最近Elasticsearchそのものをあまり触っていなかったので、勘が鈍るとアレなので久しぶりに。
Elasticsearch2.3.1(2016年4月8日現在の最新)をダウンロードします。
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
unzipして解凍したディレクトリに移動します。
$ unzip elasticsearch-2.3.1.zip Archive: elasticsearch-2.3.1.zip creating: elasticsearch-2.3.1/ inflating: elasticsearch-2.3.1/LICENSE.txt inflating: elasticsearch-2.3.1/NOTICE.txt creating: elasticsearch-2.3.1/modules/ 〜略〜 $ cd elasticsearch-2.3.1
Japanese (kuromoji) Analysis Pluginをインストールします。
bin/pluginって叩くと、pluginsってディレクトリを作ってそこに入れてくれる感じ。
Elasticsearch 2.0からKuromojiは”Core Elasticsearch Plugins”ってヤツに入ってインストールがより簡単になりました。
その辺の話は↓こちら
https://www.elastic.co/guide/en/elasticsearch/plugins/current/installation.html
$ bin/plugin install analysis-kuromoji -> Installing analysis-kuromoji... Plugins directory [『ES_HOME』/plugins] does not exist. Creating... Trying https://download.elastic.co/elasticsearch/release/org/elasticsearch/plugin/analysis-kuromoji/2.3.1/analysis-kuromoji-2.3.1.zip ... Downloading ..................... .................................DONE Verifying https://download.elastic.co/elasticsearch/release/org/elasticsearch/plugin/analysis-kuromoji/2.3.1/analysis-kuromoji-2.3.1.zip checksums if available ... Downloading .DONE Installed analysis-kuromoji into 『ES_HOME』/plugins/analysis-kuromoji
イロイロとオペレーションをするのに、コンソールでガツガツ書くと辛いのでSenseをインストールします。
まず、Senseを動かすためにKibanaをダウンロートします。
Elasticsearch2.0からSenseはオープンソースになってKibanaのアプリとなっています。(以前はMarvel内のコンポーネントでした。)
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
解凍後にKibanaのディレクトリに移動します。
$ tar xvf kibana-4.5.0-darwin-x64.tar.gz x kibana-4.5.0-darwin-x64/ x kibana-4.5.0-darwin-x64/LICENSE.txt x kibana-4.5.0-darwin-x64/README.txt x kibana-4.5.0-darwin-x64/bin/ x kibana-4.5.0-darwin-x64/config/ 〜略〜 $ cd kibana-4.5.0-darwin-x64
KibanaにSenseをインストールします。
$ bin/kibana plugin --install elastic/sense Installing sense Attempting to transfer from https://download.elastic.co/elastic/sense/sense-latest.tar.gz Transferring 1352402 bytes.................... Transfer complete Extracting plugin archive Extraction complete Optimizing and caching browser bundles... Plugin installation complete
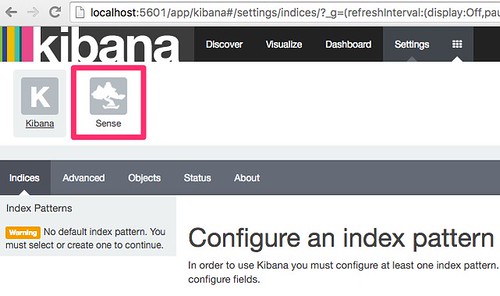
Kibanaの画面でSenseを選ぶと、
 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
馴染みのある画面が 🙂
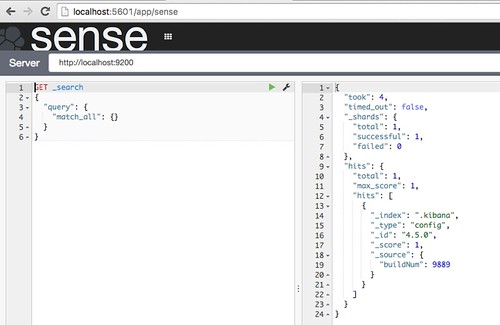 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
ということで、環境は整ったので日本語でanalyzeしてみます。
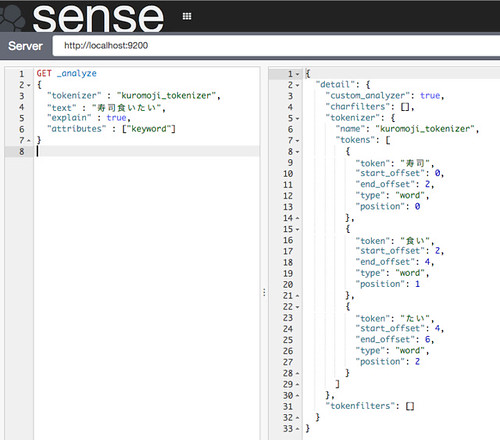 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
次にシノニム展開。寿司と言ったらシースーとか。。
$ cat config/synonym.txt 寿司,シースー
ってことで、Index作ります。Kuromojiで形態素解析して↑でシノニム展開する、と。
とりあえずインデックス作って、kuromoji_tokenizer&シノニムなヤツを。
PUT test
{
"index":{
"analysis" : {
"analyzer" : {
"kuromoji" : {
"tokenizer" : "kuromoji_tokenizer",
"filter" : ["synonym"]
}
},
"filter" : {
"synonym" : {
"type" : "synonym",
"synonyms_path" : "synonym.txt"
}
}
}
}
}
_analyzeでexplainをtrueにしてやると、イイ感じに動いてそうです。
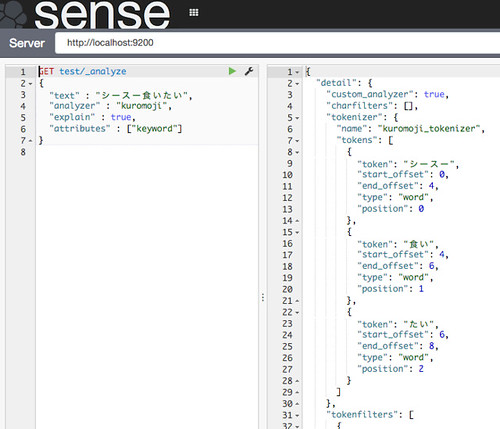 //embedr.flickr.com/assets/client-code.js
//embedr.flickr.com/assets/client-code.js
それっぽくsynonym展開も出来てそうです。
"name": "synonym",
"tokens": [
{
"token": "シースー",
"start_offset": 0,
"end_offset": 4,
"type": "word",
"position": 0
},
{
"token": "寿司",
"start_offset": 0,
"end_offset": 4,
"type": "SYNONYM",
"position": 0
},
シノニムだけでなく、形態素解析の辞書にも手を入れたくなってきました。
例えば、”きゃりーぱみゅぱみゅとシースーにいきたい”みたいな文章があってもちゃんと検索したいよね、と。
何もしないと”きゃりーぱみゅぱみゅ”は以下のようにトークナイズされます。
"tokenizer": {
"name": "kuromoji_tokenizer",
"tokens": [
{
"token": "きゃ",
"start_offset": 0,
"end_offset": 2,
"type": "word",
"position": 0
},
{
"token": "り",
"start_offset": 2,
"end_offset": 3,
"type": "word",
"position": 1
},
{
"token": "ー",
"start_offset": 3,
"end_offset": 4,
"type": "word",
"position": 2
},
{
"token": "ぱみゅぱみゅ",
"start_offset": 4,
"end_offset": 10,
"type": "word",
"position": 3
}
]
},
形態素解析の辞書に↓を加えて、
$ cat config/userdict_ja.txt きゃりーぱみゅぱみゅ,きゃりーぱみゅぱみゅ,キャリーパミュパミュ,カスタム人名
DELETE testしてから↓を流します。変更内容としては以下2点です。
・tokenizerをkuromoji_user_dictという名前で外出しにして定義
・kuromoji_user_dictの設定の中でカスタム辞書(userdict_ja.txt)を定義
PUT test
{
"index":{
"analysis" : {
"analyzer" : {
"kuromoji" : {
"tokenizer" : "kuromoji_user_dict",
"filter" : ["synonym"]
}
},
"tokenizer" : {
"kuromoji_user_dict" : {
"type" : "kuromoji_tokenizer",
"user_dictionary" : "userdict_ja.txt"
}
},
"filter" : {
"synonym" : {
"type" : "synonym",
"synonyms_path" : "synonym.txt"
}
}
}
}
}
再度 _analyze 叩くと、
GET test/_analyze
{
"text" : "きゃりーぱみゅぱみゅとシースー食べる",
"analyzer" : "kuromoji",
"explain" : true,
"attributes" : ["keyword"]
}
↓狙ったようにイケました。この要領で辞書をホゲホゲしていけば、芸能人とギロッポンでシースーも夢ではない!(検索上は、、、w)
"tokens": [
{
"token": "きゃりーぱみゅぱみゅ",
"start_offset": 0,
"end_offset": 10,
"type": "word",
"position": 0
},
{
"token": "と",
"start_offset": 10,
"end_offset": 11,
"type": "word",
"position": 1
},
{
"token": "シースー",
"start_offset": 11,
"end_offset": 15,
"type": "word",
"position": 2
},
{
"token": "寿司",
"start_offset": 11,
"end_offset": 15,
"type": "SYNONYM",
"position": 2
},
{
"token": "食べる",
"start_offset": 15,
"end_offset": 18,
"type": "word",
"position": 3
}
]

技術評論社
売り上げランキング: 89,431

コメント