
この記事はAlgoliaのXavier Rocheが書いたWhen allocators are hoarding your precious memoryの翻訳です。
最新の流行しているフレームワークや言語へスイッチすることは、近頃エンジニアリングの世界では常套句のようなものになりつつありますが、もちろん既存の技術をアップグレードする必要な場面だってあるわけです。私達のSearch Engineering Teamは検索エンジンのコアな機能の維持に努めているわけですが、最新のコードリリースに迅速に対応して、最新のカーネルやライブラリの機能の恩恵を享受するため、オペレーティング・システムのバージョンをアップグレードする、といったこともこれに含まれます。私たちはいつもOSのアップグレードを待ち望んでいて、事実として、かなりの時間をかけてそのことに取り組んできました。
本番環境のオペレーティング・システムをアップグレードするというのは大変なことで、世界中の70以上のデータセンターにまたがる何百台ものサーバーの更新を行います。私たちの本番環境のサーバーは現在はUbuntu 16.04を使っていて(実に4年以上も前にリリースされたもの)、AlgoliaのFoundation Team (全ての本番環境のサーバーを管理して、常にSLAを上回るようにサービスが稼働することを保証するミッションを持つチーム)は、より新しい 20.04 のlong-termバージョンへのアップグレードの準備に取り組んできました。
しかし、アップグレードはタフである
多くのコンポーネントのバージョンを変更することになるので、万が一の(不幸せな)事態に備えておく必要があります: カーネルとそれに関連するドライバー、オペレーティング・システムのCライブラリ、また様々なライブラリだけでなく、その戦略、ポリシー、デフォルトの設定といったOSに関連する多くのこと
私たちが直面したアップグレード中に発生した不幸なサプライズの一つは、全体的なメモリの消費量でした。。こちらのグラフ(Wavefrontのメトリクス)が示しているように、Used Memoryに関する緑のグラフが激しいことになっていることが見て取れるかと思います。

元々10〜30GBくらいのメモリ使用量で推移していた(平均は12GBくらい)ものが、30〜120GBへと跳ね上がっています(平均は100以上)。メモリ使用量としてはもっと高くまで行くのかもしれませんが、私たちのマシンは物理メモリが128GBがMAXのものを使っているのでそれ以上にはなりようがありません。この128GBというメモリについては通常は必要十分であり、通常であれば大きなページキャッシュに使われます。そして、メモリ使用量がドロップしているところは、私たちの貴重なメモリを食い散らかしているプロセスが私たちによって強制的にリロードされているか、もしくはangryなカーネルによって強制的に停止されたものになります(これによってあちことでアラームがトリガーされまくってしまい、面倒なことになりました…)
私たちが抱える問題は、スタートアップ企業として、10x engineerといったステレオタイプを満たすことが求められることがありますが、恐らくこれは、私たちが目指している10xではないでしょう。笑
調査
皮肉にもほどがあると言いますか、システムのアップグレードをプッシュしたのは私たちですが、今では私たちがサーバーがメモリを大量消費することに対処しなければなりません。そこで、やらなければならないことはただ一つ。私たちはアップグレードがなぜこれほどまでに劇的な影響を及ぼしたのかを理解する必要があったのです。
リーク
最初に思いついたのは何らかのメモリリークでした。しかし、最新のLinuxバージョンにだけ存在するもの?もしくは今までのシステムでは条件を満たさないメモリリークをトリガーさせる何かがある?
この仮説を検証するために、私たちは日頃、Brendan Greggさんの素晴らしくパワフルなLinux perfプロファイラを使っています。パフォーマンスに興味関心を持つ全てのエンジニアはこのツールについて知っておくべきで、マスター(Brendanさん)自身によるプレゼンテーションは見ておいた方がいいでしょう。
プロファイリングを行う典型的な手法としては、実行中のデーモンプロセスにアタッチして、解放されていないメモリ(10分後くらい)をfrom time to timeに探るといったようなものになります。
1
sudo memleak-bpfcc -a --older 600000 --top 10 -p 2095371 120残念ながら、私たちは何もリークを見いだせませんでした – そしてこれを行っている間でさえ、私たちの貴重なギガバイトにおよぶRAMが食い散らかされていたのです。
ということでメモリリークが原因ではありませんでした。続いてロジカルに疑うべきはメモリアロケーターでしょう。
貪欲なアロケーター
混乱をさせてしまうかもしれませんが、このブログではいくつかのアロケーターが出てきます。開発者であれば、malloc を聞いたことがあるかと思います。これはC library(glibc)にあるものです。私たちはデフォルトのglibc allocatorを使っています。これはどんなサイズのメモリの割り当てを行うようなリテーラーのような存在としてみることができるでしょう。しかし、glibc自体が自らメモリの割り当てをすることはできず、カーネルだけが行えるものとなっています。(リテーラーに対して)カーネルはホールセラーであり、大量にしか販売することはありません。そのため、アロケーターは通常カーネルから大きなメモリのチャンクを取得して、要求に応じてそれを分割するような動きをします。メモリを解放するときは、空いた領域をコンソリ(統合)して大きなチャンクを解放しようとします。
しかし、アロケーターはその戦略を変更することができるのです。例えば、いくつかのリテーラーがあったとして、プロセスの中で事項される複数のスレッドにそれぞれ割り当てたとします。すると、それぞれのリテーラーは後で再利用するために解放された大きなメモリのチャンクの一部を保持するという戦略をとることも出来るようになります。そうすることで、リテーラーは”貪欲”になり、言ってみれば抱えている余剰在庫の解放を拒否するといったような状態になってしまいます。
この新しい仮説を検証するために、私たちはglibcアロケーターを直接使って”ガベージコレクター”をコールすることにしました。
MALLOC_TRIM(3) Linux Programmer's Manual MALLOC_TRIM(3)
NAME
malloc_trim - release free memory from the top of the heap
SYNOPSIS
#include <malloc.h>
int malloc_trim(size_t pad);
DESCRIPTION
The malloc_trim() function attempts to release free memory at the top
of the heap (by calling sbrk(2) with a suitable argument).
The pad argument specifies the amount of free space to leave untrimmed
at the top of the heap. If this argument is 0, only the minimum amount
of memory is maintained at the top of the heap (i.e., one page or
less). A nonzero argument can be used to maintain some trailing space
at the top of the heap in order to allow future allocations to be made
without having to extend the heap with sbrk(2).
RETURN VALUE
The malloc_trim() function returns 1 if memory was actually releasedシンプルでありながらも hacky なソリューションとしては、デバッガ(gdb -p pid)を使ってプロセスにアタッチし、手動で malloc_trim(0)をコールする、というものです。そして、結果はそれ自身が物語っていました、、、

オレンジの線がアップグレードしたサーバーのメモリ消費で、他の2つの線は以前のOSのバージョンのものです。09:06付近の急激なドロップは malloc_trim functionの呼び出しによるものです。
このcorner-case(レアなケース)の問題に対処するため、私たちは別の有用なglibc-specificなfunctionを使ってアロケーターの状態をダンプすることにしました:
MALLOC_INFO(3) Linux Programmer's Manual MALLOC_INFO(3)
NAME
malloc_info - export malloc state to a stream
SYNOPSIS
#include
int malloc_info(int options, FILE *stream);
DESCRIPTION
The malloc_info() function exports an XML string that describes the
current state of the memory-allocation implementation in the caller.
The string is printed on the file stream stream. The exported string
includes information about all arenas (see malloc(3)).
As currently implemented, options must be zero.
RETURN VALUE
On success, malloc_info() returns 0; on error, it returns -1, with
errno set to indicate the cause.そしてまたgdbを使ってアタッチしていきます。
(gdb) p fopen("/tmp/debug.xml", "wb")
$1 = (_IO_FILE *) 0x55ad8b5544c0
(gdb) p malloc_info(0, $1)
$2 = 0
(gdb) p fclose($1)
$3 = 0
(gdb)ダンプされたXMLは興味深い情報を提供してくれました。そこにはおよそ100に近いヒープ(“リセラー”)がいて、厄介な統計を示していました:
<heap nr="87">
<sizes>
... ( skipped not so interesting part )
<size from="542081" to="67108801" total="15462549676" count="444"/>
<unsorted from="113" to="113" total="113" count="1"/>
</sizes>
<total type="fast" count="0" size="0"/>
<total type="rest" count="901" size="15518065028"/>
<system type="current" size="15828295680"/>
<system type="max" size="16474275840"/>
<aspace type="total" size="15828295680"/>
<aspace type="mprotect" size="15828295680"/>
<aspace type="subheaps" size="241"/>
</heap>glibcのソースを見ると、この”rest”セクションはフリーブロックのように見えます。
fprintf (fp,
"<total type=\"fast\" count=\"%zu\" size=\"%zu\"/>\n"
"<total type=\"rest\" count=\"%zu\" size=\"%zu\"/>\n"
"<total type=\"mmap\" count=\"%d\" size=\"%zu\"/>\n"
"<system type=\"current\" size=\"%zu\"/>\n"
"<system type=\"max\" size=\"%zu\"/>\n"
"<aspace type=\"total\" size=\"%zu\"/>\n"
"<aspace type=\"mprotect\" size=\"%zu\"/>\n"
"</malloc>\n",
total_nfastblocks, total_fastavail, total_nblocks, total_avail,
mp_.n_mmaps, mp_.mmapped_mem,
total_system, total_max_system,
total_aspace, total_aspace_mprotect);この901ブロックは15GB以上のメモリを占めています。そして、全体的な統計は私たちが見てきたものと一致しています:
<total type="fast" count="551" size="35024"/>
<total type="rest" count="511290" size="137157559274"/>
<total type="mmap" count="12" size="963153920"/>
<system type="current" size="139098812416"/>
<system type="max" size="197709660160"/>
<aspace type="total" size="139098812416"/>
<aspace type="mprotect" size="140098441216"/>はい、137GBのシステムに戻されていないフリーメモリーです。なんて貪欲なヤツだ!
(一時的な) fix
この段階で、glibcのメーリングリストに問題を投稿しました。私たちはもしこれがglibcアロケーターの問題であることが確認された場合、どのような情報であってもよろこんで提供します(この記事を書いている時点ではまだ新しい有益な情報は得られておりません)
その間に GLIBC_TUNABLES 機能 (主に glibc.malloc.trim_threshold と glibc.malloc.mmap_threshold)を使って内部的なチューニングを試みましたが上手くいきませんでした。私たちはまた新機能であるスレッドキャッシュ(glibc.malloc.tcache_count=0)を無効にしてみましたが、スレッドごとのキャッシュの割り当ては小さい(ほとんと数百バイト程度)ブロックでしかありませんでした。
ここからは、いくつかの選択肢を想定しながら進めていきました。
ガベージコレクター
malloc_trim を定期的に呼び出すのはダーティーな一時しのぎ的なハックかもしれませんが、いい感じに動いているようには見えます。その時によって数秒から5分程度実行に時間がかかるようです:
{
"periodMs": 300000,
"elapsedMs": 1973,
"message": "Purged memory successfully",
"rss.before": 57545375744,
"rss.after": 20190265344,
"rss.diff": -37355110400
}更にGCにかかる時間は溜まったフリースペースの量に応じてリニアに増えているようです。該当期間を10で割ったものと、返却されたメモリとGCにかかる時間で割ったものは同様でした。
{
"periodMs": 30000,
"elapsedMs": 193,
"message": "Purged memory successfully",
"rss.before": 19379798016,
"rss.after": 15618609152,
"rss.diff": -3761188864,
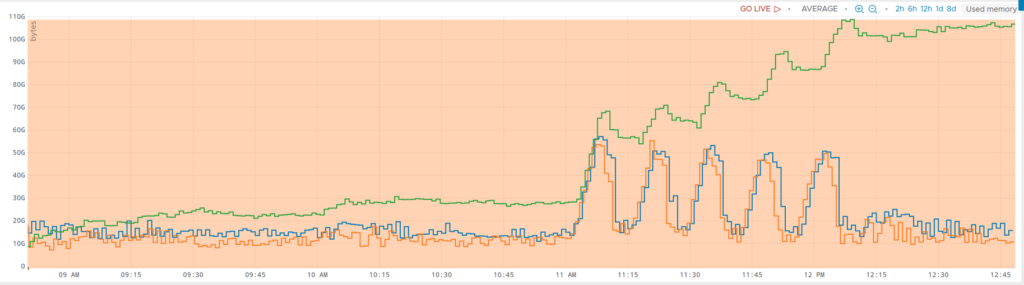
}このGC呼び出しによる効果は以下のグラフのように一目瞭然でした。

緑のグラフが新しいglibc、青が旧バージョン、オレンジが通常のGCを強制したglibcです。
最後に、一定量のメモリーを解放した際に、trimオペレーションをトリガーするようにオーバーライドさせるテストにも成功しました。
#include
#include
#if (!__has_feature(address_sanitizer))
static std::atomic freeSize = 0;
static std::size_t freeSizeThreshold = 1_Gi;
extern "C"
{
// Glibc "free" function
extern void __libc_free(void* ptr);
void free(void* ptr)
{
// If feature is enabled
if (freeSizeThreshold != 0) {
// Free block size
const size_t size = malloc_usable_size(ptr);
// Increment freeSize and get the result
const size_t totalSize = freeSize += size;
// Trigger compact
if (totalSize >= freeSizeThreshold) {
// Reset now before trim.
freeSize = 0;
// Trim
malloc_trim(0);
}
}
// Free pointer
__libc_free(ptr);
}
};
#endifこれらのテストは様々なワークロードでの動作を確認するために複数のクラスタにおいて実行されました。
では、GCのコストはどのようなものになるのでしょうか?CPUの利用率(特にsystem CPU usage)のメンテでは特にネガティブな影響は見受けられませんでした。そして、malloc_trim の実装を見ていくと、”big lock”モデルではなく、各アリーナがそれぞれ別々にロックされ、個別に解放されていくされているように見えます。
int
__malloc_trim (size_t s)
{
int result = 0;
if (__malloc_initialized < 0) ptmalloc_init (); mstate ar_ptr = &main_arena; do { __libc_lock_lock (ar_ptr->mutex);
result |= mtrim (ar_ptr, s);
__libc_lock_unlock (ar_ptr->mutex);
ar_ptr = ar_ptr->next;
}
while (ar_ptr != &main_arena);
return result;
}専用のアロケーター
異なるアロケーターの利用(jemallocやtcmallocを含む)は興味深い可能性の一つではありますが、とはいえ、全く異なるアロケーターのコードに移行するのにはいくつか欠点があると言えます。まず、セミプロダクションとプロダクションにおける長期間の検証が必要になってしまいます。そして何より、私たちの特定のアロケーションパターンが非常に特殊なものに該当することが想定されます(保証できると言っていいほど、時にとても奇妙なものがあるのです…)。また、あまり一般的でない C++ ライブラリ(llvmのlibc++)を作っていることもあり、そのようにあまり一般的ではないケースと更に一般的ではないアロケーターを組み合わせることで、プロダクションにおいて、また新たなパターンに遭遇する可能性も否定できません。そして、新しい、ということは、今まで誰も遭遇したこともないようなバグに出くわすという可能性があると言えるでしょう。
不具合調査
根底にある不具合はまだ明らかではありません。
Arena leak
2013年に埋め込まれたバグである、malloc/free can’t give the memory back to kernel when main_arena is discontinuous (malloc/freeはmain_arenaが途切れる場合にメモリをカーネルに戻すことが出来ない)については、私たちが直面している問題に近いようではあるものの、私たちのシステムにとって特に新しいものというわけではなく、glibc 2.23において malloc_trim でメモリを戻すようになったにも関わらず、現在の私たちが抱える問題の大きさとしては前代未聞のものと言えるかと思います。このバグは未だペンディング状態で、恐らくcorner-cases(一部の特定のケース)にのみインパクトがあるものと思われます。
Number of arenas
アリーナ数の増加も可能性の一つであるかもしれません。2.23の57アリーナから2.31の96アリーナまで、同じハードウェアおよび環境でその数は増加しています。これは注視すべき増加であると言えるかもしれないものの、問題の規模の大きさからすると、ここでもこれがトリガーになっているとは考えにくいと思います。Alex Reeceは Arena “leak” in glibc についてのブログ記事の中で、glibc.malloc.arena_max を使ってアリーナの数をコアの数に減らすというチューニングの提案をしています。これは、プロセスがコアの数よりもスレッドを使っていない場合(私たちのケースはこれに該当します)には有効であると言え、理論的には無駄なメモリの問題を軽減できそうでしたが、残念ながらそうはなりませんでした: 96から12に(アリーナの数が)減っても問題は解決しませんでした:
1まで減らしても(これが実際のmainsbrk() arena):

Arenaのしきい値
興味深いことに、拡大する各アリーナはしばらくすると拡大が止まり、プロセス履歴の最大割り当てメモリが上限になります。free-but-not-releasedなブロックは巨大になることがあり(ギガバイト級)、これらのブロックはmmpapで提供されることになるので、むしろ驚くべきことであると言えます。
To be continued
私たちは様々なシナリオで試し続け、理想的には、根本的な原因を突き止めてそのFIXを行えるように再現ケースを早く掴みたいと思っていますが、それまでの間はワークアラウンド(GCスレッド的なもの)を用いますが、それは完璧と言えるものではないものの前に進むことは出来るでしょう。
The takeaway
オペレーティングシステムおよびライブラリのアップグレーには、見落とされてしまいがちな潜在的なインパクトがしばしば発生します。リスクを回避するには様々なコンポーネント(例えば、kernelやライブラリの最新化)のアップグレードを一定期間をかけながらそれぞれ一つ一つ行っていき、性能の劣化(メモリやCPUの使用量、ふるまいの変化、不安定な部分など…)の検出に十分な時間をかけるといったことが挙げられるかと思います。そして、定期的なアップグレードを行うことも助けになるかもしれません(1度に2つのシステムをリリースするのは恐らく安全なやり方ではありません)。最後に、ローリングアップグレードを実施し、収集を行ったメトリクスのセットを注意深く見ることは、ヘルシーなプロダクション環境を維持するためのプロセスの一部と言えるでしょう。私たちはこのことを学び、今後のプロセスにこの教訓を活かしていきたいと考えています。
何かご質問がある場合、もしくは、同じような経験をされている方は @algolia までお願いします。
コメント