summer", "fruits->autumn"]
}もしくは
{
"name": "iPhone 8 Gold Protection Screen",
"brand": "Apple",
"category": ["smartphone->protective-screens"]
}ファセットの”type”と”brand”はsingle-dimentionな属性ですが、ファセットはより複雑になることがあります: 階層やネストした属性として設定をすることもできるということです。こちらの記事では、ファセット検索やガイドされたナビゲーションの中心となるようなフロントエンドの機能を、異なるファセットデータモデルがどのように実現をするのかをみていきたいと思います。
- 検索のフィルタリング
- アイテムのカテゴリおよびサブカテゴリへの配置
- カテゴリーページの作成
- Federated Searchを使った複数のカテゴリーの表示
JSONレコードにおけるファセットデータモデルの作成
4つの一般的なファセットとフィルターの定義をご紹介します。それぞれの方法には目的とアドバンテージがあります。
- Simple (“type”: “fruit”)
- Nested (actors->( (actor1->name, actor1->character_name), (actor2 …) ) )
- Hierarchies (“category: food->fruit->seasons”)
- Tagging (tags: “drama”, “fun to watch with friends”, “must watch again”)
Simple facets
最もシンプルなファセットは、最も重要なものであると言えます。ミニマムなキーワードでそのオブジェクトのエッセンスを伝えることができます。シャツには半袖と長袖があります。映画の平均レーティングは1つだけです。しかし、シンプルなファセットは複数の値を保持することも可能です。Tシャツは1つの色もしくは赤と青がミックスされている場合もあります。映画は”romantic sci-fi comedy spoof”であるかもしれません。シンプルで正確なタグ付けはユーザーが探していたものを正確に提供し、最高のアイテムをもたらすのに役に立ちます。前回のファセット検索の記事では、ファセットはフィルタリングだけでなく検索にも活用できることを議論しました。
JSONを使うと、シンプルなファセットを簡単に表現できます:
{
"name": "bold t-shirt",
"desc": “Be bold, wear a t-shirt with only one color”,
"color": “white”,
"sleeves": "short"
},
{
"name": "Hippie Vest with Fringes",
"desc": “Be hip: get back to where you belong, peace + love”,
"color": ["red", “orange”, “yellow”, “green”, "blue"],
"sleeves": "long"
}Nesting facets
よりアドバンストなファセットはネストした情報を含みます。ネストとはデータを構造化することです。データの構造化はアイテムに関するストーリーを伝えます。ネストしない例と複数のネストの例を比べてみましょう。
Simple Value:
{
"name": "Brad Pitt"
}Simple Nesting:
{
"first_name": "Brad",
"last_name": "Pitt"
}少し複雑なNesting:
{
"actors": [
{
"first_name": "Brad",
"last_name": "Pitt"
},
{
"first_name": "Scarlett",
"last_name": "Johanson"
}
]
}※ ここでは actors を検索と、特定の actor によってフィルタリングするファセットとして使用します
ネストされたファセットをいつファセット検索に用いるか
必ずしも、データを構造化したり、ネストさせたりといった必要はありません。検索においては、レコードを探し当てることが最大の関心事ですが、こちらは構造ではなく、コンテンツが全てです。例えば”brad pitt”を探す場合、Simpleでも複雑でもどちらでも同じように機能するでしょう。
JSONを構造化することで、人間にとってより分かりやすくなるかもしれませんが、エンジンそのものはSimpleでも複雑でもどちらの構造でも動作をします。データを構造化することは、常により多くの思考と時間を必要とするため、あまり考えすぎる前に、そのバリューと目的を考慮することの方が重要であると言えます。
しかし、Simple Nestingは検索パターンを予想することを可能にさせます。例えば、名字で author を探す場合、”last_name” という属性を作ることは理にかなっています。
{
"last_name": "King",
"first_name": "Stephen"
},
{
"last_name": "Shakespeare",
"first_name": "William"
}より複雑なネストはフィルタリングや検索だけでなく、ディスプレイ用途にも使われます。ひとつの例としては、アイテムの情報を項目別に表示するということがあります。では、シンプルな属性を必要とするものと、複雑なネストを必要とするものを比較してみましょう。DVDを販売している会社では、必ずしも構造を考え過ぎる必要はありません。ユーザーが映画を探すのに必要十分な情報がレコードに含まれていれば良いというだけです。ここでは2つだけの属性を扱います:
{
"title": "Avengers: Infinity War",
"cast": ["Robert Downey Jr", "Chris Hemsworth", "Mark Ruffalo", "Chris Evans", "Scarlett Johansson"]
}一方で、IMDBやNetflixのように映画の詳細情報を提供するウェブサイトでは、より構造化された情報を表示する必要があります。
{
"title": "Iron Man",
"cast": [
{
"first_name": "John",
"last_name": "Smith",
"birth_year": "1978",
"birth_place": "New York City, New York"
},
{
"first_name": "Robert",
"last_name": "Downey Jr",
"birth_year": "1965",
"birth_place": "New York City, New York"
}
]
}この2つめのレコードには、画面上の情報ボックスのデータが含まれます。唯一注意しなければならないことは、インデックスに複雑なネストが含まれているような場合は、構造のどの部分を検索するかをエンジンに示す必要があるということです。例えば、”cast.first_name”と”cast.last_name”はSearchable(検索可能)で、”cast.birth_year”は検索とフィルタリングの両方に対応するようにする必要があります。
Hierarchies(階層型)
多くのファセット検索では、ユーザーがカテゴリやサブカテゴリの階層をブラウズし、検索結果を絞り込んだり、もしくは、広げたりといったことができます。ヒエラルキー(階層)を使って、category-basedのメニューシステムを作ることができます。複雑なカテゴリーのデザインとメンテナンスには時間がかかるわけですが、階層化を正しく行うことで、素晴らしいファセット検索とナビゲーション体験が作り出されます。では、スーパーマーケットがデータをカテゴライズし、オンラインで正しい流れで見つけられるようにする方法を見ていきましょう:
[
{
"name": "lemon",
"categories.lvl0": "products",
"categories.lvl1": "products > fruits"
},
{
"name": "tomato",
"categories.level0": "products",
"categories.level1": "products > summer",
"categories.level2": "products > summer -> vegetables"
}
]本屋さんにおいても、著者ごとにカテゴリーを分けて、複数の階層に分けています:
{
"name": "Ursula K. Le Guin",
"categories": [
"level0": "Books",
"level1": ["Books > Science Fiction", "Books > Literature & Fiction"],
"level2": ["Books > Science Fiction > Time Travel", "Books > Literature & Fiction > Literary"]
]
}Tagging(タグ付け) – User-created もしくは AI-generated
全てのファセットはあなたもしくはあなたの会社で管理されている必要はありません。そして、ユーザーはあなたのプロダクトやサービスをどのように定義やカテゴライズするかについて独自のアイデアを持っていることがあります。例えば、”Breaking Bad”をTVシリーズと犯罪ドラマにカテゴライズするかもしれませんし、他のユーザーにはその人のアイデアがあるでしょう。ここでは、すべてのユーザーによるタグを”_tags”という属性にまとめています。
{
"title": "Breaking Bad",
"_tags": ["drugs", “father figure”, “cancer”, “midlife crisis”, “violent”, “not for kids” ]
}何もファセットタグを追加するのはユーザーだけではありません。機械学習アルゴリズムをはじめとしたAIは、ユーザーの行動、プロダクトの説明文、マーケットデータなどを組み合わせることによって、そのアイテムにタグ付けをするための方法を見つけ出すようなことが増えています。例えば、ユーザーが検索、クリック、カタログを参照した時に、AIのauto-taggingによって思いつかなかったような選択肢が追加され、プロダクトのカテゴライズがより良くなったり、年齢層や目的やその他のことによって今まで考えたこともなかったようなプロダクトのキャラクターを得ることができます。
ポピュラーな例として、画像のauto-taggingが挙げられます。画像検出アルゴリズムが画像にタグ付けをするというものです。GIFや画像を提供するPinterestのようなサイトは、こういった技術を活用しています。
メジャーな休日の前にいつも同じアイテムを購入しているユーザーを想像してみてください。AI-generatedなタグは以下のように生成されるかもしれません。
{
"name": "Scotch tape",
"_tags": ["Christmas", “Halloween”, “New Years”]
}この情報は、マーチャンダイズおよびコンテンツの管理に利用できるでしょう。例えば、”Scotch tape”がホリデーシーズンの間に検索結果の上位に表示されるようにするといったことです。
それに加えて、タグをファセットとしてレコードにトランスフォームすることもできます。ここでは、タグを分析し、新しいファセットである”holiday_accessory”を新たに作成しています。
{
"name": "Scotch tape",
"holiday_accessory": true
}multi-purposed(多目的)なファセットデータモデルを活用しよう
前回の記事でファセット検索について説明しましたが、ファセットはコンテンツを検索するのに便利です。ユーザーが入力したキーワードと一致するファセットを持つことで、検索体験が測定できる形で向上します。機能的なレベルでは、エンジンにとっては、カテゴリーを検索しているのか、Simpleファセットを検索しているのか、それともnon-facetを検索しているのかといったことは実際のところ関係ありません。つまり、探せといわれたところを探すのです。ということで、必要に応じて特定の属性を検索するようエンジンの設定をすることが重要なのです。
そういったところを踏まえて、複雑なネスト構造が、検索結果においてレコードの中のアイテムについてのストーリーを語るといったことには既に触れました。Amazonは、プロダクト名、説明文、値段、そして画像だけでなく、レーティング、配送情報、人気度、カテゴリといった情報も結果として表示しています。
ここでの秘訣は、こういったextraな情報を全てSearchableな1つのインデックスにまとめる、ということです。全ての属性を再利用し、検索、フィルタリング、and/or 表示の目的に使うことができます。これによって、追加情報を取得するために他のデータベースにアクセスするというセカンドトリップが必要がなくなります。
これに関しては、このファセット検索シリーズの次のポストで詳細をご紹介します。
ファセットデータモデルのまとめ
Simpleでも複雑でもファセットは、ファセット検索およびブラウジングに基づくナビゲーション体験を創出します – 検索であろうとなかろうと。ファセットの表示方法は様々です – 画面左側、中央のフロント、ドロップダウン、メニューといった様々な方法がありユーザーが簡単にシングルクリックでブラウズ可能になります。
しかし画面のどこに表示をするにせよ、またどのようにそのデータ上にデザインされたとしても、ファセットがあることで、ユーザーはクリックやブラウズによって究極的にはプロダクトやサービスのfull onlineカタログをディスカバーすることができます。ここでの技術的なポイントとしては、その根底にあるJSONの構造が、フロントエンドのニーズにあわせてwell-tailoredでなければならないということです。こちらの記事が、どのようなセクターもしくはドメインでも使える一般的なユースケースのためのソリッドな基礎をご紹介できていれば幸いです。
コメント