
AWS Summit Tokyoに行ってきました。
http://instagram.com/p/aMi85Qw6e1/
ココのところずっと追いかけてるプラットフォームなのでとても楽しみにしていたカンファレンス。
■ オープニングキーノート(基調講演)
諸事情で30分ほど遅れての到着になってしまって、エラい後ろの方の席になってしまったのですが、

AmazonのCTOのWerner Vogelsさんのキーノート・スピーチ。
AWSの事とかでググってるとよく辿り着く、ヘッドホンのシブい写真のブログの人。

色んな事例が矢継ぎ早に紹介されていきます。オバマの選挙戦のCTOがチョコっと出てきたり。
(ウルトラクイズに出てきました。こういうのがあるので気が抜けないw)
生命保険会社とか、ナスダックでS3に過去のデータを~とか。
そんな流れでFinCloud(Financial Cloud)。何日もかかっていたものが何時間で~とかって話はワクワクします。
Netflixは北米で夜のピーク時間帯のトラフィックの約30%が彼らのもので、ソレら全部がAWS上から~とか。
abcはリアルタイムコンテンツ配信してるとか。
日本の広告事例的に電通、Fringe81、FreakOutがスライドに出て来ました。
ゲストスピーカーによる事例紹介 その1
===
・日経新聞事例紹介 (小柳 建彦 (株式会社 日本経済新聞社 産業部編集委員)
HTML5でタブレットとスマホに最適化したウェブサイト。
ニュースサイトは何か起こるとスパイクするのでクラウドが使えるとナイス
⇒ AWS使うに至るまで3年かかった。
導入するのに懸念がセキュリティなのに、導入後はセキュリティの満足度が高い。
タンスに現金置いとくのと、銀行に置いとくのと、どっちがセキュアなのか?
===
医療、バイオテクノロジーゲノム解析といった分野。
iluminaはDNA系の膨大な処理をAWSで。
日本では東芝メディカル。医療用画像は高精細な画像。
個人情報だからキャットスキャンやMRIのデータを直接S3に暗号化して載せる。
SAP on AWS。
アンリツ(計測器メーカー)はより機敏性を高めるため。SAPのERP環境をAWSに完全移行。同時にグローバル展開。
ゲストスピーカーによる事例紹介 その2
===
・トヨタメディアサービス事例 藤原 靖久 (トヨタメディアサービス株式会社 専務取締役)
トヨタのB2C事業をやってる会社。
トヨタ方式
・Just IN Time。必要のないものは全て無駄
・自働化。不良品を絶対出さない
なぜソレが生まれたか?
⇒トヨタがベンチャー企業だった時の話。
トラックを沢山作って売れるだろうと思ったけど資金が。。銀行も融資してくれない。
銀行からは販売と製造わけてくれ。人員整理をしろ。そういう背景から。
(コレ知りませんでした…。そんな背景があったのですね。。)
『一番悪いのは頭で考えて何もしないこと。』
『KAIZENっていうのは毎日やること。』
===
HPCを日本でも提供開始。ハイパフォーマンス・コンピューティングが出来る。
HPCの事例。
Cycle Computingという会社。いかに不可能を可能にしてきたか。
固定化されたHPCクラスタは必要とするときに足りない。それ以外の時は大きすぎる。
knife node list | wc -l
10599
⇒最新のゴイスーなサーバー。
Cycle ComputingのシステムのVIEWはこれをイイ感じにPC上でトレース出来る感じ。
インスタンスの状況をみるのに解像度が高い必要があるのでRetinaディスプレイで。
HPCによって今まで39年かかっていた処理を11時間で50万円以下で。
今まで見つけることができなかった3つの化合物を発見。
■ Road To AWS -クラウドへの道-

ランチセッションということでANDERSENの青山店で取り扱ってる
サンドイッチランチボックス的な。美味しかったです!
Lunch session at #awssummit
Andersen(Bakery from Hiroshima) sandwich box is #yum
Andersen runs JEAN-PAUL HÉVIN JAPON! pic.twitter.com/exJkwVr144— Eiji Shinohara @ アルゴリア 🗾 (@shinodogg) June 5, 2013
アンデルセンは広島発のベーカリー。
ジャンポールエヴァンのビジネスはライセンス契約してアンデルセンが日本でやってる。
今までのアンデルセンの長い歴史。ISBNが~とか、店舗毎にルーターが~とか、VPNが~とか。
システム的に致命的だったところは、西日本と東日本でそれぞれ別々のメインフレームをもってた事。
・西日本 タカギベーカリー
・東日本 アンデルセン
マスタデータの管理もそれぞれでやっていた⇒外部の有識者を呼んで再構築。マスタ統合して一元管理。
今まで25時間かかってた原価処理⇒ノーチラス・テクノロジーズのHadoop技術を使って今は40分くらい。
(クラスタ立ち上げとかで20分くらいだから実質20分くらい)
日立のデータセンター&AWSなハイブリッドな構成。Hadoop処理はAsakusaフレームワークを利用。
ApacheHadoopからAWSのEMRに移行したけど、コレといって困ったことは無かった。
EDIのAWS移行。サイトロックに24時間ガッツリ監視運用を依頼。
トラブルは今まで2回くらい。S3絡みで。
運用のポイントとしては、処理速度に劣化が出てきた時に、どういう条件で別AZに切り替えるか〜とか。
イントラマートとかワークスアプリケーションズのソフトもAWSに。
■ AWSをフルに活用しながら、あんしんできるセキュアなクラウド利用法とは?

最近はApacheがかなり狙われている。改ざん、情報漏えい。
不正なApacheモジュールが埋め込まれたり、不正プログラムをダウンロードさせたり。
⇒サイト管理者からすれば、被害者のはずが加害者に。xx.so置かれて、conf書き換えられて(LoadModule)、、的な。
セキュリティ的な何かを入れるのにゲートウェイ型とホスト型どっちがイイ?
⇒スケールって観点で見るとホスト型の方がよさそう。
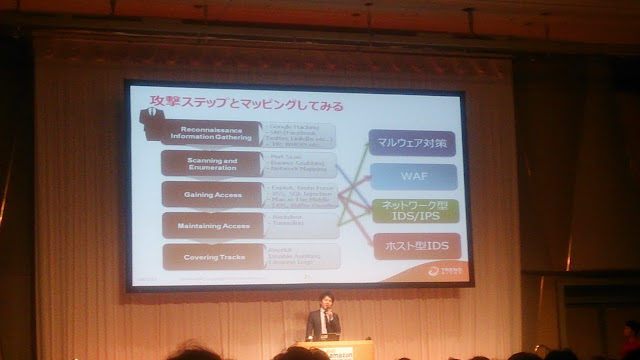
マルウェア対策、WAF、ネットワーク型IDS/IPS、ホスト型IDS
・マルウェア
特に言及なし。みんなのPCにも入ってるでしょ
・WAF
SaaS型。DNS変更して実現。Scutumが有名
ネットワーク型。AMI化されてるのもある。F5が有名。
ホスト型。mod_security。IPAのウェブサーバーもコレ使って守ってるらしい。PDF資料もあり。
・ネットワーク型IDS/IPS
ネットワークのパケットを監視するためのもの。SNORT、Check Pointも仮想アプライアンス型でAWS用に。
・ホスト型IDS
Webサーバーの中で予兆を検知。整合性監視。
ハッシュの値をとって、書き換えられたら通知飛ぶ、とか。tripwire、OSSEC(Trendmicroがライセンスを持ってる)
ログの中身をモニタリング。
攻撃ステップとマッピング。
情報集め段階
↓
ポートスキャンしたり、ミドルウエア確認したり
↓
アタック
↓
自分が入った事を気付かれないように
ログファイルから自分のやったことの痕跡を消したり
で、トータルなソリューションは??⇒Trend Micro Deep Security。
Management ConsoleとTrendmicroの管理コンソールが同期してて使いやすい。
Deep SecurityのインストールはRPMで入れるだけ。プロセス立ち上がってればOK。
#このプロセスの監視とかはしなくてもイイのでしょうかね…?
管理画面からポチポチやればそれで終わり。パッチを今すぐにあてるって厳しいのでNWなIDS/IPS。
Deep Securityはサーバーにどんなミドルウェアがどんな感じで入ってるか?ってのをディテクトして、
ソレ用のルールの定義を自動的にやってくれる。
#Nginxとかも対応してるのかな?マニアックなミドルウエアとかどうなんだろう、とか。
リクルートライフスタイル社からはオートスケールといったところを評価されている。
トレンドマイクロのエンジニアが直接入ってプロジェクトに入ってサポートしてくれるオプションもある。
■ 【上級者向け】ハイブリッド構成を支えるAWSテクノロジー

ハイブリッド。ぜーんぶAWSじゃ出来ないこともある。
既存のアセットを最大限に活かして。
開発から大体クラウド⇒会場で開発環境AWSで本番はオンプレミスって人はほとんどいなかった。
環境間の~:データ持ち運び / 再現性(同じこと出来なきゃだめ) / データの同期
アクセスが跳ね上がってきた時だけ:レイテンシ
バッチ処理が溜まってきた時だけ:帯域
⇒オンプレミスとAWSが1つのシステムとして動く
・移行とバックアップ
ネットワークをどのように細かく分離するか?
VPCの癖:ELB。VPCの中のサブネット。1000個のIPが勝手にELBに食われてく。RDS、Elasticache。
IPアドレスが勝手食われてく~ってならないように、ELB、RDS、Elasticache用のサブネット。
/22や/24などわかりやすく大きめに。
API使用時のエンドポイント。パブリックIPに対するアクセス。
EIP、NATインスタンス、オンプレのインターネット線。
AWSのリソースは原則ホスト名を使ってアクセス
Direct Connect。DC、オフィス、コロケーション環境間を専用線で。
・ファイルのコピー
S3のスケーラビリティを活かす使い方が出来ているか?
マルチパートのアップロード機能があるので数十MB超えるのであれば。並列転送して後からガッチャンコ。
ディレクトリ名とファイル名を分散化。特に頭の3文字〜4文字をランダムに。
コレでパフォーマンスあがる(S3を公平に使っていただくため、そういう仕様になってる)。
都度都度listを叩くのとかは止めた方がイイ。
もしrsync使いたい~とかだったら、、EC2にしたらイイ。
高速なネットワーク転送に関してはTsunami-UDP, Aspera, Skeedとかってのがそういうソリューション。
・ブロックデバイスにコピー
AWS Storage Gateway。キャッシュ型をサポート。i-SCSIにしておけばいつの間にかコピーが出来てる風。
DRBD。高遅延、低速度の場合はDRBD Proxy。Storage Gatewayアツい。
・Virtual Machineそのものを。
VMのImport/Export。
・データベースの同期
DB止めてもイイとか、書いたものは全てディスクに書かれている~とかだったらイイけど、
データベースの場合はそうもいかないはず。
東海岸と西海岸でレプリケーションとか。
データ圧縮 / 重複排除 / TCP最適化 / 伝送路暗号化
⇒DBのレプリケーションでコレらを満たしてるのは無い。
マーケットプレースに2つサービスがある。
CloudOptは9001ポートを使ったトンネル技術。高速で安心にデータを転送。
・運用支援サービス
IAMをハイブリッドで使う例。
IAMを使うと権限管理が出来る。管理者 / 開発 / 運用 とか。
ActiveDirectoryとかLDAPとかのシングルサインオンの環境がある。
⇒IAMのSecirity Token Service(STS)。60分〜最長72時間までテンポラリで使えるトークン。
・VPCによるSTG環境テスト
IPアドレス以外は本番と全く同じでOK。
DNS(Route53)では重み付けしてトラフィックを制御することができる。
■ 【上級者向け】基幹業務をAWSクラウドで実現する勘所 ~ 高可用性システム/バックアップのためのアーキテクチャ設計 ~

99.99以上の可用性持たせようとすると電源等のファシリティから考えないといけなくなる。
・予備部品への自働化
・予備への切換の自働化
ストレージレイヤでの冗長性がポイント。
ハードウエアレベルでの仮想化。
ハイパーバイザーを利用したインフラの共有利用。仮想レイヤでのHA。
・ネットワークレイヤー
フルマネージド。冗長化されたInternet回線、内部NWの冗長化⇒IPのレンジどうするか?とかくらい。
・ハイブリッド環境での冗長化
Direct Conectでの回線冗長化
VPN接続サービスでのコネクション冗長化
専用線&VPNでのルーティングレベルでの冗長化
・Front End
Load Balancer。ELBは自動スケールする。障害検知すると自分自身で復旧。
マルチAZ構成でELBも冗長化。
商用プロダクトももちろん使用可能。
Route53をうまいこと使って負荷分散とかも。

・Back End
EC2はstop/startするだけで別HWに即時移動。EC2 status checkや監視SWと連動して~。
heartbeat, pacemaker, DRBD,,とか。AWSのAPIを駆使してもOK。
ミドルウエアでMySQLクラスタとか、Oracle DataGuard, SQL Server Repolicationとか。
・ストレージレイヤ
プロビジョンされるときに冗長化されるので気にする事ないけど、
Software Raidの併用も。snapshotとか。
・バックアップのレイヤ
スナップショット⇒S3へ。イレブン9の堅牢性。
・データセンターでの可用性
マルチアベイラビリティーゾーン
EC2, RDS, ELB, VPC, S3は対応してる
マルチリージョンという選択肢も。
・バックエンドのHAクラスタ
シングルAZでやるかマルチAZでやるか。
AWSではNICは仮想NICなので複数使わなくてもOK
OSとENIの両方で指定が必要。
EC2インスタンスのstart/stopは同一AZ内だけ。EBSも同様。
AZをまたいだサブネットというのは作れない。
インスタンスの種類によって立ち上がる時間が変わってきたりする。
ENIとEBSの付け替えはそれぞれ1分くらいなので、start/stopより劇的に早いわけでもない。
ENIのSecondary IP(VIP)の移動
マルチAZでのHAクラスタ
・Private IPアドレスが変わる。
内部DNSを立てちゃう。MyDNSで⇒で、それのHAどうする?って話も…
VPCのSubnet Route Tablesの書き換え。実現は簡単だけど初期設定が。。
・バックアップ
如何に楽してS3に格納するか。
S3に置くだけでISMSの認証がとれたーとかって話もあるらしい。
fluentdとかS3 toolsとか、、NASのアプライアンスとか、、アーカイブはグレーシアとか。
– インターネットでS3の通信は全てSSL
– Internet VPN⇒Proxy⇒S3(ネット上にあるので)
– 専用線(Direct Connect)。ASの種類による。Public ASなら直。Private ASならVPC経由で。
– AWS Import/Exportは東京でサービス提供してないけど、ベンダーさんでそういうのやってるとこある。
AWS上でもいろんなベンダーのいろんなサービスを使う事が可能。
■ 【上級者向け】AWSクラウドで構築する、ワールドクラスの分散クラウドアーキテクチャ

・リージョン:世界8箇所+米国政府用
・アベイラビリティーゾーン:各リージョンの中に2~3箇所
数ミリ秒くらいの遅延でデータセンター間を。AWSではマルチAZ推し

・マルチリージョンの難しさ
AWSのビルディングブロックでカバーしてないところをお客さんが自前で。
距離があるところでの分散システムってのは難しい
ユーザーエクスペリエンスの向上:
地理的に離れたお客様からのアクセス。静的コンテンツはCloudFrontとかできるけど、動的となると、、
データセンターのソリューション(Tsunami, Skeed, Aspera, CloudOpt)
データのリージョン間での受け渡し。S3+SQSで非同期通信とか。
SNS+SQSでPub/Subとか。
ディザスタリカバリ:
RTO, RPO,,,
Route53なら重み付けで割り振ったり。
高可用性:
NASAはGlusterFS
NetflixはUSの西東とヨーロッパ
- CAP定理:
C:一貫性、A:可用性、P:ネットワークの分断を分散システムでは同時に3つ獲得出来ない
どこかでネットワークが疎通できなかった時にサービスが維持できるか。
一貫性を落とすか、可用性を落とすかの選択になる。
CとAを目指すのはRDBMSの思想。
- 合意プロトコル:
分散システム内で合意が必要な例
PaxosとかZookeeper。リーダー/マスター選定、分散ロック
- 耐障害性の維持:
アメリカの東と西は70〜80ミリ秒。非同期なレプリケーションが必要。
NASAの場合はマスタースレーブな非同期のレプリケーション。
Netflixの場合はクオラム+Geo-Replicationという形のトランザクション。
なんかあった時にレプリケーションしないように的な。
物理制約を考慮する(光の速度は超えられない)
複合障害の伝搬。サーキットブレーカー。
テストどーやんの?⇒GameDay。本番環境でテストしましょう。
Jesse RobbinsというOpsWorksの創始者がAmazonにいたときに考えだしたもの。
Amazonは運用主体なカルチャー。
リカバリーオリエンテッドコンピューティングパターン
ボーアバグ:再現可能なソフトバグで補番ではレア
ハイゼンバグ:通常ではありえない複数のリクエストやココに独立した、、調査しようとしても再現できない。。。
なんでマルチAZなのか?ってのが腹落ちするセッションでした。
■ 【上級者向け】PaaS on AWS ~ プラットフォームサービスon AWSの利点 ~

会場でPaaS使った事ある人が30%くらい。
Heroku, EngineYard, ElasticBeanstalk。
どれを使うべきなのか?⇒場合による。
・ElasticBeanstalkの論理構成
Application
Configuration Template: 環境とそれごとのレポジトリ。
環境
ELB、AutoScaling、RDS&CloudWatchという構成。必要があればイジれる。
無料試用枠でもやりくりできちゃうくらい。
育て方
MultiAZ化したり。豆の木的に。
事例
スポットライトのスマポ、Origami
・EngineYard
ダッシュボード使ってる分には裏側は知らなくてもOKになってる。
ワンクリックで出来上がるのはAWS的には一般的な構成。
Nginxの静的コンテンツの圧縮とかイロイロ最適化されてる。EY製オレ流ベストプラクティス。
EC2インスタンスとしてはシングルテナントなので自分の欲しいタイミングでミドルウエアのVUPとか。
SSHでアクセスできる。
VirtualboxでローカルにEngineYardの環境を作って開発してクラウド上にデプロイできる
・Heroku
PaaSといった時に思い浮かべるのはHeroku。読み方は公式見解として”ヘロク”。
Dynoという概念。Ubuntu10.04でコンパイル出来る言語はHerokuで動く。
オートスケールなアドオンとかもある。
・EngineYardは運用サポートが手厚い。
元々AWSオリエンテッドな感じではじまってるわけじゃないから他でも動くように。
PaaSの作り的には1回ラップして抽象化してから。ELBでもHAProxyでも使える。
閉域網的なこともTerremarkだとファイアーウォールの中でVPN接続とか。
EngineYardは非常にオープン。プルリクも出来るし。参加して欲しい。
・HerokuはDynoという概念が画期的。
Dynoがあるので実現できるマルチテナント。
アプリそのものを動かすことに価値はなくて、スケールとかサードパーティーと繋ぐとか。
Heroku+SalesForceでエンプラが非常に短い期間で実装されている。
・BeanstalkはAWSユーザーにとってはイイ。
PaaSという側面は強くない。特に使うのにお金かからない。EC2の稼働で課金とか。
・PaaS
インフラにかかるコストっていうより、インフラエンジニアにかかるコスト。
⇒インフラエンジニアはPaaSのベンダーに就職した方がイイ

—
物凄い混雑の中、PCの充電との戦いで、クッタクタになりましたが、
丸一日ガッツリAWS漬けになれて良かったです。
いやー、ごっついプラットフォームですわ。。
こないだ行ったOracle Cloudworldとの比較とかしても面白いかな。。
2日目に続きます。

日経BP社
売り上げランキング: 6,965

日経BP社
売り上げランキング: 10,845


コメント